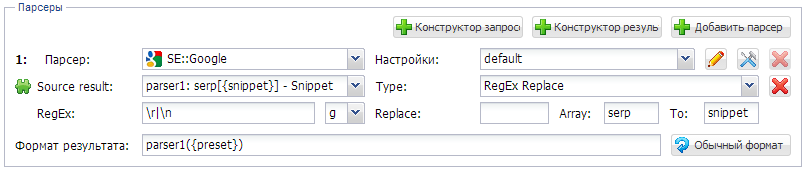
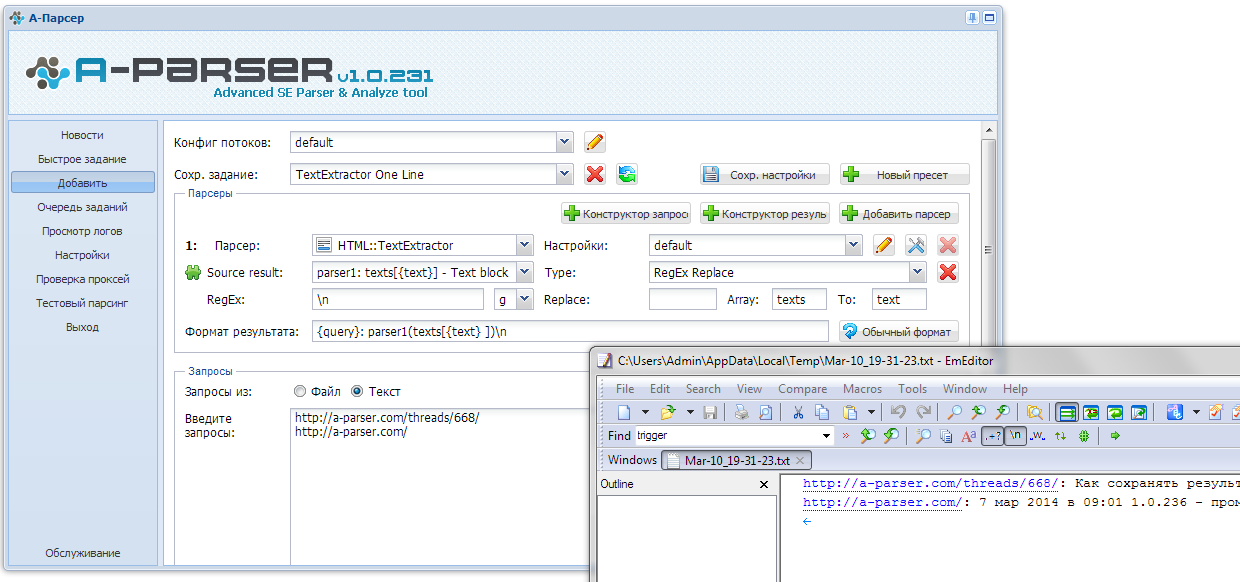
Частенько попадаются сайты, где нужная информация в html коде странички находится на отдельной строке между неуникальными тегами. Например, имеем такой кусок кода:
Как построить регулярку, чтобы телефоны сохранились в одной строке?
Сейчас делаю таким образом:
В результате, в текстовом файле телефоны сохраняются в двух строчках вместе с куском html кода:
Приходится потом чистить файл и другим скриптом перезаписывать записи в одну строку. Возможно ли сразу средствами A-Parser'а сохранять подобные записи в одну строку без кусков кода ?
Код:
<tr>
<td class="lightbg">Телефон:</td>
<td class="lightbg"> <b>(3822)63-31-39</b></td>
</tr>
<tr>
<td class="lightbg">Мобильный:</td>
<td class="lightbg"> <b>8-952-803-14-22</b></td>
</tr>Как построить регулярку, чтобы телефоны сохранились в одной строке?
Сейчас делаю таким образом:
Код:
Parse Custom Result : Телефон:</td>(.*?)</b>
Parse Custom Result : Мобильный:</td>(.*?)</b>В результате, в текстовом файле телефоны сохраняются в двух строчках вместе с куском html кода:
Код:
<td class="lightbg"> <b>(3822)63-31-39
<td class="lightbg"> <b>8-952-803-14-22Приходится потом чистить файл и другим скриптом перезаписывать записи в одну строку. Возможно ли сразу средствами A-Parser'а сохранять подобные записи в одну строку без кусков кода ?