Установить приложение
Как установить приложение на iOS
Следуйте инструкциям в видео ниже, чтобы узнать, как установить наш сайт как веб-приложение на главный экран вашего устройства.
Примечание: Эта функция может быть недоступна в некоторых браузерах.
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Необходимо обновить браузер или попробовать использовать другой.
Подскажите парсер текста
- Автор темы kolya757
- Дата начала
Все это можно сделать с помощью двух заданий.
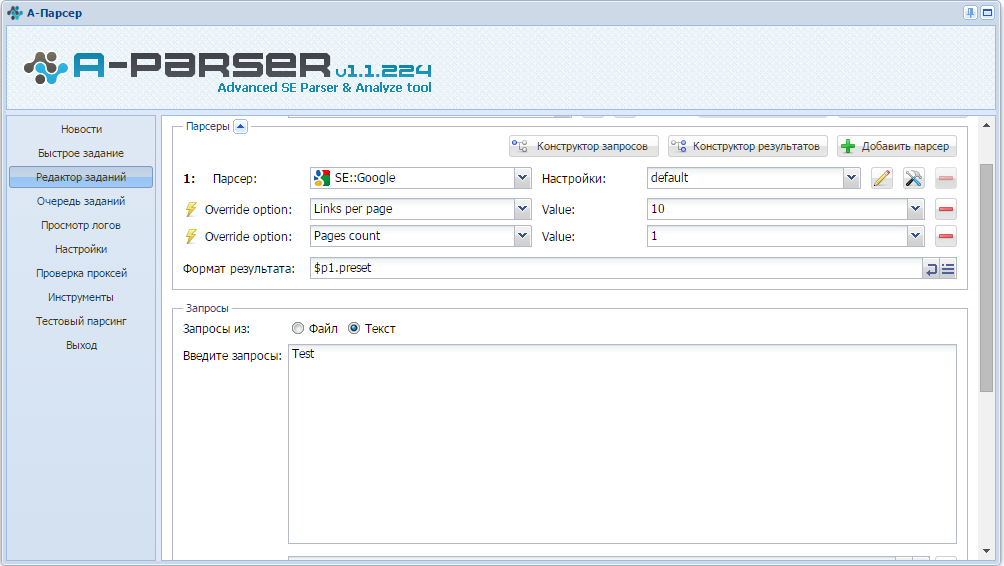
Первым заданием мы парсим из Google топ10 сайтов. Для этого нужно выбрать парсер SE:Google и задать для него настройки: Pages count (кол-во страниц) - 1 и Links per page (кол-во ссылок на странице) - 10.
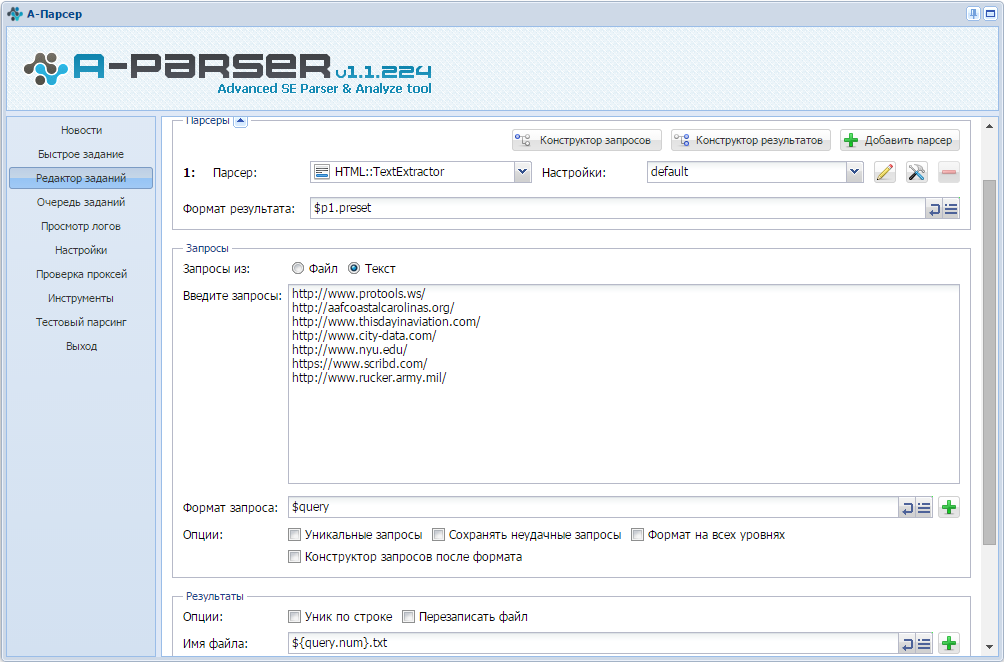
Вторым заданием парсим текст из ссылок. Для этого нужно использовать парсер HTML::TextExtractor. Для записи каждого результата в отдельный файл следует указать в Имени файла: ${query.num}.txt (или в отдельную папку - text/${query.num}.txt)
А как быть если тысячи запросов? Вы привели пример второго парсинга, где указали спаршенные 10 ссылок в текстовом формате. А нужно сначала спарсить по тысяче ключам 10 ссылок из выдачи, а потом из этих 10 ссылок парсить текст. Я не понимаю как можно скормить второму парсеру тысячи спаршенных текстовых файлов (по 10 ссылок в каждом) и потом ещё и записать спаршенное в отдельныё шаблоны. Или как можно это объединить?
