В данной статье рассмотрен пример создание парсера, для сбора информации с lite версии поисковика Яндекс.
Не так давно, один из ключевых разработчиков и руководителей Яндекса Виталий Харисов, в своей лекции под названием «10к» рассказал о лёгкой версии поиска для медленных соединений и способы оптимизации кода, позволяющие уложиться в 10 килобайт. Суть сводилась к тому, что на основании доклада под названием «10к», который был составлен компанией Microsoft возникла идея создания версии сайта, для устройств на которых по разным причинам используется медленное соединение сети интернет.
Код HTML, который получает пользователь, согласно условиям, должен составлять, порядка 14 Кб. Это максимальный лимит, установленный для легкой версии. Для просмотра lite версии, в адресную строку браузера нужно добавить параметр lite. Подробности здесь.
Учитывая вышесказанное, появилась идея протестировать данную версию сайта с помощью нашего парсера. Для этого мы напишем JS парсер lite выдачи и сравним его производительность со стандартным. Для облегчения задачи и исключения влияния сторонних сервисов мы не будем использовать антигейт.
Написание парсера
Для написания парсера проведем анализ выдачи lite версии Яндекс. Переходим по ссылке https://yandex.ua/search/?text=тест&lite=1. Мы видим обычную выдачу яндекса, только параметр lite в строке браузера говорит нам про то, что мы попали на «легкую» версию. Для просмотра дополнительных параметров воспользуемся «расширенным поиском».

Здесь мы видим дополнительные параметры, которые можно задавать для поиска, для нас важно, что все они передаются через указание в строке запросов браузера. Выберем для себя следующие:
С параметрами, пожалуй, достаточно, определим набор переменных, которые будем выводить в результаты парсинга. Сделаем вывод максимально приближенным к стандартному Яндекс парсеру. Определим следующие параметры:
Используя возможности JS в парсере, пишем код для получения необходимых данных.
Формируем ссылку для GET-запроса
Запрос
Получаем значение общего количества результатов
Получаем значение в массив serp (линки, анкоры, сниппеты)
Получаем значение в массив связанных ключевых слов $releted
В результате получаем готовое решение, которое будет иметь следующий интерфейс:
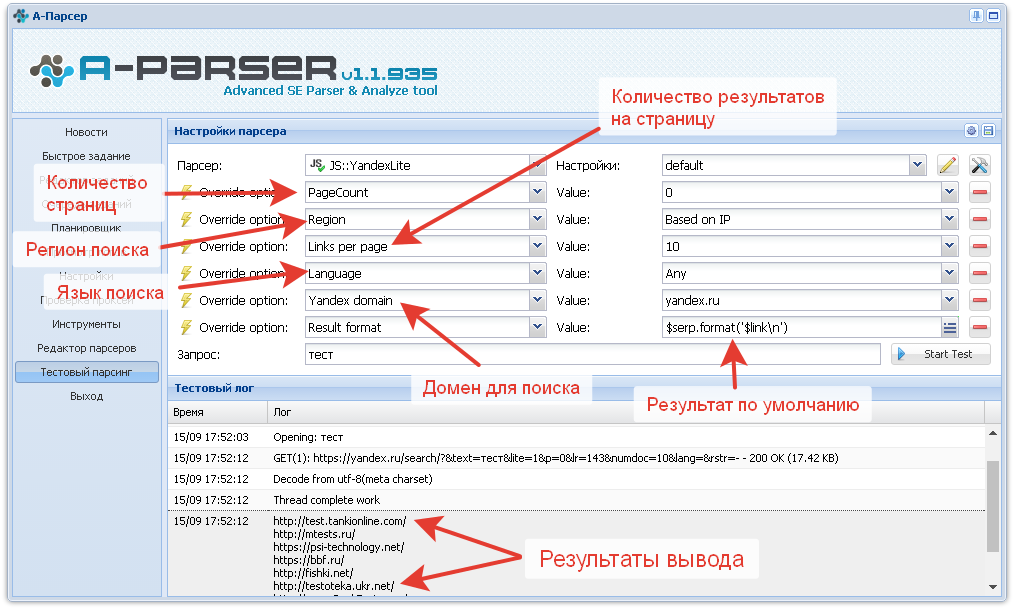
Парсер доступен для загрузки в каталоге на нашем сайте: https://a-parser.com/resources/225/
Анализ
Протестировав созданный парсер со стандартным Яндекс, следует отметить следующие моменты:

Было предположение, что капчи на этой версии не будут появляться так часто, как в стандартной версии Яндекса – увы предположение не подтвердилось.
