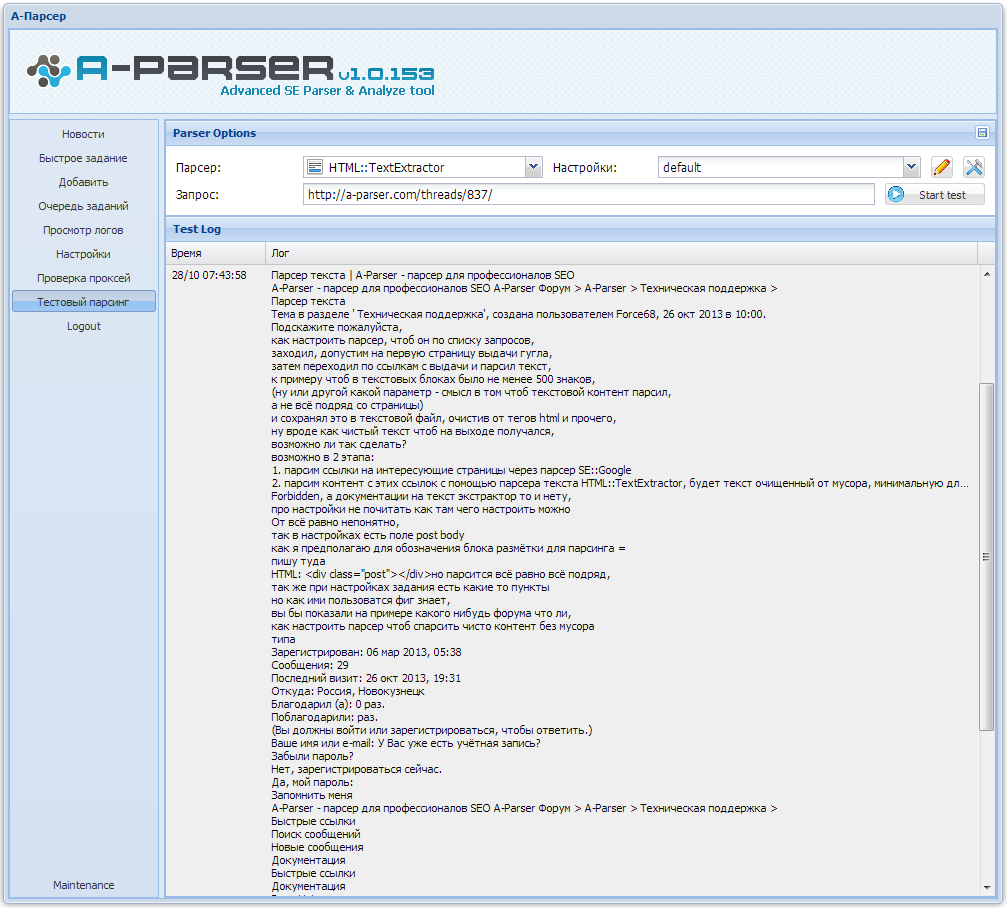
Подскажите пожалуйста,
как настроить парсер, чтоб он по списку запросов,
заходил, допустим на первую страницу выдачи гугла,
затем переходил по ссылкам с выдачи и парсил текст,
к примеру чтоб в текстовых блоках было не менее 500 знаков,
(ну или другой какой параметр - смысл в том чтоб текстовой контент парсил,
а не всё подряд со страницы)
и сохранял это в текстовой файл, очистив от тегов html и прочего,
ну вроде как чистый текст чтоб на выходе получался,
возможно ли так сделать?
как настроить парсер, чтоб он по списку запросов,
заходил, допустим на первую страницу выдачи гугла,
затем переходил по ссылкам с выдачи и парсил текст,
к примеру чтоб в текстовых блоках было не менее 500 знаков,
(ну или другой какой параметр - смысл в том чтоб текстовой контент парсил,
а не всё подряд со страницы)
и сохранял это в текстовой файл, очистив от тегов html и прочего,
ну вроде как чистый текст чтоб на выходе получался,
возможно ли так сделать?
