Доброго времени всем!
Приобрел А-парсер и хочу отметить что довольное интересная реализация для декстоп программ с использованием регулярок. И сразу же возникло куча вопросов хотя и надо освоить основные 3-5 функций ради чего и приобреталось ПО. По симу прошу помоши у всех кто разбирается в софте расписать желательно пошаговое, потому как думаю не только мне будет полезна данная инфа.
Сами вопросы:
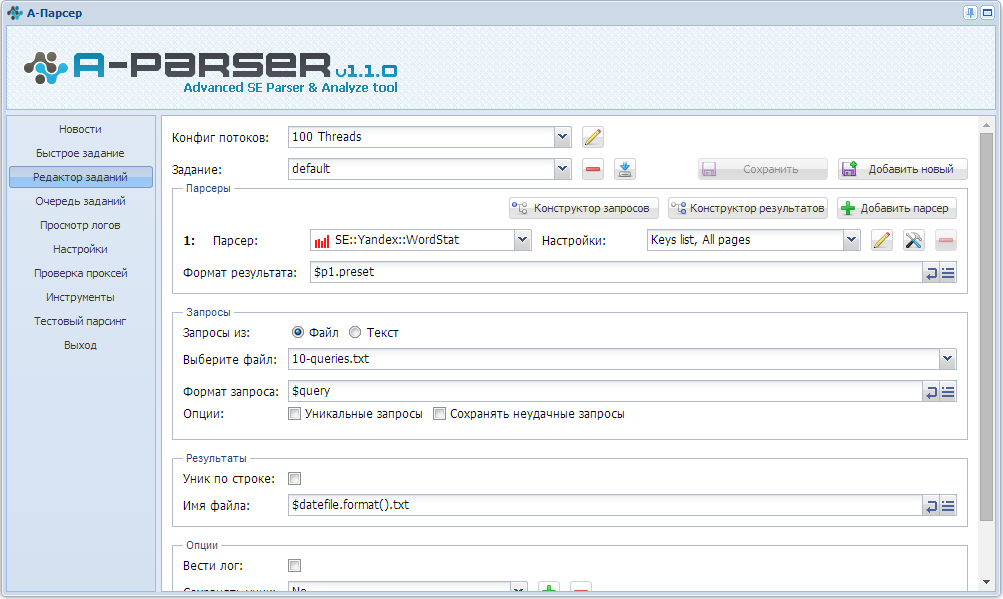
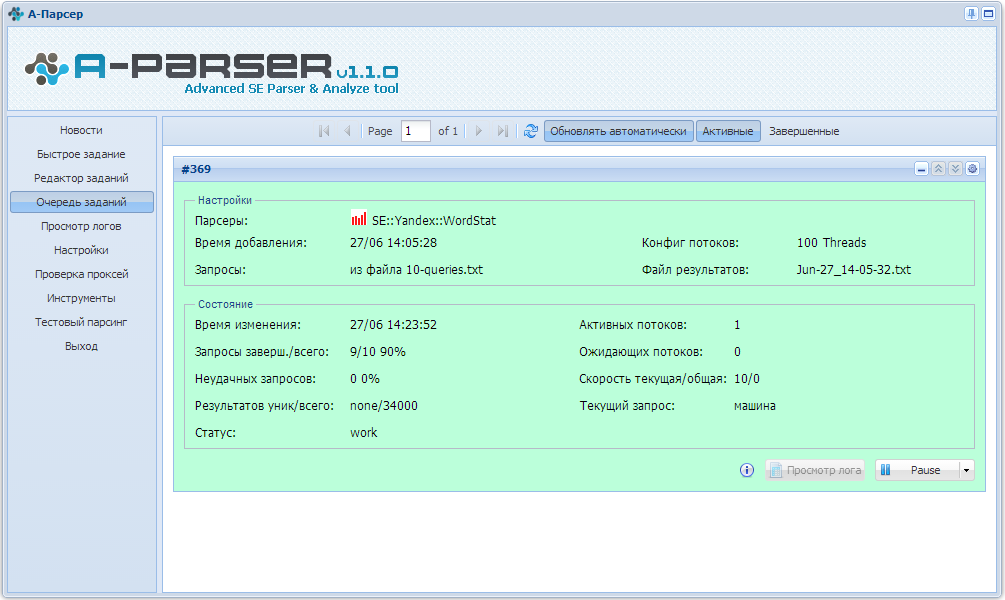
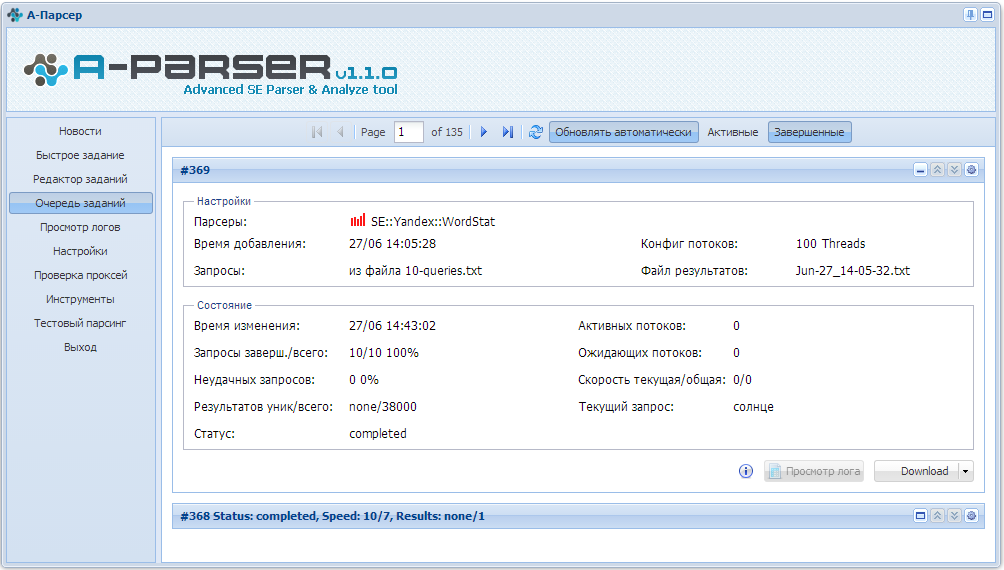
