Настройки
A-Parser cодержит следующие группы настроек:
- Общие настройки - основные настройки программы: язык, пароль, параметры обновлений, количество активных заданий
- Настройки потоков - настройки потоков и методов уникализации для заданий
- Настройки парсеров - возможность настроить каждый отдельный парсер
- Настройки проверки прокси - количество потоков и все настройки для проксичекера
- Дополнительные настройки - опциональные настройки для продвинутых пользователей
- Пресеты заданий - сохранение заданий для последующего использования
Все настройки (кроме общих и дополнительных) сохраняются в т.н. пресеты - наборы заранее сохраненных настроек, например:
- Разные пресеты настроек для парсера
 SE::Google - один для парсинга ссылок с максимальной глубиной 10 страниц, другой - для оценки конкуренции по запросу, глубина парсинга 1 страница
SE::Google - один для парсинга ссылок с максимальной глубиной 10 страниц, другой - для оценки конкуренции по запросу, глубина парсинга 1 страница - Разные пресеты настроек проксичекера - отдельные для HTTP и SOCKS прокси
Для всех настроек существует пресет по умолчанию (default), его нельзя изменить, все изменения должны сохраняться в пресетах с новыми именами.
Общие настройки
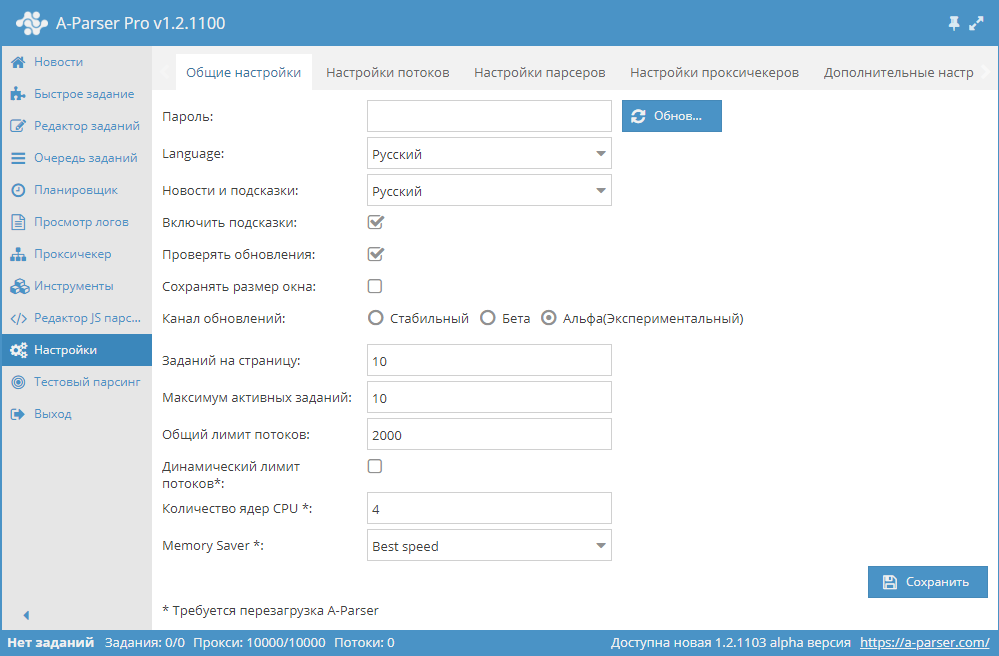
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Пароль | Нет пароля | Задать пароль для входа в А-Парсер |
| Language | English | Язык интерфейса |
| Новости и подсказки | English | Язык новостей и подсказок |
| Включить подсказки | ☑ | Определяет отображать ли подсказки |
| Проверять обновления | ☑ | Определяет отображать ли информацию о доступности нового обновления в Статус баре |
| Сохранять размер окна | ☐ | Определяет сохранять ли размер окна |
| Канал обновлений | Стабильный | Выбор канала обновлений (Стабильный, Бета, Альфа) |
| Заданий на страницу | 5 | Количество заданий на страницу в Очереди заданий |
| Максимум активных заданий | 1 | Максимальное количество активных заданий |
| Общий лимит потоков | 10000 | Общий лимит потоков в А-Парсере. Задание не запустится, если общий лимит потоков меньше кол-ва потоков в задании |
| Динамический лимит потоков | ☐ | Определяет использовать ли Динамический лимит потоков |
| CPU ядер(обработка заданий) | 2 | Поддержка обработки заданий на разных ядрах процессора (только для лицензии Enterprise). Детальней описано ниже |
| CPU ядер(обработка результатов) | 4 | Несколько ядер используется только при фильтрации, Конструкторе результатов, Parse custom result (все типы лицензий) |
| Memory Saver | Best speed | Позволяет определять как много памяти может использовать парсер (Best speed / Medium memory usage / Save max memory). Подробнее... |
CPU ядер (обработка заданий)
Поддержка обработки заданий на разных ядрах процессора, данная возможность доступна только для лицензии Enterprise
Данная опция ускоряет (многократно) обработку нескольких заданий в очереди (Настройки -> Максимум активных заданий), при этом никак не ускоряет выполнение одного задания