Итог
Проанализировав и протестировав на реальных примерах выдачу lite версии можно уверено сказать, что она практически не отличается от стандартной выдачи. В то же время lite версия не имеет преимуществ по скорости работы и так, как и стандартная версия имеет защиту от парсинга в виде капч, которые появляются примерно с такой же регулярностью, как и в стандартной версии.
Учитывая полученные результаты, можно сделать вывод, что обе выдачи Яндекса имеют примерно одинаковые характеристики, поэтому lite выдача будет полезна исключительно для пользователей с медленным инетом.
Не так давно, один из ключевых разработчиков и руководителей Яндекса Виталий Харисов, в своей лекции под названием «10к» рассказал о лёгкой версии поиска для медленных соединений и способы оптимизации кода, позволяющие уложиться в 10 килобайт. Суть сводилась к тому, что на основании доклада под названием «10к», который был составлен компанией Microsoft возникла идея создания версии сайта, для устройств на которых по разным причинам используется медленное соединение сети интернет.
Код HTML, который получает пользователь, согласно условиям, должен составлять, порядка 14 Кб. Это максимальный лимит, установленный для легкой версии. Для просмотра lite версии, в адресную строку браузера нужно добавить параметр lite. Подробности здесь.
Учитывая вышесказанное, появилась идея протестировать данную версию сайта с помощью нашего парсера. Для этого мы напишем JS парсер lite выдачи и сравним его производительность со стандартным. Для облегчения задачи и исключения влияния сторонних сервисов мы не будем использовать антигейт.
Написание парсера
Для написания парсера проведем анализ выдачи lite версии Яндекс. Переходим по ссылке https://yandex.ua/search/?text=тест&lite=1. Мы видим обычную выдачу яндекса, только параметр lite в строке браузера говорит нам про то, что мы попали на «легкую» версию. Для просмотра дополнительных параметров воспользуемся «расширенным поиском».
Здесь мы видим дополнительные параметры, которые можно задавать для поиска, для нас важно, что все они передаются через указание в строке запросов браузера. Выберем для себя следующие:
- Указание региона для поиска (установим, как Region);
- Язык поиска (установим, как Language);
- Количество результатов вывода на страницу (установим, как Links per page);
- Количество страниц поиска (установим, как PageCount);
Код:
this.editableConf = [
['page_count', ['combobox', 'PageCount', ['1', '1'], ['2', '2'], ['3', '3'], ['4', '4'], ['5', '5'], ['6', '6'], ['7', '7'], ['8', '8'], ['9', '9'], ['10', '10']]],
['str', ['combobox', 'Region'].concat([['', 'Based on IP']], tools.data.YandexWordStatRegions.map(
(el) => [el[1], el[0]]
))],
['linksperpage',
['combobox', 'Links per page',
[10, '10'],
[20, '20'],
[30, '30'],
[50, '50'],
],
],
['lang',
['combobox', 'Language',
['', 'Any'],
['ru', 'Russian'],
['en', 'English'],
['be', 'Belorussian'],
['fr', 'French'],
['de', 'German'],
['id', 'Indonesian'],
['kk', 'Kazakh'],
['tt', 'Tatar'],
['tr', 'Turkish'],
['uk', 'Ukrainian'],
],
],
['domain',
['combobox', 'Yandex domain',
['yandex.ru', 'yandex.ru'],
['yandex.ua', 'yandex.ua'],
['yandex.by', 'yandex.by'],
['yandex.kz', 'yandex.kz'],