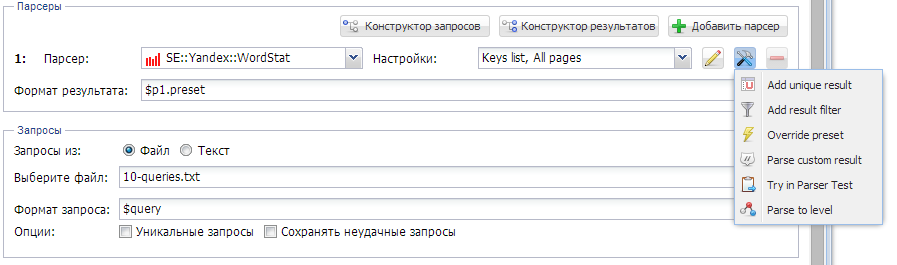
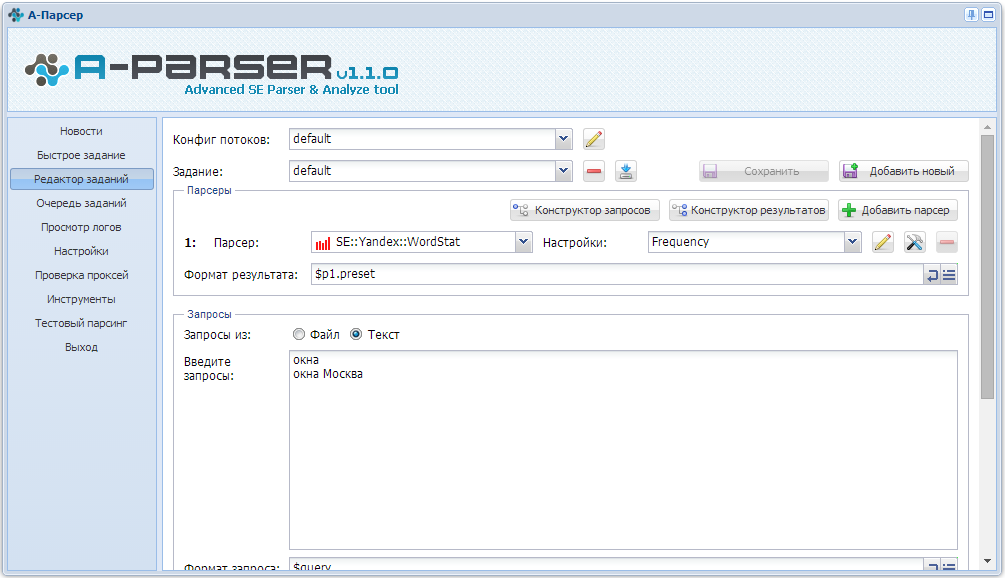
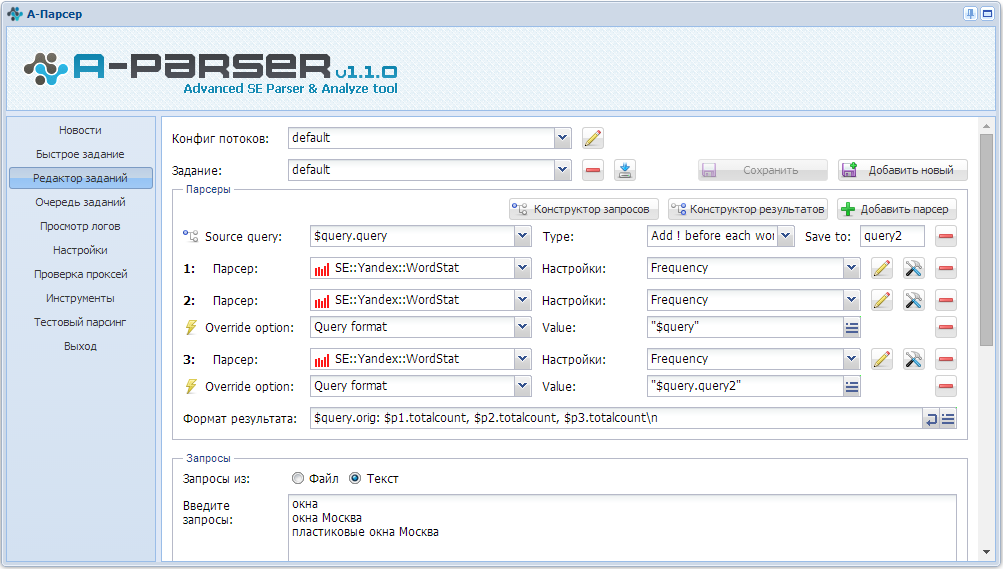
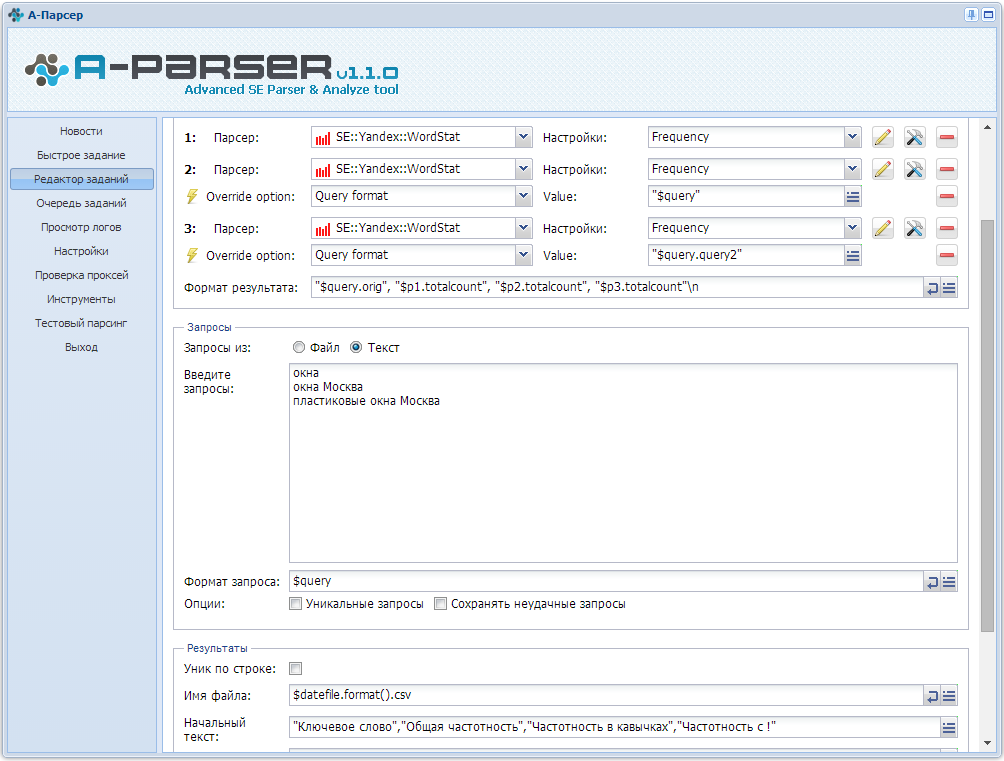
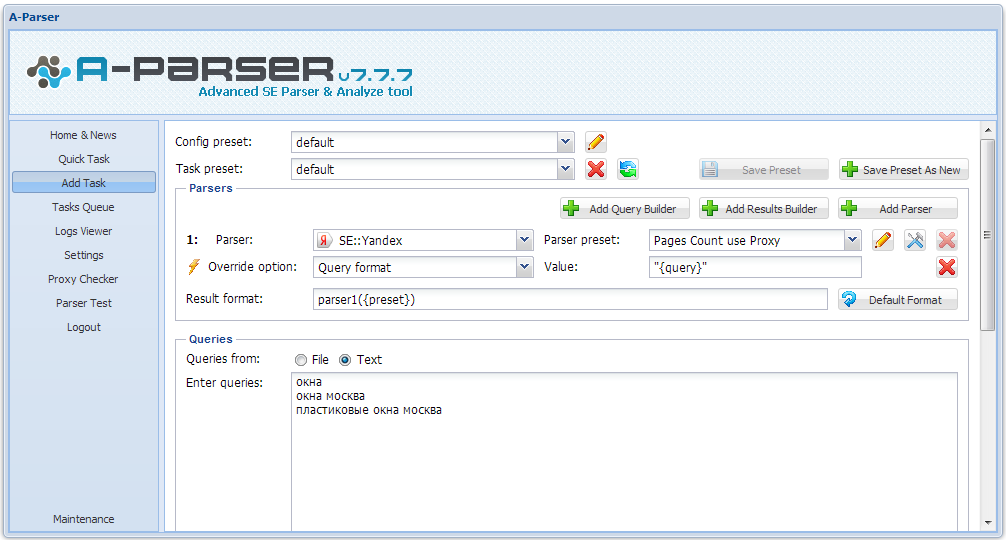
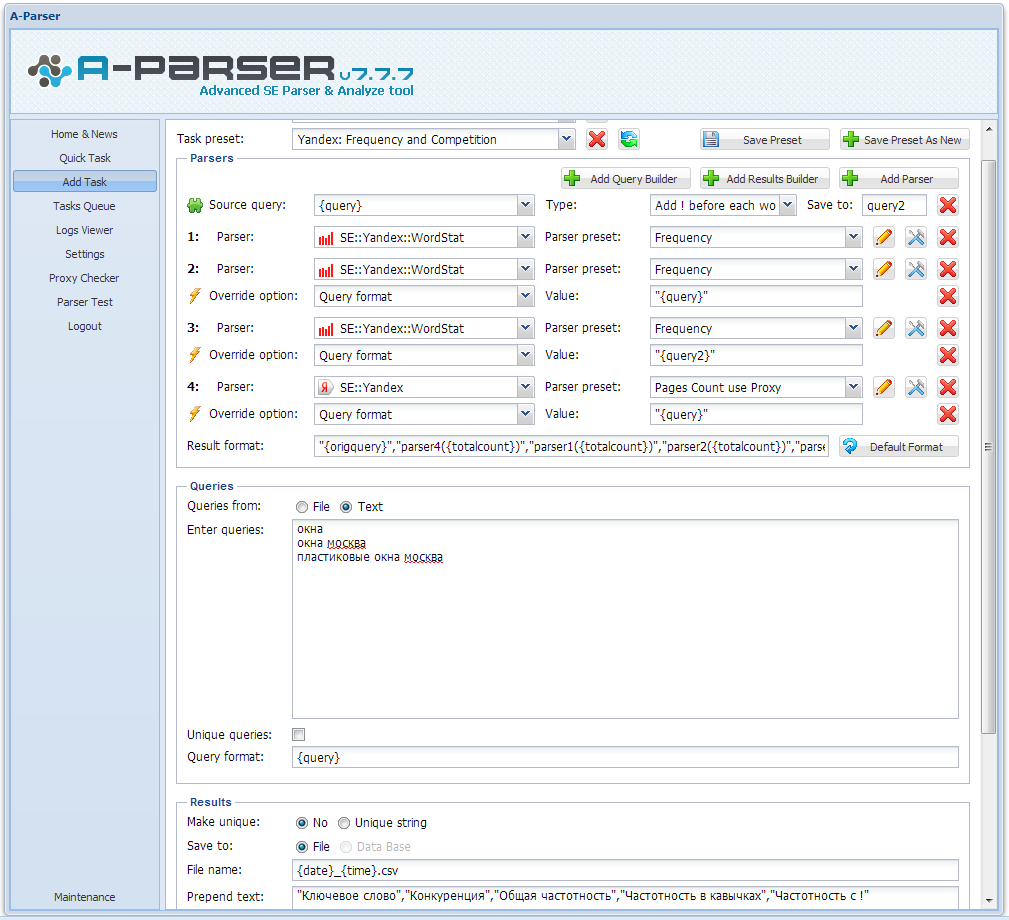