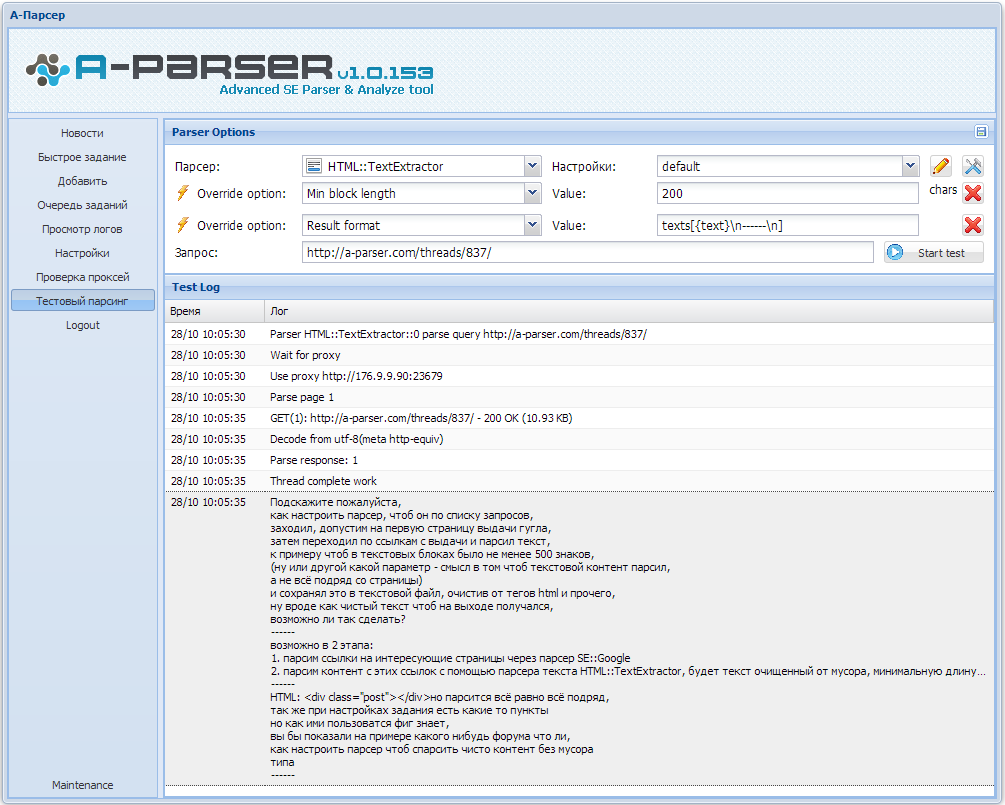
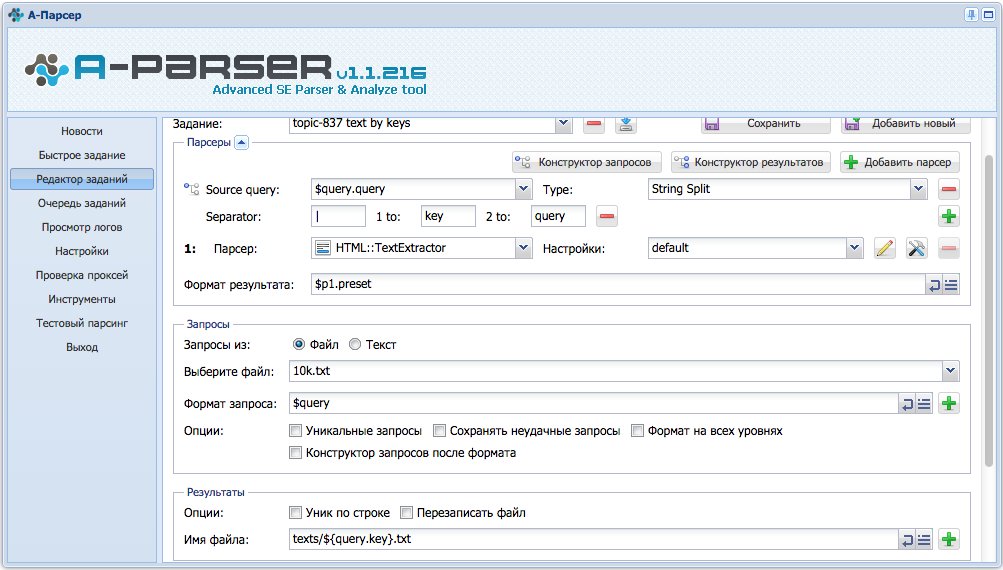
 настроить можно
настроить можно