Установить приложение
Как установить приложение на iOS
Следуйте инструкциям в видео ниже, чтобы узнать, как установить наш сайт как веб-приложение на главный экран вашего устройства.
Примечание: Эта функция может быть недоступна в некоторых браузерах.
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Необходимо обновить браузер или попробовать использовать другой.
Подскажите парсер текста
- Автор темы kolya757
- Дата начала
Все это можно сделать с помощью двух заданий.
Первым заданием мы парсим из Google топ10 сайтов. Для этого нужно выбрать парсер SE:Google и задать для него настройки: Pages count (кол-во страниц) - 1 и Links per page (кол-во ссылок на странице) - 10.
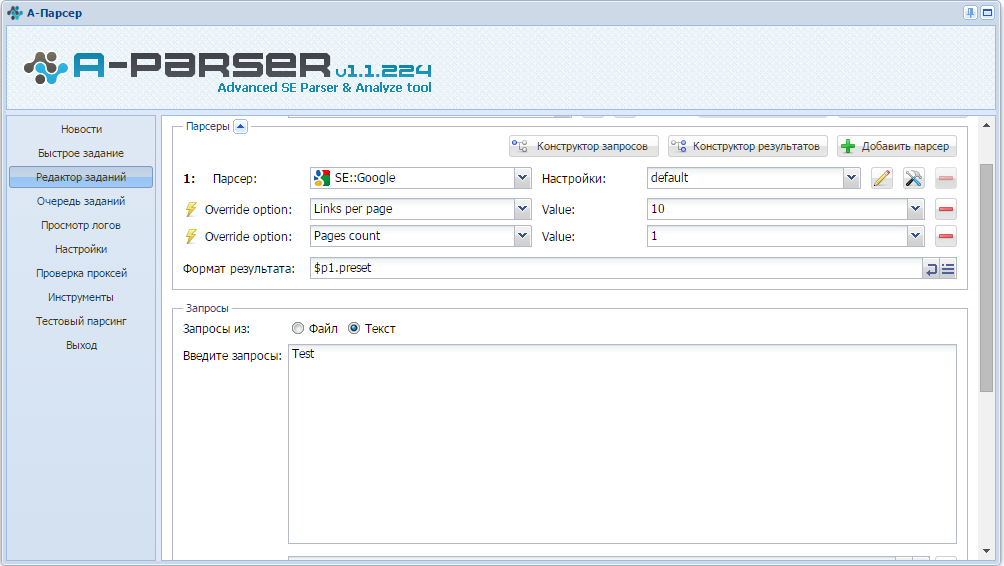
Вторым заданием парсим текст из ссылок. Для этого нужно использовать парсер HTML::TextExtractor. Для записи каждого результата в отдельный файл следует указать в Имени файла: ${query.num}.txt (или в отдельную папку - text/${query.num}.txt)
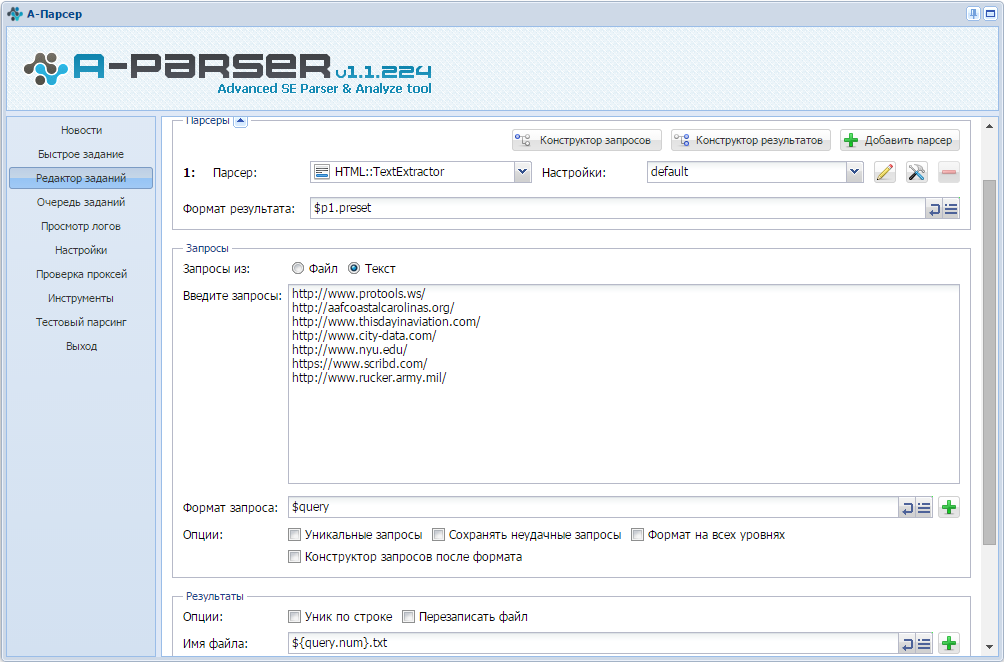
Первым заданием мы парсим из Google топ10 сайтов. Для этого нужно выбрать парсер SE:Google и задать для него настройки: Pages count (кол-во страниц) - 1 и Links per page (кол-во ссылок на странице) - 10.
