На форуме уже давно поднималась эта тема: здесь и здесь. Давайте же проверим, как лучше их все-таки собирать и вообще, насколько это эффективно. В данном посте я буду использовать 2 метода сборки. Эффективность будем оценивать по затраченному времени и количеству живых прокси.
Вариант 1.
Сначала мы парсим из Гугла все подсказки, которые выдаются к словам прокси и proxy. Для этого используем парсер SE::Google::Suggest. В качестве запросов задаем вышеуказанные слова с подстановками, для того, чтобы получить как можно больше ключевых слов. Также укажем глубину парсинга Parse to level 3. Большее значение тоже можно указать, но как показывает практика - чем больше глубина, тем дальше от нашей темы уходят подсказки. К примеру по таким ключам
SE::Google::Suggest. В качестве запросов задаем вышеуказанные слова с подстановками, для того, чтобы получить как можно больше ключевых слов. Также укажем глубину парсинга Parse to level 3. Большее значение тоже можно указать, но как показывает практика - чем больше глубина, тем дальше от нашей темы уходят подсказки. К примеру по таким ключам


Вторым этапом, после того, как первое задание отработает, мы вручную ищем в Гугле публичные прокси, например по запросу бесплатные прокси. Найденные адреса, в формате IP:PORT добавляем в файл, полученный в первом задании.
 SE::Google, парсим ссылки на страницы, где попадаются все найденные ключи и адреса. Дабы не усложнять работу и сэкономить время, парсим только первую страницу выдачи - 100 ссылок на каждый запрос. Результаты все сохраняем в файл.
SE::Google, парсим ссылки на страницы, где попадаются все найденные ключи и адреса. Дабы не усложнять работу и сэкономить время, парсим только первую страницу выдачи - 100 ссылок на каждый запрос. Результаты все сохраняем в файл.


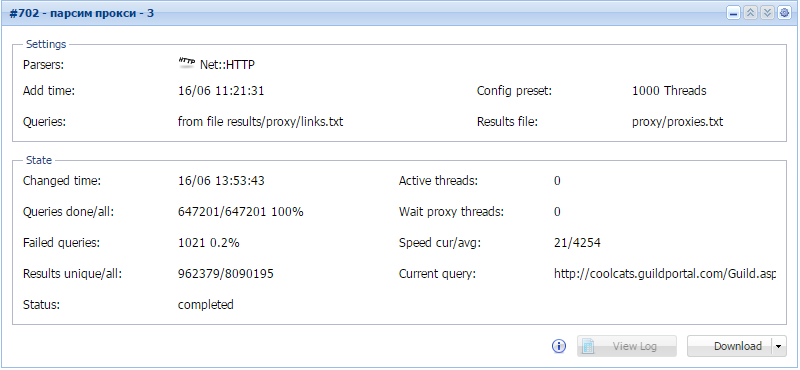
Третьим этапом мы ищем на всех страницах, ссылки на которые мы получили во втором этапе, нужные нам адреса, все в том же формате IP:PORT. Данный процесс осуществляется с помощью парсера Net::HTTP и регулярного выражения.
Net::HTTP и регулярного выражения.
Также не забываем отфильтровать зарезирвированные IP, такие как 127.0.0.1 или 192.168.1.1... На выходе мы получим файл, в котором будут собраны все найденные адреса. И да, тоже используем уникализацию, иначе зачем нам повторяющиеся адреса?

Ну и наконец нам необходимо проверить сколько же из них есть живых. Для этого используем Proxy checker. При этом в его настройках отмечаем опцию Save alive proxies to file.

Вариант 2.
Здесь мы не будем парсить ключевые слова, а сразу будем парсить ссылки только по найденым вручную прокси (в примере были использованы те же вручную найденные прокси, что и в первом варианте). Поэтому весь процесс полностью аналогичен первому варианту, за исключением первого этапа - его мы пропускаем.



Итоги.
В первом варианте найдено 962379 прокси за 168 минут. Во втором - 758936 за 9 минут! Даже если добавить сюда время на ручной поиск стартовых прокси в Гугле - налицо значительное преимущество второго варианта. Теперь, что косается количества живых прокси. В первом варианте живых 0,26%, во втором - 0,36%.
Ну что же, однозначно второй вариант значительно лучше: он и быстрее, и живых прокси выдает больше (в процентном соотношении). На проверку состояния этих прокси уходят еще несколько часов. Но, стоят ли того ~2500 прокси, которые неизвестно сколько проживут? Решать вам... Ну а в качестве бонуса вот эти самые, живые на момент написания статьи, прокси: скачать.
