Possibilités illimitées avec A-Parser
Nous avons rassemblé tous les avantages sur une seule page ; des informations détaillées sur chaque fonctionnalité sont disponibles dans la documentation.
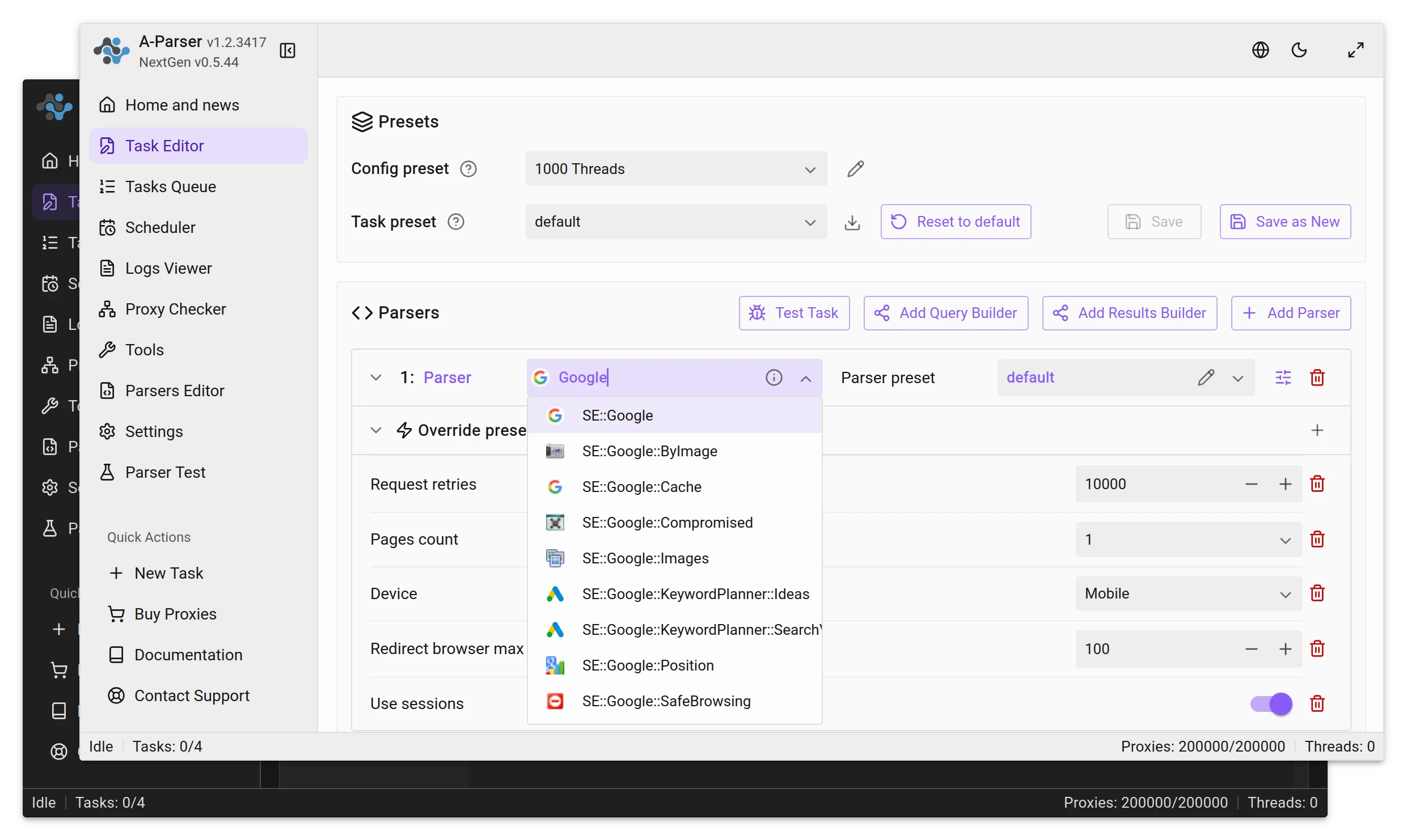
Éditeur de tâches
Utilisez jusqu'à 20 parseurs dans une seule tâche, en répartissant uniformément les threads pour réduire les blocages de proxy et augmenter la vitesse d'analyse.
De nombreux paramètres pour chaque parseur peuvent être enregistrés dans des préréglages séparés et réutilisés dans diverses tâches.
La séparation des données d'entrée vous permet de modifier le format de la requête et d'ajouter des données supplémentaires associées aux résultats.
Un format de requête distinct pour chaque parseur au sein d'une même tâche, avec un contrôle de l'ordre d'exécution du formatage.
Si vous n'êtes pas sûr des données d'entrée, A-Parser s'assure qu'aucun travail redondant n'est effectué.
Expansion automatique des requêtes, substitution de sous-requêtes à partir de fichiers, et itération sur des combinaisons alphanumériques et des listes.
Le puissant Template Toolkit vous permet d'appliquer une logique supplémentaire aux résultats et de générer les données dans divers formats, y compris JSON, SQL et CSV.
