Разбор полетов породил несколько вопросов
")
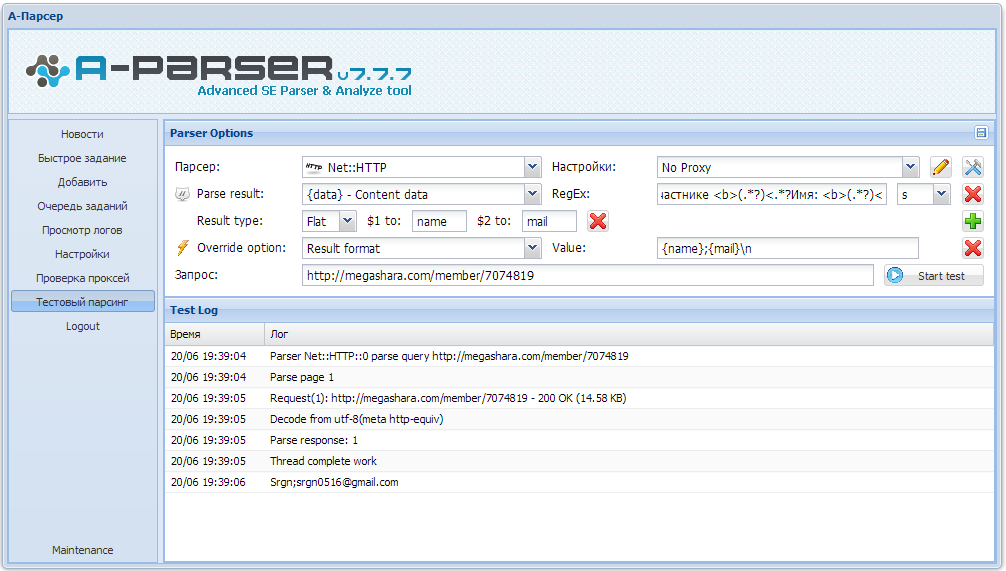
1. Можно обойтись без регулярок при определении границ парсинга? В ContentDownloader для юзабельно сделан этот нюанс. Или же без регулярок не обойтись и лучше потратить время на их изучение?
2. Второй вопрос вытекает из первого, флаг ' s ' - это символ из регулярок или же это что-то из внутренней логики парсера? Что означают другие символы?
3.
Эта регкулярка ищет, как я понимаю, любые символы, до первого символа?
Если в качестве имени будет указан
[email protected] - будет ли сохранен данный майл ?
4. На мегашаре емайлы в профилях попадаются еще и в других полях, например:
http://megashara.com/member/7195980 - тут емайл адрес прописан в поле Email: -
Код:
Email: <b><a href="mailto:syrotyuk020895%40mail.ru" target="_blank" rel="nofollow">[email protected]</a></b></div>
http://megashara.com/member/7069431 - на этой страничке юзер оставил свое мыло в поле
Откуда:
http://megashara.com/member/787466 - а тут юзер перепутал поля и прописал свой емайл вместо адреса сайта - Сайт:
http://[email protected]. Такое мыло тоже нужно спарсить и преобразовать в нормальный вид
http://megashara.com/member/7134313 - в этом примере емайл записан в поле = Вконтакте:
[email protected]
http://megashara.com/member/6977724 - тут мыло записано вместо моего мира -
Мой мир:
[email protected]
http://megashara.com/member/7173809 - на это страничке мыло вообще неприкаянное в самом низу профиля записано
Собственно вопрос, имеет ли смысл прописывать каждое из возможных условий парсинга или же проще будет прописать одну регулярку, которая будет искать емайлы в любых произвольных местах странички?