Вторым заданием парсим текст из ссылок. Для этого нужно использовать парсер HTML::TextExtractor. Для записи каждого результата в отдельный файл следует указать в Имени файла: ${query.num}.txt (или в отдельную папку - text/${query.num}.txt)
Последнее редактирование:
Спасибо большое! а подскажите пожалуйста, можно ли как то, сделать чтоб текст парсился не весь подряд, а чтобы каждое предложение в тексте было от 50 символов, именно предложение, а не блог текста? а то если ставить блог текста, то он и категории меню парсит с сайтов, а это получается мусор((
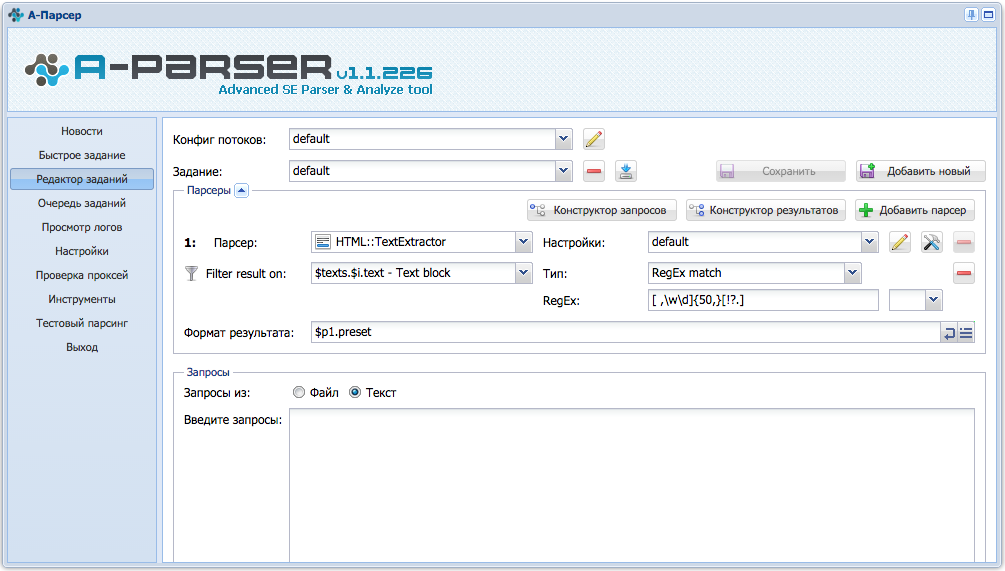
Добрый день! у меня немного похожий вопрос:
есть список форумов, где возможно оставлен мой пост (каждый раз - рандом текст), в конце каждого поста - поставлен маркер (не изменяемый): private code: (6T5J7uyTRkJuh7S)
как мне вытащить все линки из моего списка - где стоит этот маркер, т.е. соответственно и проставился пост.
Пробовал HTML::TextExtractor с разными настройками, но или весь текст со страницы парсится со всеми заголовками, либо вообще пустой файл получается.
есть список форумов, где возможно оставлен мой пост (каждый раз - рандом текст), в конце каждого поста - поставлен маркер (не изменяемый): private code: (6T5J7uyTRkJuh7S)
как мне вытащить все линки из моего списка - где стоит этот маркер, т.е. соответственно и проставился пост.
Пробовал HTML::TextExtractor с разными настройками, но или весь текст со страницы парсится со всеми заголовками, либо вообще пустой файл получается.
http://a-parser.com/threads/946/как мне вытащить все линки из моего списка - где стоит этот маркер, т.е. соответственно и проставился пост.

в текстпайпе пакетно можноЭто я знаю но когда на выходе 100к файлов то так не получится массово сменить
Подскажите пожалуйста хочу спарсить текст с сайтов но запутался(
Вообщем есть файл с запросами вида:
КЕЙ1|сылка1|сылка2|сылка3|сылка4|сылка5|
КЕЙ2|сылка1|сылка2|сылка3|сылка4|сылка5|
Как задать запрос чтобы собирал текст с указанных ссылок и при этом сохронял это все в 1 файл в таком виде:
КЕЙ1|текст1|текст2|текст3|текст4|текст5|
возможно ли это вообще реализовать?
Вообщем есть файл с запросами вида:
КЕЙ1|сылка1|сылка2|сылка3|сылка4|сылка5|
КЕЙ2|сылка1|сылка2|сылка3|сылка4|сылка5|
Как задать запрос чтобы собирал текст с указанных ссылок и при этом сохронял это все в 1 файл в таком виде:
КЕЙ1|текст1|текст2|текст3|текст4|текст5|
возможно ли это вообще реализовать?
