Начиная с версии 1.2.752 в A-Parser появилась полноценная поддержка Node.js. Это позволяет использовать очень большое количество различных модулей, значительно увеличивая возможности парсера. Множество различных сервисов предоставляют уже готовые модули, полностью реализующие их API. И об одном из таких сервисов пойдет речь в этой статье.
Google Vision - это целый набор различных инструментов, которые основаны на "компьютерном зрении". В основе этой технологии лежит искусственный интеллект и машинное обучение. Более детально узнать о сервисе можно тут.
В качестве примера мы рассмотрим такую задачу:

А в конечном итоге мы получим список ссылок на картинки, где изображен космос или космические объекты:

1. Получение доступа к Google Vision API
Чтобы иметь возможность пользоваться данным сервисом, нужно предварительно пройти процедуру включения API. Подробная инструкция со скриншотами - под спойлером.
2. Создание JS парсера
Теперь перейдем к решению задачи, которую мы сформулировали в начале статьи.
Сначала нужно вручную выбрать 1-2 картинки, подходящие под условия задачи и получить список их меток с помощью парсера, который мы создали ранее. Не обязательно из нашего набора картинок, можно просто найти в интернете нужную картинку. Это необходимо для того, чтобы определить, по каким меткам фильтровать все остальные картинки.
Например, мы подобрали нужный нам список меток:
Заключение
Рассмотренный выше пример является довольно простым, но с его помощью можно на практике познакомиться с технологией "компьютерного зрения" и ее применением в A-Parser. Экспериментируя с набором меток в фильтре, можно получать еще более качественные результаты.
В целом, данный метод будет полезен для любых задач, связанных с классификацией или каталогизацией изображений, а также для поиска тематических картинок и отсеивания различного мусора, чего очень сложно добиться при классическом поиске картинок в поисковиках.
Кроме получения меток, инструменты Google Vision предоставляют еще много возможностей, подробнее о которых можно почитать тут. Одной из самых интересных функций является распознавание текста, которое можно применять для разгадывания каптч или различной текстовой информации из картинок. Например, телефоны на Авито")
Google Vision - это целый набор различных инструментов, которые основаны на "компьютерном зрении". В основе этой технологии лежит искусственный интеллект и машинное обучение. Более детально узнать о сервисе можно тут.
В качестве примера мы рассмотрим такую задачу:
В качестве запросов будут использоваться ссылки на картинки с различным содержимым:
А в конечном итоге мы получим список ссылок на картинки, где изображен космос или космические объекты:
1. Получение доступа к Google Vision API
Чтобы иметь возможность пользоваться данным сервисом, нужно предварительно пройти процедуру включения API. Подробная инструкция со скриншотами - под спойлером.
- Открываем Консоль Google, авторизуемся и при необходимости создаем новый проект

- В боковом меню выбираем API и сервисы - Библиотека и на открывшейся странице ищем Google Vision API

- Нажимаем кнопку Включить и на открывшейся странице кликаем Создать учетные данные


- Следуя инструкциям, создаем сервисный аккаунт, отмечаем все пункты, как на скриншотах ниже


- В результате будет создан и загружен файл в JSON формате. Переименовываем его в credentials.json и сохраняем в каталог aparser/files/
- Т.к. Vision API - это платный сервис (цены), то обязательно необходимо настроить платежный аккаунт. Для этого переходим в пункт Оплата и настраиваем платежный аккаунт для нашего проекта.