P.S. Ах да, известны случаи, когда именно из-за использования паблик прокси прилетали абузы от хостеров/провайдеров. Поэтому будьте осторожны.
Вариант 1.
Сначала мы парсим из Гугла все подсказки, которые выдаются к словам прокси и proxy. Для этого используем парсер
SE::Google::Suggest. В качестве запросов задаем вышеуказанные слова с подстановками, для того, чтобы получить как можно больше ключевых слов. Также укажем глубину парсинга Parse to level 3. Большее значение тоже можно указать, но как показывает практика - чем больше глубина, тем дальше от нашей темы уходят подсказки. К примеру по таким ключаммы уходим уже в сторону программирования, а по такимcreate web service proxy class c#
c# call webservice without proxy class
c# using web service proxy class
- в сторону игр. Поэтому было выбрано значение 3, вы же, эксперементируя, можете использовать другие значения. Также не забываем об уникализации, чтобы не делать лишнюю работу.proxy nfl game pass free trial 2013
proxy nfl game pass free trial promo code
proxy nfl game pass free trial cancel
proxy nfl game pass free trial 2012
proxy nfl game pass free account sharing
proxy nfl game pass free account hack
proxy nfl game pass free account password
proxy nfl game pass free accounts
Код:
eyJwcmVzZXQiOiJcdTA0M2ZcdTA0MzBcdTA0NDBcdTA0NDFcdTA0MzhcdTA0M2Mg
XHUwNDNmXHUwNDQwXHUwNDNlXHUwNDNhXHUwNDQxXHUwNDM4IC0gMSIsInZhbHVl
Ijp7InByZXNldCI6Ilx1MDQzZlx1MDQzMFx1MDQ0MFx1MDQ0MVx1MDQzOFx1MDQz
YyBcdTA0M2ZcdTA0NDBcdTA0M2VcdTA0M2FcdTA0NDFcdTA0MzggLSAxIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZTo6U3VnZ2VzdCIsImRlZmF1bHQiLHsidHlwZSI6
Im9wdGlvbnMiLCJpZCI6InBhcnNlTGV2ZWwiLCJ2YWx1ZSI6M30seyJ0eXBlIjoi
b3ZlcnJpZGUiLCJpZCI6ImZvcm1hdHJlc3VsdCIsInZhbHVlIjoiJHJlc3VsdHMu
Zm9ybWF0KCckc3VnZ2VzdFxcbicpIn0seyJ0eXBlIjoib3ZlcnJpZGUiLCJpZCI6
InByb3h5cmV0cmllcyIsInZhbHVlIjoiMzAifV1dLCJyZXN1bHRzRm9ybWF0Ijoi
JHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0c0ZpbGVO
YW1lIjoicHJveHkva2V5cy50eHQiLCJhZGRpdGlvbmFsRm9ybWF0cyI6W10sInJl
c3VsdHNVbmlxdWUiOiJzdHJpbmciLCJxdWVyeUZvcm1hdCI6WyIkcXVlcnkiXSwi
dW5pcXVlUXVlcmllcyI6dHJ1ZSwic2F2ZUZhaWxlZFF1ZXJpZXMiOmZhbHNlLCJp
dGVyYXRvck9wdGlvbnMiOnsib25BbGxMZXZlbHMiOmZhbHNlLCJxdWVyeUJ1aWxk
ZXJzQWZ0ZXJJdGVyYXRvciI6ZmFsc2V9LCJyZXN1bHRzT3B0aW9ucyI6eyJvdmVy
d3JpdGUiOmZhbHNlfSwiZG9Mb2ciOiJubyIsImtlZXBVbmlxdWUiOiJObyIsIm1v
cmVPcHRpb25zIjpmYWxzZSwicmVzdWx0c1ByZXBlbmQiOiIiLCJyZXN1bHRzQXBw
ZW5kIjoiIiwicXVlcnlCdWlsZGVycyI6W10sInJlc3VsdHNCdWlsZGVycyI6W10s
ImNvbmZpZ092ZXJyaWRlcyI6W119fQ==Вторым этапом, после того, как первое задание отработает, мы вручную ищем в Гугле публичные прокси, например по запросу бесплатные прокси. Найденные адреса, в формате IP:PORT добавляем в файл, полученный в первом задании.