Добрый день, вам нужно использовать цепочку заданийА как быть если тысячи запросов? Вы привели пример второго парсинга, где указали спаршенные 10 ссылок в текстовом формате. А нужно сначала спарсить по тысяче ключам 10 ссылок из выдачи, а потом из этих 10 ссылок парсить текст. Я не понимаю как можно скормить второму парсеру тысячи спаршенных текстовых файлов (по 10 ссылок в каждом) и потом ещё и записать спаршенное в отдельныё шаблоны. Или как можно это объединить?
здесь пример описан
https://a-parser.com/resources/326/
А парсер то какой использовать при этом? Сейчас их два в вашем примере, и как и куда прицеплять цепочку не понятно.
Пример можно?
Пример можно?
Вот ссылка на похожий примерА как быть если тысячи запросов? Вы привели пример второго парсинга, где указали спаршенные 10 ссылок в текстовом формате. А нужно сначала спарсить по тысяче ключам 10 ссылок из выдачи, а потом из этих 10 ссылок парсить текст. Я не понимаю как можно скормить второму парсеру тысячи спаршенных текстовых файлов (по 10 ссылок в каждом) и потом ещё и записать спаршенное в отдельныё шаблоны. Или как можно это объединить?
https://a-parser.com/resources/146/
Спасибо, помогло. Остался ещё вопрос. В результирующих файлах парсится много дублей (построчно). Если ставить "уник по строке", то парсер удаляет глобально, забирая в массив все строки из всех результирующих файлов. А нужно в каждом результирующем файле убрать дубли строк, а не глобально. Как можно реализовать на лету в задании или другим способом?Вот ссылка на похожий пример
https://a-parser.com/resources/146/
Нужно смотреть как и какие строки у вас выводятся и исходя из этого можно будет ответить на ваш вопрос. Пришлите ваш пресет, формирующий итоговые файлы и включите в него несколько запросов для теста.нужно в каждом результирующем файле убрать дубли строк, а не глобально.
Пресет взят от сюда https://a-parser.com/resources/146/Нужно смотреть как и какие строки у вас выводятся и исходя из этого можно будет ответить на ваш вопрос. Пришлите ваш пресет, формирующий итоговые файлы и включите в него несколько запросов для теста.
Исходя из него описываю ситуацию!
В него я добавил регексп для выдергивания предложений и формирование результатов построчно, чтобы потом сторонним софтом убирать дубли предложений из каждого результирующего файла, что крайне не удобно. Больше я в нем ничего не менял.
Сейчас, по умолчанию, если парсить схожие ключевые фразы, то линки (топ 10) могут совпадать. Соответственно, когда мы отдаем задание второму парсеру, целые предложения в результирующих файлах будут повторяться (имеется ввиду в разных файлах будет повторяться некоторый текст). Это логично и это не является проблемой. Но кроме этого в каждом файле повторяются сами предложения, т.к. в разных источниках (топ 10) бывает один и тот же текст. Это уже не нужно.
На выходе я вижу почти в каждом файле кучу повторяющихся строк. И текст становится не качественным (с повторами).
файл hello.txt
Видим повтор первых двух строк.hello world
hello world
hello my world
Как уже писал выше, если ставить во вотром парсере галку "уник по строке", то парсер удаляет глобально, забирая в массив все строки из всех результирующих файлов. И когда он это делает, он вырезает у всех последующих файлов вообще весь текст ), т.к. глобально ищет и находит повторы. И удалит "hello world" и "hello my world" вообще из всех файлов, кроме первого.
А нужно в каждом результирующем файле (их может быть тысячи) убрать дубли строк, а не глобально.
Последнее редактирование:
Именно поэтому и нужен ваш пресет, чтобы увидеть как у вас формируется результат и ответить, можно сделать так, как вам нужно.В него я добавил регексп для выдергивания предложений и формирование результатов построчно
Поделиться:
О нас
A-Parser - это профессиональная платформа для сбора данных промышленного масштаба: 10 000+ потоков, 110+ парсеров и гибкость Node.js. Автоматизируйте задачи в SEO, e-commerce и арбитраже трафика с непревзойденной скоростью и масштабируемостью
Быстрая навигация
Поддержка
Нужна помощь с настройкой или работой парсера? Напишите в поддержку, поможем довести все до результата.
Написать в поддержку