- На этом получение доступа к API закончено.
2. Создание JS парсера
- Устанавливаем модуль в aparser/files/:
Код:npm install --save @google-cloud/vision - Запускаем А-Парсер с параметром -newnode
- Пишем JS парсер. Практически полностью готовый пример есть в документации по Google Vision, его нужно немного адаптировать для использования в А-Парсере. Например, добавить повторные попытки при определенных ошибках. В целом код парсера довольно простой:
Код:const vision = require('@google-cloud/vision'); let client; class Parser { constructor() { this.defaultConf = { version: '0.1.3', results: { arrays: { labels: ['Labels list', [ ['label', 'Label'], ['score', 'Score'] ]] } }, results_format: "$labels.format('$label\\n')", }; } init() { client = new vision.ImageAnnotatorClient({credentials: require('./files/credentials.json')}); } async *parse(set, results) { results.labels = []; for(let a = 1; a <= this.conf.proxyretries; a++) { let [result] = await client.labelDetection(set.query); if(result.error) { if(/We can not access the URL currently/.test(result.error.message)) continue; this.logger.put(result.error.message); results.success = 0; } else { const labels = result.labelAnnotations; labels.forEach((label) => { results.labels.push( label.description, label.score ) }); this.logger.put(`Total found ${results.labels.length / 2} labels`); results.success = 1; } break; } return results; } }- в init() инициализируем клиент, указав путь к ранее сохраненному файлу с учетными данными
- в parse() делаем запросы, повторяя попытку в том случае, если сервис вернул ошибку загрузки картинки
- в результат выводим массив меток
- Пример результата работы для картинки:


- Таким образом у нас получился полноценный JS парсер, который позволяет определять содержимое картинок с использованием Google Vision.
Теперь перейдем к решению задачи, которую мы сформулировали в начале статьи.
Сначала нужно вручную выбрать 1-2 картинки, подходящие под условия задачи и получить список их меток с помощью парсера, который мы создали ранее. Не обязательно из нашего набора картинок, можно просто найти в интернете нужную картинку. Это необходимо для того, чтобы определить, по каким меткам фильтровать все остальные картинки.
Например, мы подобрали нужный нам список меток:
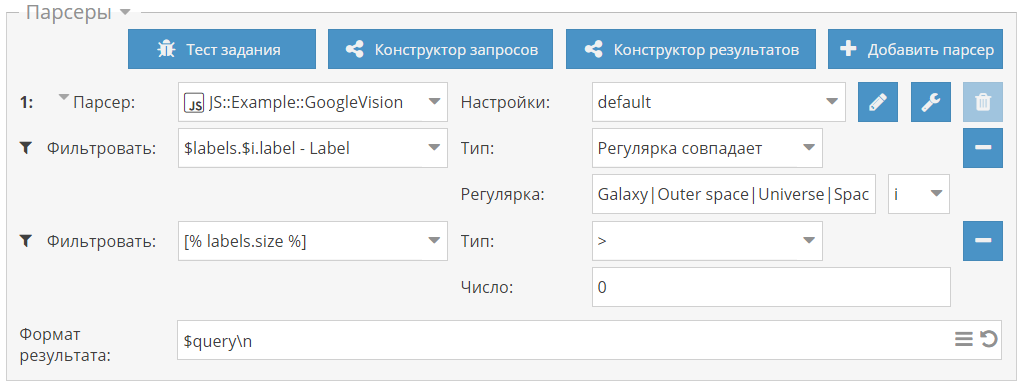
Сформируем из него простое регулярное выражение и используем его для фильтрации картинок. Для этого создадим пресет с двумя фильтрами:
- в первом фильтре массив меток фильтруется по необходимым нам меткам
- во втором фильтре проверяется размер массива после первого фильтра, и если там больше 0 элементов, то выводится в результат начальный запрос, т.е. ссылка на картинку
- готовый пресет доступен в каталоге: https://a-parser.com/resources/379/
Заключение
Рассмотренный выше пример является довольно простым, но с его помощью можно на практике познакомиться с технологией "компьютерного зрения" и ее применением в A-Parser. Экспериментируя с набором меток в фильтре, можно получать еще более качественные результаты.
В целом, данный метод будет полезен для любых задач, связанных с классификацией или каталогизацией изображений, а также для поиска тематических картинок и отсеивания различного мусора, чего очень сложно добиться при классическом поиске картинок в поисковиках.
Кроме получения меток, инструменты Google Vision предоставляют еще много возможностей, подробнее о которых можно почитать тут. Одной из самых интересных функций является распознавание текста, которое можно применять для разгадывания каптч или различной текстовой информации из картинок. Например, телефоны на Авито