Des capacités de déduplication avancées garantissent l'unicité des chaînes, des liens et des domaines que vous recevez.
Sauvegardez uniquement les données qui répondent à vos critères : correspondances de sous-chaînes, comparaisons numériques ou expressions régulières.
Utilisez différents formats pour différents fichiers et appliquez des conditions et des filtres supplémentaires, le tout dans une seule tâche pour économiser les ressources d'analyse.
Un journal détaillé pour chaque thread et chaque requête permet un débogage rapide et pratique des tâches.
Étendez la logique d'A-Parser en exécutant automatiquement différentes tâches en séquence, en transmettant les résultats d'une tâche comme requêtes pour la suivante.
Vous construisez des bases de données à partir de plusieurs tâches ? La sauvegarde des bases de données de déduplication garantit que vous n'obtenez que des résultats uniques.
En exécutant chaque tâche avec un nombre de threads spécifié, vous pouvez vous assurer qu'A-Parser ne dépassera pas votre forfait proxy ou les ressources de votre serveur.
Utilisez le débogueur pour vérifier rapidement le fonctionnement d'une tâche lors de sa création, avec une exécution rapide et un affichage clair du journal.
File d'attente des tâches et planificateur
La file d'attente des tâches vous évite d'attendre la fin d'une tâche. Ajoutez un nombre illimité de tâches indépendantes.
Contrôlez le nombre de tâches exécutées simultanément, ce qui réduit considérablement le temps total pour obtenir des résultats.
Démarrez, mettez en pause, modifiez ou supprimez des tâches. Reprenez les tâches là où elles ont été interrompues ; A-Parser continuera de collecter des informations.
Avec une grande file d'attente de tâches, il est crucial de contrôler quelles tâches démarrent avant les autres.
Définissez une limite globale de threads pour toutes les tâches, et A-Parser distribuera automatiquement les threads entre les tâches actives.
Accédez à un historique complet des tâches terminées, consultez les statistiques et ajoutez à nouveau des tâches pour une nouvelle exécution.
Exécutez des tâches récurrentes à l'aide du planificateur de tâches avec des paramètres flexibles pour les intervalles de répétition.
Vérificateurs de proxies et gestion des proxies
A-Parser fonctionne avec tous les protocoles de proxies, et le vérificateur de proxies peut tester tous les types simultanément.
Ajoutez des vérificateurs de proxies distincts pour différentes sources de proxies, chacun avec ses propres paramètres de vérification.
Gérez le nombre de threads de vérification et de téléchargement séparément pour chaque vérificateur de proxies.
Spécifiez les identifiants d'accès aux proxies dans les paramètres du vérificateur de proxies ou dans les listes de proxies avec des données d'authentification distinctes.
A-Parser vérifie la prise en charge de la méthode POST par les proxies, leur anonymat, leur temps de réponse et d'autres paramètres.
Si vous êtes certain que vos proxies fonctionnent, vous pouvez désactiver la vérification pour économiser des ressources.
Pour chaque tâche, vous pouvez sélectionner des sources de proxies spécifiques, permettant une allocation flexible des ressources.
Pour encore plus de flexibilité, utilisez différents proxies au sein d'une même tâche, comme des proxies distincts pour les scrapers Google et Yandex.
Si un service bannit un proxy, A-Parser cessera de l'utiliser pendant une période spécifiée, réduisant ainsi les requêtes échouées.
Vous pouvez limiter le nombre maximal de threads par proxy pour éviter de surutiliser ses ressources.
Par défaut, A-Parser utilise un proxy unique pour chaque tentative de téléchargement de données, mais ce comportement peut être modifié.
Cette fonctionnalité vous permet d'exclure certains proxies de l'usage général et de les affecter uniquement à des tâches spécifiques.
Paramètres flexibles
Sauvegardez des groupes de paramètres dans différents préréglages et réutilisez-les dans diverses tâches.
Par exemple, le scraper Google permet de spécifier le nombre de pages, le nombre de résultats par page, les paramètres de langue, la géolocalisation et bien plus encore.
Exportez vos paramètres et parseurs pour les partager avec d'autres, ou importez des tâches prêtes à l'emploi depuis notre catalogue.
Multithreading et performance
A-Parser est construit sur une architecture entièrement asynchrone, capable d'exécuter jusqu'à 3 000 threads asynchrones simultanés.
A-Parser emploie de nombreuses optimisations pour de meilleures performances, et nous profilons et améliorons constamment notre code.
Il n'y a aucune limite au nombre de requêtes, à la taille des fichiers de requêtes ni au nombre de résultats.
La plupart des tâches s'exécutent sans problème sur n'importe quel ordinateur de bureau ou domestique standard, ainsi que sur n'importe quel VDS d'entrée de gamme.
Actuellement, A-Parser peut utiliser efficacement jusqu'à 4 cœurs de processeur. Une licence avec une prise en charge illimitée des cœurs sera bientôt disponible.
Reconnaissance des captchas
Les logiciels de reconnaissance de CAPTCHA les plus populaires prennent en charge de nombreux types de CAPTCHA, y compris reCAPTCHA v2.