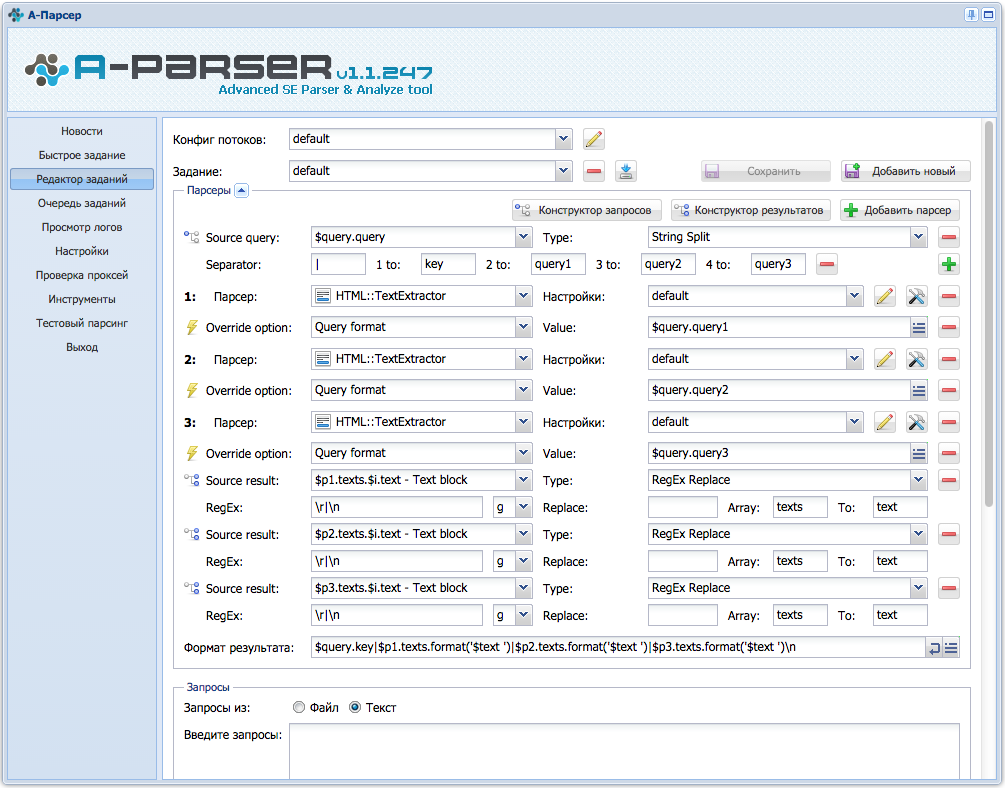
Решил написать здесь. Пробую парсить тематический текст по ссылкам с помощью TextExtractor. Пересмотрел кучу инфы на форуме, начал составлять пресет и ... не осилил.((
Помогите, пожалуйста, с такими моментами:
1. Фильтры по регуляркам.
Нужно, чтобы:
а) парсились предложения только от 50 символов и в конце проставлялась точка(если ее не было). Пока использую регулярку с 4-го поста выше
б) каждая спарсенная строка начиналась с большой буквы(если ее не было)
в) если начало строки какой-то знак(и), цифра(ы), то удаление знака и цифр до первого слова, которое преобразуется с большой буквы
г) очистка от всякого мусора(ссылки, мыла, иероглифы и т.д.)
Чтобы получалось вроде этого, но только под РУ

Помогите, пожалуйста, с такими моментами:
1. Фильтры по регуляркам.
Нужно, чтобы:
а) парсились предложения только от 50 символов и в конце проставлялась точка(если ее не было). Пока использую регулярку с 4-го поста выше
б) каждая спарсенная строка начиналась с большой буквы(если ее не было)
в) если начало строки какой-то знак(и), цифра(ы), то удаление знака и цифр до первого слова, которое преобразуется с большой буквы
г) очистка от всякого мусора(ссылки, мыла, иероглифы и т.д.)
Чтобы получалось вроде этого, но только под РУ
Желательно иметь пример, чтобы ответ был более корректный. Вообще могут быть разные варианты, например чтобы точка проставлялась - это врятли, т.к. откуда парсеру знать где ее ставить? Плюс парсинг предложений более 50 символов уже подразумевает разбивку на предложения на основе каких-то признаков. А это и есть точка, знак восклицания или вопроса. Но в общих чертах в пресете это делается так:
- несколько Конструкторов результатов с функцией RegEx Replace, для каждого вида "мусора" указываем свою регулярку и заменяем на пустоту для очистки от мусора;
- разбиваем на предложения Конструктором результатов с функцией RegEx Match и регуляркой из 4-го поста;
- по полученному массиву проходимся следующим Конструктором результатов с функцией RegEx Replace, указываем регулярку ^[\W\d_]+ и заменяем на пустоту для удаления начальных знаков и цифр;
- выводим результат, используя шаблонизатор и его функцию .ucfirst (Ссылка) для перевода первой буквы в верхний регистр.
Поделиться:
О нас
A-Parser - это профессиональная платформа для сбора данных промышленного масштаба: 10 000+ потоков, 110+ парсеров и гибкость Node.js. Автоматизируйте задачи в SEO, e-commerce и арбитраже трафика с непревзойденной скоростью и масштабируемостью
Быстрая навигация
Поддержка
Нужна помощь с настройкой или работой парсера? Напишите в поддержку, поможем довести все до результата.
Написать в поддержку