В этой статье мы детально рассмотрим процесс создания пресета для анализа сайта в глубину.
На вход подается ссылка на главную сайта. Парсер пройдет по внутренним ссылкам вглубь (пусть будет до 5-го уровня) и соберет в CSV таблицу такие данные:

Можно парсить до определенной глубины сайта, а также спарсить весь сайт целиком при помощи функции Parse to level. Данные, которые можем получить при помощи парсера HTML::LinkExtractor:
HTML::LinkExtractor:
HTML::LinkExtractor.
1. Выбираем парсер HTML::LinkExtractor, потому что данный парсер работает как паук и может автоматически переходить по найденным ссылкам. Заходя на страницу, парсер собирает все внутренние ссылки и после переходит по каждой найденной ссылке. Так происходит до выбраного уровня парсинга или пока не спарсит ссылки со всего сайт, если выбрана опция Parse to level.

2. Выбираем опцию “Парсить до уровня” и ставим значение до какой глубины парсить сайт. В нашем случае ставим значение 5. Парсить до 5 уровня - это значит, что парсер возьмет ссылки с начальной страницы и перейдет по ним вглубь сайта.
Т.е. начальная страница это будет 0 уровень, пройдя на начальной странице вглубь сайта парсер перейдет на 1 уровень. Собрав ссылки на страницах первого уровня парсер переходит по уже полученным ссылкам, и попадает на 2 уровень и т.д.


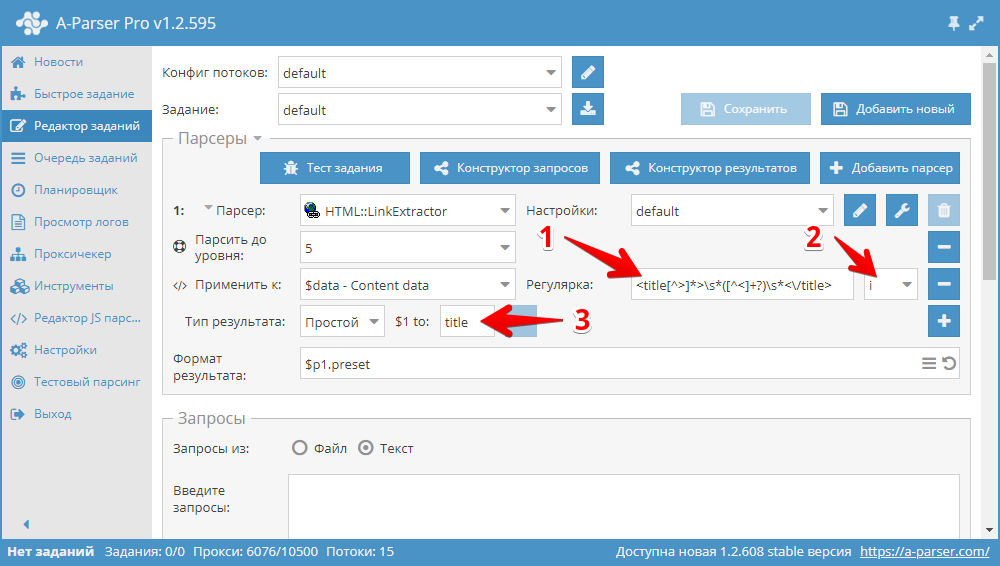
3. Для того чтобы спарсить Title выбираем опцию “Использовать регулярку”.

4. В выпадающем списке выбираем переменную “$data - Content data”, к которой будем применять регулярное выражение.

5. Пишем регулярное выражение в поле “Регулярка” -
. А в поле “$1 to” указываем имя переменной, в которую будет записано значение первой группы из регулярки - title.
6. Добавляем переопределение “Good status” и в поле “Значение” выбираем коды ответов сервера, которые нужно собирать для страниц. В данном случае выбираем 200, все 4хх и 500. Оставляем не выбранными 3хх и все что больше 200. Это необходимо для того, чтобы парсер при получении этих статусов считал ответ удачным, а при любых других - повторял попытки.



7. Нажимаем кнопку “Конструктор результатов”.

Выбираем источник $p1.title.

В поле “Тип” выбираем “Decode HTML entities”. Это необходимо чтобы преобразовать HTML сущности, которые могут встречаться внутри title. В поле “Сохранить в” будет автоматически указана переменная, в которую будет сохраняться полученный результат.

8. В поле “Формат результата” пишем тот формат, в котором необходимо вывести весь результат парсинга. В данном случае указываем tools.CSVline, чтобы автоматически привести значения к формату CSV. И добавляем в скобках переменные, значения которых необходимо занести в таблицу результата. Получим вот такой код

9. В поле “Введите запросы” необходимо ввести ссылку на сайт, который необходимо парсить. Например, https://a-parser.com. Формат запроса оставляем по умолчанию - $query. В опциях ставим галку “Уникальные запросы”, чтобы исключить повторную обработку ранее обработанных страниц.

