Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём неправильно. Необходимо обновить браузер или попробовать использовать другой.
Первым делом необходимо спарсить все внутренние ссылки данного сайта, используя парсер HTML::LinkExtractor, в документации есть пример
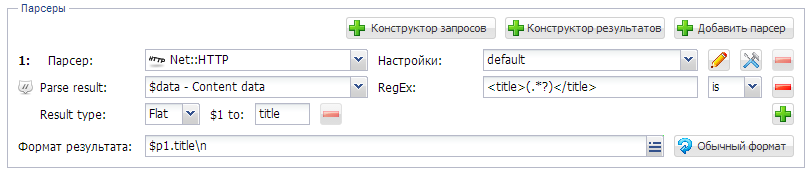
Затем по собранной базе ссылок можно спарсить тайтлы с помощью Net::HTTP:
На данном сайте используются файлы cookie, чтобы персонализировать контент и сохранить Ваш вход в систему, если Вы зарегистрируетесь.
Продолжая использовать этот сайт, Вы соглашаетесь на использование наших файлов cookie.