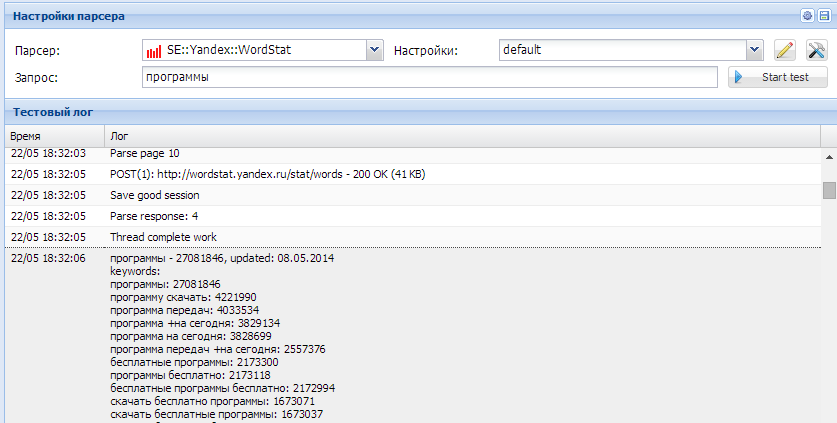
1. Как организовать парсинг Вортстата по указанным кеям (в поле, файле).
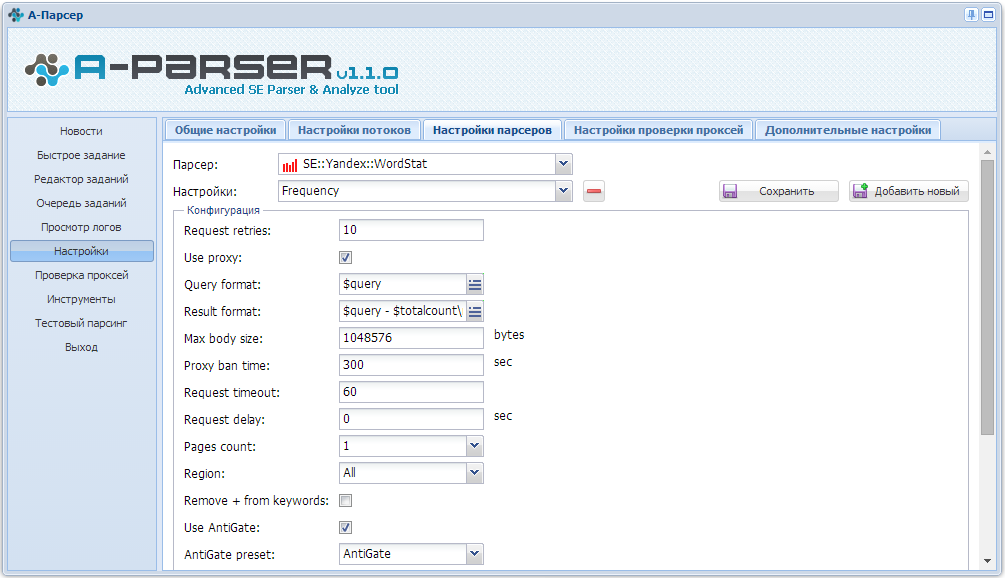
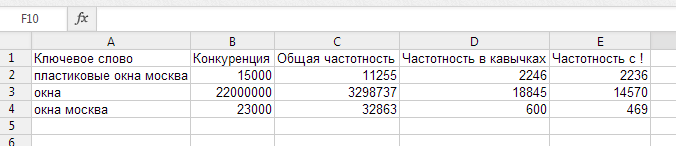
2. Как собирать частотку следующих видов: Общая частотка по кею, Частотка в ковычках (словоформы) "слово" и частотка точного вхождения "!слово"
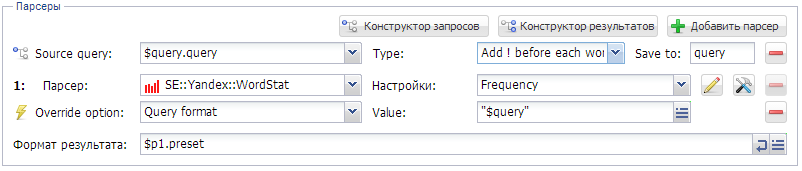
3. Как собирать конкуренцию (кон-ку) по яндексу в ковычка "кей", то есть реально количество сайтов по конкретному кею.