Далее, по уже подготовленному файлу, используя...
eu proxy server list
eu proxy server free
european proxy server free
free europe proxy server list
proxy pac file generator
proxy pac file syntax
proxy pac files example
jni4net proxygen tutorial
proxy pac file generator for windows
bluecoat proxy pac file example
proxy.pac script examples
mod_proxy proxypass ssl
183.87.129.242:8080
187.94.61.29:80
121.14.9.76:80
111.1.36.166:80
101.227.252.130:8081
180.151.40.175:80
181.143.60.195:8080
196.29.206.14:8080
112.95.244.57:80
218.78.210.190:8080
212.68.51.58:80
174.127.125.62:8080
174.127.125.88:8080
41.73.239.54:808
41.72.215.30:8080
182.18.158.28:9090
186.89.64.16:8080
203.101.179.5:8080
116.236.216.116:8080
...
SE::Google, парсим ссылки на страницы, где попадаются все найденные ключи и адреса. Дабы не усложнять работу и сэкономить время, парсим только первую страницу выдачи - 100 ссылок на каждый запрос. Результаты все сохраняем в файл.
Код:
eyJwcmVzZXQiOiJcdTA0M2ZcdTA0MzBcdTA0NDBcdTA0NDFcdTA0MzhcdTA0M2Mg
XHUwNDNmXHUwNDQwXHUwNDNlXHUwNDNhXHUwNDQxXHUwNDM4IC0gMiIsInZhbHVl
Ijp7InByZXNldCI6Ilx1MDQzZlx1MDQzMFx1MDQ0MFx1MDQ0MVx1MDQzOFx1MDQz
YyBcdTA0M2ZcdTA0NDBcdTA0M2VcdTA0M2FcdTA0NDFcdTA0MzggLSAyIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwcm94eXJldHJpZXMiLCJ2YWx1ZSI6IjE1In0seyJ0eXBlIjoib3Zl
cnJpZGUiLCJpZCI6ImZvcm1hdHJlc3VsdCIsInZhbHVlIjoiJHNlcnAuZm9ybWF0
KCckbGlua1xcbicpIn0seyJ0eXBlIjoib3ZlcnJpZGUiLCJpZCI6InBhZ2Vjb3Vu
dCIsInZhbHVlIjoxfV1dLCJyZXN1bHRzRm9ybWF0IjoiJHAxLnByZXNldCIsInJl
c3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0c0ZpbGVOYW1lIjoicHJveHkvbGlu
a3MudHh0IiwiYWRkaXRpb25hbEZvcm1hdHMiOltdLCJyZXN1bHRzVW5pcXVlIjoi
c3RyaW5nIiwicXVlcnlGb3JtYXQiOlsiJHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMi
OmZhbHNlLCJzYXZlRmFpbGVkUXVlcmllcyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9u
cyI6eyJvbkFsbExldmVscyI6ZmFsc2UsInF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJh
dG9yIjpmYWxzZX0sInJlc3VsdHNPcHRpb25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9
LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZh
bHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIsInJlc3VsdHNBcHBlbmQiOiIiLCJxdWVy
eUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJp
ZGVzIjpbXX19Третьим этапом мы ищем на всех страницах, ссылки на которые мы получили во втором этапе, нужные нам адреса, все в том же формате IP:PORT. Данный процесс осуществляется с помощью парсера
Net::HTTP и регулярного выражения.
Код:
(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}:\d{1,5})
Код:
eyJwcmVzZXQiOiJcdTA0M2ZcdTA0MzBcdTA0NDBcdTA0NDFcdTA0MzhcdTA0M2Mg
XHUwNDNmXHUwNDQwXHUwNDNlXHUwNDNhXHUwNDQxXHUwNDM4IC0gMyIsInZhbHVl
Ijp7InByZXNldCI6Ilx1MDQzZlx1MDQzMFx1MDQ0MFx1MDQ0MVx1MDQzOFx1MDQz
YyBcdTA0M2ZcdTA0NDBcdTA0M2VcdTA0M2FcdTA0NDFcdTA0MzggLSAzIiwicGFy
c2VycyI6W1siTmV0OjpIVFRQIiwiZGVmYXVsdCIseyJ0eXBlIjoiY3VzdG9tUmVz
dWx0IiwicmVzdWx0IjoiZGF0YSIsInJlZ2V4IjoiKFxcZHsxLDN9XFwuXFxkezEs
M31cXC5cXGR7MSwzfVxcLlxcZHsxLDN9OlxcZHsxLDV9KSIsInJlZ2V4VHlwZSI6