['yandex.com.tr', 'yandex.com.tr'],
['yandex.com', 'yandex.com'],
],
],
];- Массив «Results array» который будет содержать набор анкоров, линков и сниппетов (установим, как $serp);
- Массив «Releted array» который будет содержать список ключевых слов поиска (установим, как $ reletead);
- Сделаем вывод общего количества результатов «TotalCount» (установим, как $ totalcount);
Код:
results: {
flat: [
['totalcount', 'TotalCount']
],
arrays: {
serp: ['Results array', [['anchor', 'Anchor'], ['link', 'Link'], ['snippet', 'Snippet']]],
releted: ['Releted array', [['releted', 'Releted']]],
}
}
Код:
let link = 'https://' + this.conf.domain + '/search/?&text=' + set.query + '&lite=1&p=' + i +'&lr=143&numdoc=' + this.conf.linksperpage +'&lang=' + this.conf.lang + '&rstr=-' + this.conf.str;
Код:
let response = yield this.request('GET', link, {}, {
decode: 'auto-html',
});
Код:
let totalcountMatchContainer = response.data.match(/<div class="serp-adv__found.+?>(.+?)<\/div>/i);
if (totalcountMatchContainer) {
let totalcountMatch = /(\d+)(?!.*\d).(млн|тыс|тис|million|thousand|milyon|bin)?/.exec(totalcountMatchContainer);
if (totalcountMatch) {
let mult = 1;
switch (totalcountMatch[2]) {
case 'млн':
case 'million':
case 'milyon':
mult = 1000 * 1000;
break;
case 'тыс':
case 'тис':
case 'thousand':
case 'bin':
mult = 1000;
break;
}
results.totalcount = parseInt(totalcountMatch[1]) * mult;
}
}
Код:
let regexp = /class="link serp-item__title-link".+?tabindex=2>(.+?)<\/a><\/h2>.+?href="(.+?)".+?<div class=serp-item__text>(.+?)<\/div>/g;
let match;
while (match = regexp.exec(response.data)) {
results.serp.push(match[1], match[2], match[3]);
}
Код:
let regreleted = /a class=link href="\/search.+?">(.+?)<\/a><\/div>/g;
let releted;
results.releted = [];
while ( releted = regreleted.exec(response.data)) {
results.releted.push(releted[1]);
}
}Парсер доступен для загрузки в каталоге на нашем сайте: https://a-parser.com/resources/225/
Анализ
Протестировав созданный парсер со стандартным Яндекс, следует отметить следующие моменты:
- По скорости работы парсеры показали приблизительно равное время. Следовательно, в независимости от выдачи время парсинга не уменьшилось.
- Результаты выдачи, практически не отличаются друг от друга. Вся информация, которая есть в стандартном парсере присутствует и в lite версии.
- Важно отметить, что при тестировании парсера, в связи с тем, что не было реализовано возможность обхода капч на lite версии, довольно часто результат получить на удавалось.
Было предположение, что капчи на этой версии не будут появляться так часто, как в стандартной версии Яндекса – увы предположение не подтвердилось.
Итог
Проанализировав и протестировав на реальных примерах выдачу lite версии можно уверено сказать, что она практически не отличается от стандартной выдачи. В то же время lite версия не имеет преимуществ по скорости работы и так, как и стандартная версия имеет защиту от парсинга в виде капч, которые появляются примерно с такой же регулярностью, как и в стандартной версии.
Учитывая полученные результаты, можно сделать вывод, что обе выдачи Яндекса имеют примерно одинаковые характеристики, поэтому lite выдача будет полезна исключительно для пользователей с медленным инетом.
