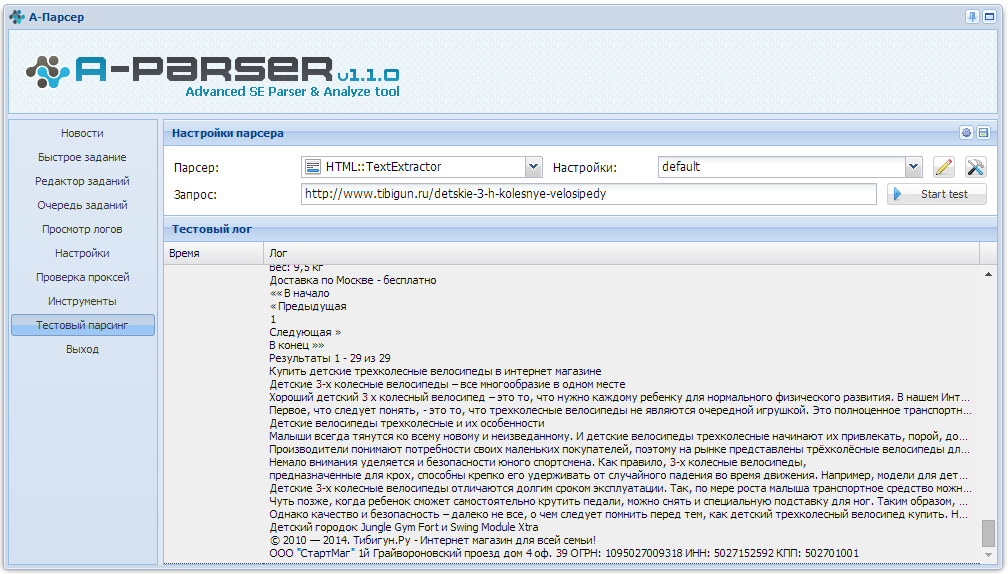
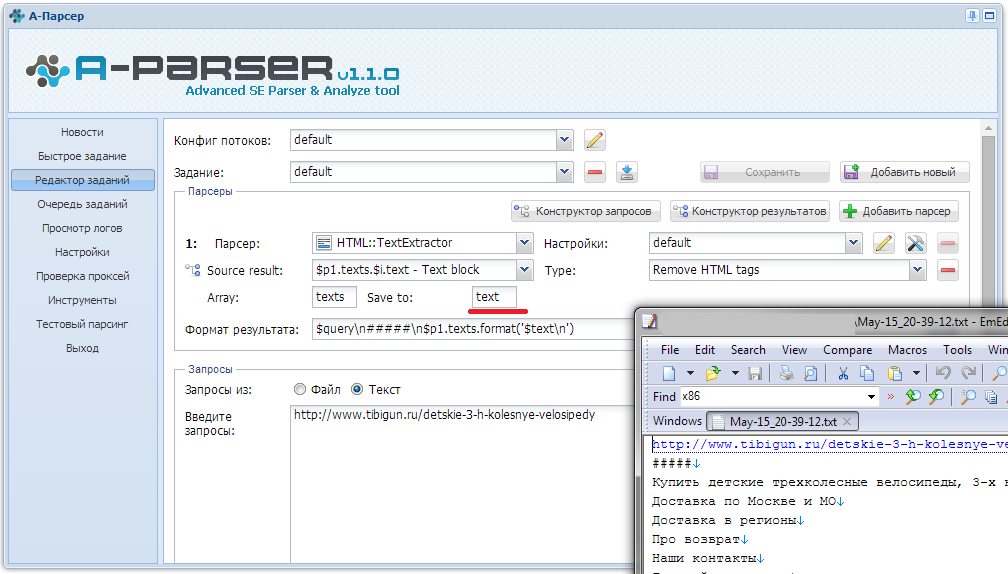
Пробую использовать TextExtractor для парсинга текста по списку урлов. В постобработке поставил очистку от тегов html. В настройках парсера указал минимальный блок в 500 символов, поставил определять кодировку. Но в результате все равно получаю вот такого плана текст:
$("input.search-input").bind("focus",{text:search_input_curr_value},captioned_input_focus);
Выборг
Брянск
О сайте
border-collapse:separate !important;
Нальчик
font-size:13px !important;
callback();
Журнал|
Софрино
Люберцы
18 часов назад
else search_autocomplete_pad.hide();
Харьков
Руза
+7 916 245 34 00,
.ad-ph-pad {
search_obj.html(text_str.replace(search_case_string, ("" + search_case_string + "")));
Трубная
return false;
var addate = new Date();
И тексты не в UTF-8 тоже в файле присутствуют. Как можно полечить это безобразие?
$("input.search-input").bind("focus",{text:search_input_curr_value},captioned_input_focus);
Выборг
Брянск
О сайте
border-collapse:separate !important;
Нальчик
font-size:13px !important;
callback();
Журнал|
Софрино
Люберцы
18 часов назад
else search_autocomplete_pad.hide();
Харьков
Руза
+7 916 245 34 00,
.ad-ph-pad {
search_obj.html(text_str.replace(search_case_string, ("" + search_case_string + "")));
Трубная
return false;
var addate = new Date();
И тексты не в UTF-8 тоже в файле присутствуют. Как можно полечить это безобразие?

")