ImciLCJyZXN1bHRUeXBlIjoiYXJyYXkiLCJhcnJheU5hbWUiOiJjb250ZW50Iiwi
cmVzdWx0cyI6WyJwcm94eSJdfSx7InR5cGUiOiJvdmVycmlkZSIsImlkIjoiZm9y
bWF0cmVzdWx0IiwidmFsdWUiOiIkY29udGVudC5mb3JtYXQoJyRwcm94eVxcbicp
In0seyJ0eXBlIjoib3ZlcnJpZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZh
bHNlfSx7InR5cGUiOiJmaWx0ZXIiLCJyZXN1bHQiOlsiY29udGVudCIsInByb3h5
Il0sImZpbHRlclR5cGUiOiJyZW5vdG1hdGNoIiwidmFsdWUiOiIxMjdcXC5cXGR7
MSwzfVxcLlxcZHsxLDN9XFwuXFxkezEsM30iLCJvcHRpb24iOiIifSx7InR5cGUi
OiJmaWx0ZXIiLCJyZXN1bHQiOlsiY29udGVudCIsInByb3h5Il0sImZpbHRlclR5
cGUiOiJyZW5vdG1hdGNoIiwidmFsdWUiOiIxMFxcLlxcZHsxLDN9XFwuXFxkezEs
M31cXC5cXGR7MSwzfSIsIm9wdGlvbiI6IiJ9LHsidHlwZSI6ImZpbHRlciIsInJl
c3VsdCI6WyJjb250ZW50IiwicHJveHkiXSwiZmlsdGVyVHlwZSI6InJlbm90bWF0
Y2giLCJ2YWx1ZSI6IjE5MlxcLjE2OFxcLlxcZHsxLDN9XFwuXFxkezEsM30iLCJv
cHRpb24iOiIifSx7InR5cGUiOiJmaWx0ZXIiLCJyZXN1bHQiOlsiY29udGVudCIs
InByb3h5Il0sImZpbHRlclR5cGUiOiJyZW5vdG1hdGNoIiwidmFsdWUiOiIxNzJc
XC4xNlxcLlxcZHsxLDN9XFwuXFxkezEsM30iLCJvcHRpb24iOiIifV1dLCJyZXN1
bHRzRm9ybWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwi
cmVzdWx0c0ZpbGVOYW1lIjoicHJveHkvcHJveGllcy50eHQiLCJhZGRpdGlvbmFs
Rm9ybWF0cyI6W10sInJlc3VsdHNVbmlxdWUiOiJzdHJpbmciLCJxdWVyeUZvcm1h
dCI6WyIkcXVlcnkiXSwidW5pcXVlUXVlcmllcyI6ZmFsc2UsInNhdmVGYWlsZWRR
dWVyaWVzIjpmYWxzZSwiaXRlcmF0b3JPcHRpb25zIjp7Im9uQWxsTGV2ZWxzIjpm
YWxzZSwicXVlcnlCdWlsZGVyc0FmdGVySXRlcmF0b3IiOmZhbHNlfSwicmVzdWx0
c09wdGlvbnMiOnsib3ZlcndyaXRlIjpmYWxzZX0sImRvTG9nIjoibm8iLCJrZWVw
VW5pcXVlIjoiTm8iLCJtb3JlT3B0aW9ucyI6ZmFsc2UsInJlc3VsdHNQcmVwZW5k
IjoiIiwicmVzdWx0c0FwcGVuZCI6IiIsInF1ZXJ5QnVpbGRlcnMiOltdLCJyZXN1
bHRzQnVpbGRlcnMiOltdLCJjb25maWdPdmVycmlkZXMiOltdfX0=Ну и наконец нам необходимо проверить сколько же из них есть живых. Для этого используем Proxy checker. При этом в его настройках отмечаем опцию Save alive proxies to file.
Вариант 2.
Здесь мы не будем парсить ключевые слова, а сразу будем парсить ссылки только по найденым вручную прокси (в примере были использованы те же вручную найденные прокси, что и в первом варианте). Поэтому весь процесс полностью аналогичен первому варианту, за исключением первого этапа - его мы пропускаем.
Итоги.
В первом варианте найдено 962379 прокси за 168 минут. Во втором - 758936 за 9 минут! Даже если добавить сюда время на ручной поиск стартовых прокси в Гугле - налицо значительное преимущество второго варианта. Теперь, что косается количества живых прокси. В первом варианте живых 0,26%, во втором - 0,36%.
Ну что же, однозначно второй вариант значительно лучше: он и быстрее, и живых прокси выдает больше (в процентном соотношении). На проверку состояния этих прокси уходят еще несколько часов. Но, стоят ли того ~2500 прокси, которые неизвестно сколько проживут? Решать вам... Ну а в качестве бонуса вот эти самые, живые на момент написания статьи, прокси: скачать.
P.S. Ах да, известны случаи, когда именно из-за использования паблик прокси прилетали абузы от хостеров/провайдеров. Поэтому будьте осторожны.