Интересует по сути все, возможные пошаговые скрины, регулярки которые надо заюзать") Буду очень благодарен всем откликнувшимся.
Буду очень благодарен всем откликнувшимся.
Приобрел А-парсер и хочу отметить что довольное интересная реализация для декстоп программ с использованием регулярок. И сразу же возникло куча вопросов хотя и надо освоить основные 3-5 функций ради чего и приобреталось ПО. По симу прошу помоши у всех кто разбирается в софте расписать желательно пошаговое, потому как думаю не только мне будет полезна данная инфа.
Сами вопросы:
1. Как организовать парсинг Вортстата по указанным кеям (в поле, файле).
2. Как собирать частотку следующих видов: Общая частотка по кею, Частотка в ковычках (словоформы) "слово" и частотка точного вхождения "!слово"
3. Как собирать конкуренцию (кон-ку) по яндексу в ковычка "кей", то есть реально количество сайтов по конкретному кею.
Интересует по сути все, возможные пошаговые скрины, регулярки которые надо заюзать
Буду очень благодарен всем откликнувшимся.
 SE::Yandex::Register
SE::Yandex::Register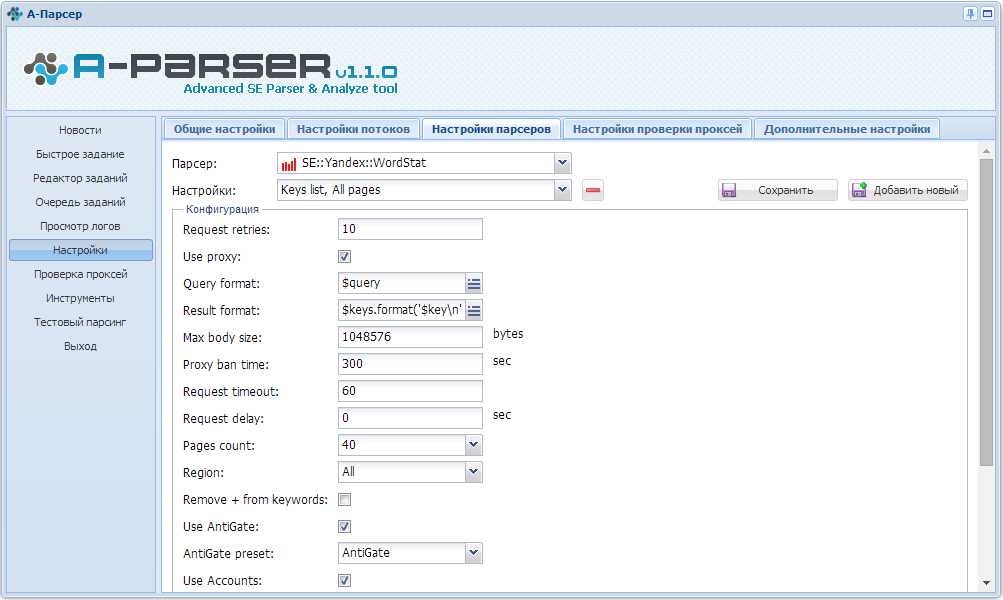








")