10. В блоке “Результаты” прописываем имя файла и шапку для таблицы в соответствующие поля:

11. Результат появится в папке с парсером по пути (\aparser\results\). Открыв результат увидим таблицу с данными (скрин в самом начале статьи).
В этой статье показали пример как можно собирать внутренние ссылки в глубь сайта. Рассказали о том как можно расширить поиск при помощи опции Parse to level. Кроме внутренних ссылок можно парсить внешние ссылки с сайта и получать тег nofollow.
Данный пресет вы можете найти в нашем Каталоге по этой ссылке.
На вход подается ссылка на главную сайта. Парсер пройдет по внутренним ссылкам вглубь (пусть будет до 5-го уровня) и соберет в CSV таблицу такие данные:
- ссылка на страницу;
- тайтл (с очисткой от HTML сущностей);
- код ответа;
- кол-во редиректов;
- кол-во внешних ссылок;
- глубина (уровень) относительно главной.
Можно парсить до определенной глубины сайта, а также спарсить весь сайт целиком при помощи функции Parse to level. Данные, которые можем получить при помощи парсера
HTML::LinkExtractor:- Внешние ссылки
- ссылка
- анкор
- анкор без HTML
- параметр nofollow
- Внутренние ссылки
- ссылка
- анкор
- анкор без HTML
- параметр nofollow
- Кол-во внутренних ссылок на странице
- Кол-во внешних ссылок на странице
HTML::LinkExtractor.1. Выбираем парсер
HTML::LinkExtractor, потому что данный парсер работает как паук и может автоматически переходить по найденным ссылкам. Заходя на страницу, парсер собирает все внутренние ссылки и после переходит по каждой найденной ссылке. Так происходит до выбраного уровня парсинга или пока не спарсит ссылки со всего сайт, если выбрана опция Parse to level.
2. Выбираем опцию “Парсить до уровня” и ставим значение до какой глубины парсить сайт. В нашем случае ставим значение 5. Парсить до 5 уровня - это значит, что парсер возьмет ссылки с начальной страницы и перейдет по ним вглубь сайта.
Т.е. начальная страница это будет 0 уровень, пройдя на начальной странице вглубь сайта парсер перейдет на 1 уровень. Собрав ссылки на страницах первого уровня парсер переходит по уже полученным ссылкам, и попадает на 2 уровень и т.д.
3. Для того чтобы спарсить Title выбираем опцию “Использовать регулярку”.
4. В выпадающем списке выбираем переменную “$data - Content data”, к которой будем применять регулярное выражение.
5. Пишем регулярное выражение в поле “Регулярка” -
Код:
<title[^>]*>\s*([^<]+?)\s*<\/title>6. Добавляем переопределение “Good status” и в поле “Значение” выбираем коды ответов сервера, которые нужно собирать для страниц. В данном случае выбираем 200, все 4хх и 500. Оставляем не выбранными 3хх и все что больше 200. Это необходимо для того, чтобы парсер при получении этих статусов считал ответ удачным, а при любых других - повторял попытки.
7. Нажимаем кнопку “Конструктор результатов”.
Выбираем источник $p1.title.
В поле “Тип” выбираем “Decode HTML entities”. Это необходимо чтобы преобразовать HTML сущности, которые могут встречаться внутри title. В поле “Сохранить в” будет автоматически указана переменная, в которую будет сохраняться полученный результат.
8. В поле “Формат результата” пишем тот формат, в котором необходимо вывести весь результат парсинга. В данном случае указываем tools.CSVline, чтобы автоматически привести значения к формату CSV. И добавляем в скобках переменные, значения которых необходимо занести в таблицу результата. Получим вот такой код
Код:
[% tools.CSVline(query, p1.title, p1.code, p1.response.Redirects.size, p1.extcount, query.lvl) %]- query - начальный запрос;
- p1.title - тайтл запроса;
- p1.code - код ответа сервера запроса;
- p1.response.Redirects.size - кол-во предыдущих редиректов;
- p1.extcount - кол-во внешних ссылок;
- query.lvl - уровень глубины, относительно начального запроса;
9. В поле “Введите запросы” необходимо ввести ссылку на сайт, который необходимо парсить. Например, https://a-parser.com. Формат запроса оставляем по умолчанию - $query. В опциях ставим галку “Уникальные запросы”, чтобы исключить повторную обработку ранее обработанных страниц.
10. В блоке “Результаты” прописываем имя файла и шапку для таблицы в соответствующие поля:
- Имя файла - можно написать как свое имя так и написать встроенную переменную для названия файла по запросу или по дате.
- Начальный текст - пишем шапку таблицы через запятую.
11. Результат появится в папке с парсером по пути (\aparser\results\). Открыв результат увидим таблицу с данными (скрин в самом начале статьи).
В этой статье показали пример как можно собирать внутренние ссылки в глубь сайта. Рассказали о том как можно расширить поиск при помощи опции Parse to level. Кроме внутренних ссылок можно парсить внешние ссылки с сайта и получать тег nofollow.
Данный пресет вы можете найти в нашем Каталоге по этой ссылке.