Nous prenons en charge l'intégration avec une grande majorité de services, y compris Anti-Captcha, RuCaptcha, CapMonster.cloud, 2Captcha et d'autres.
La prise en charge de la reconnaissance des captchas est intégrée à tous les scrapers populaires. Vous pouvez également l'utiliser depuis vos propres scrapers JavaScript personnalisés.
Développement de préréglages basés sur les expressions régulières
Appliquez des expressions régulières aux données obtenues du scraper Net::HTTP ou du scraper HTML::LinkExtractor.
Collectez des points de données uniques dans des variables ou des blocs répétitifs (listes, tableaux). Affichez les données dans un format pratique à l'aide du moteur de modèles.
Vous pouvez appliquer un traitement supplémentaire aux données sources de tous les scrapers intégrés (par exemple, les résultats de recherche Google).
Utilisez des expressions régulières pour trouver des liens vers la page suivante de la pagination, et A-Parser naviguera automatiquement à travers toutes les pages.
Utilisez des expressions régulières pour valider le contenu, vérifier les blocages de proxies ou détecter les captchas. A-Parser réessaiera automatiquement avec un autre proxy en cas d'échec.
Avec le constructeur de résultats, vous pouvez effectuer des opérations de recherche et de remplacement à l'aide d'expressions régulières sur tous les résultats de scraping.
Développement de scrapers en JavaScript
Un code linéaire et synchrone utilisant async/await, qu'A-Parser exécutera dans un environnement multithreadé.
A-Parser vous permet de vous concentrer sur l'écriture du code d'extraction et de transformation des données, en prenant en charge automatiquement la gestion des proxies et des tentatives.
Écrivez en JavaScript moderne (ES2020+) ou utilisez TypeScript pour un typage fort et la coloration syntaxique.
Le vaste catalogue de modules NPMJS vous permet d'étendre sans limites les capacités d'extraction et de traitement des données d'A-Parser.
A-Parser ajoute la prise en charge des proxies à la populaire bibliothèque Puppeteer, permettant l'utilisation automatique de différents proxies pour différents onglets.
Vous pouvez envoyer des requêtes à n'importe quel scraper intégré ou à d'autres scrapers JavaScript, permettant ainsi de créer une logique aussi complexe que nécessaire.
Automatisation et API
Envoyez des requêtes HTTP depuis vos propres programmes et scripts, ou utilisez nos bibliothèques prêtes à l'emploi pour Node.js, Python, PHP et Perl.
Ajoutez des tâches par nom de préréglage ou en fournissant une structure JSON complète avec des paramètres détaillés.
Obtenez un contrôle total sur la file d'attente des tâches, suivez l'état des tâches et téléchargez les résultats.
Envoyez une requête HTTP et recevez les résultats immédiatement après la fin de la collecte de données.
Notre solution pour les projets à forte charge. Connectez un nombre illimité d'instances d'A-Parser pour traiter les requêtes API dans une file d'attente Redis avec une latence minimale.
Pour une automatisation complète, une mise à jour à distance d'A-Parser est disponible via un appel API.
Améliorations continues et support
L'évolution constante d'A-Parser offre à nos utilisateurs de nouvelles capacités année après année.
Nous testons tous les scrapers intégrés quotidiennement et automatiquement, ce qui nous permet de publier rapidement des mises à jour en réponse à toute modification de la mise en page ou des résultats.
Un support technique gratuit est disponible pour tous nos utilisateurs et est considéré comme le meilleur parmi les produits similaires.
Nous publions régulièrement des supports pédagogiques, des exemples de préréglages et de scrapers, ainsi que des vidéos tutorielles sur notre chaîne YouTube.
La plupart des nouvelles fonctionnalités et des nouveaux scrapers sont développés à la suite des demandes de nos utilisateurs.
Nous pouvons vous faire gagner du temps en proposant le développement de scrapers personnalisés sur notre plateforme, ainsi que l'intégration avec votre logique métier et vos bases de données.
Choisissez la bonne licence
Licence à vie, mises à jour achetées séparément
A-Parser Lite
Scrapers de base pour Google et Yandex
- Inclut les scrapers pour Google et Yandex
- 3 mois de mises à jour
- Proxies bonus : 20 threads pendant 2 semaines
- Support
A-Parser Pro
Accès à tous les scrapers
- Suite complète de plus de 110 scrapers
- Créez vos propres scrapers en JavaScript
- 6 mois de mises à jour
- Proxies bonus : 50 threads pendant un mois
- Inclut toutes les fonctionnalités du plan Lite
A-Parser Enterprise
Accès à tous les scrapers et à l'API
- Contrôle via l'API
- Traitement des tâches multicœur
- Intégration Redis
- Inclut toutes les fonctionnalités du plan Pro
Mises à jour : 49 $ pour 3 mois, 149 $ pour un an ou 399 $ à vie
Solutions payantes
Développement de scrapers personnalisés
Nous sommes convaincus que toutes les données peuvent être extraites.