Также реализовано интеллектуальное распределение заданий по рабочим ядрам на основе загрузки CPU каждого процесса Количество используемых ядер процессора задается в настройках, по умолчанию - 2, максимально - 32
Как и в случае с потоками, к выбору числа ядер лучше подходить экспериментальным путем, разумным будут значения 2-3 ядра для 4ых ядерных процессоров, 4-6 для восьмиядерных и т.д. Стоит учитывать что при большом количестве ядер и большой их загруженности может возникнуть 100% загрузка основного управляющего процесса (aparser/aparser.exe), при которой дальнейшее увеличения процессов для обработки заданий вызовет лишь общее замедление или нестабильную работу. Также стоит учитывать что каждый процесс обработки заданий может создавать дополнительную нагрузку вплоть до 300% (т.е. нагружать по 100% одновременно 3 ядра), данная особенность связана с многопоточной обработкой сборки мусора в движке JavaScript v8
Настройки потоков
Работа A-Parser построена по принципу многопоточной обработки данных. Парсер параллельно выполняет задачи в отдельных потоках, количество которых можно гибко варьировать в зависимости от конфигурации сервера.
Описание работы потоков
Давайте разберёмся что такое потоки на практике. Допустим вам необходимо составить отчет за три месяца.
Вариант 1
Вы можете составить отчёт в начале за 1-й месяц, затем за 2-й, а затем за 3-ий. Это пример однопоточной работы. Задачи решаются по очереди.
Вариант 2
Нанять троих бухгалтеров, которые будут составлять отчёты каждый по одному месяцу. А затем по получении результатов от троих сделать уже общий отчёт. Это пример многопоточной работы. Задачи решаются одновременно.
Как видно из этих примеров, многопоточная работа позволяет выполнить задачу быстрее, но в то же время требует больше ресурсов (нам нужно 3 бухгалтера вместо 1-го). Аналогично работает многопоточность и в А-Парсере. Допустим, вам нужно парсить информацию с нескольких ссылок:
- при одном потоке приложение будет парсить каждый сайт по очереди
- при работе в несколько потоков каждый будет обрабатывать свою ссылку, по завершению которой будет приступать к следующей необработанной в списке
Таким образом во втором варианте вся задача будет выполнена значительно быстрее, но при этом требуется больше ресурсов сервера, поэтому рекомендуется соблюдать Системные требования
Настройка потоков
Настройка потоков в А-Парсере осуществляется отдельно для каждого задания, в зависимости от параметров которые требуются для его выполнения. По умолчанию доступно 2 конфига потоков: на 20 и 100 потоков, для default и 100 Threads соответственно.
Для того чтобы попасть в настройки выбранного конфига, нужно нажать на иконку карандаша ![]() , после чего откроются его настройки.
, после чего откроются его настройки. 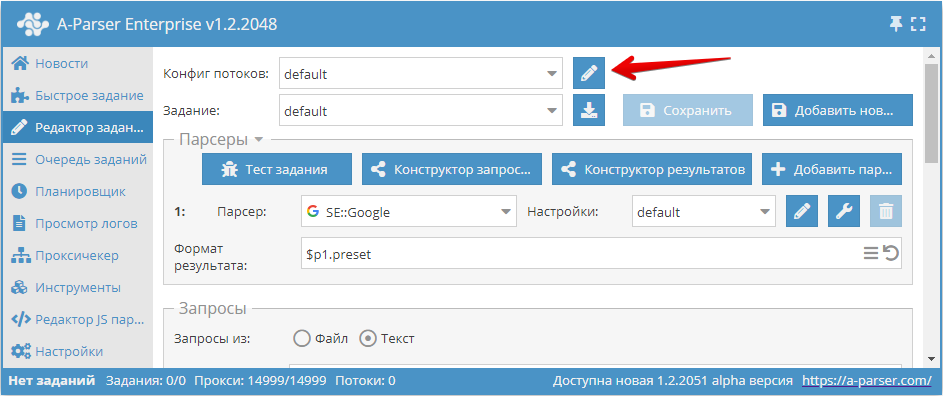
Также перейти к настройкам потоков можно через пункт меню: Настройки -> Настройки потоков
Здесь мы можем:
- создать новый конфиг со своими собственными настройками и сохранить его под своим названием (кнопка Добавить новый)
- внести изменения в существующий конфиг, выбрав его из выпадающего списка (кнопка Сохранить)
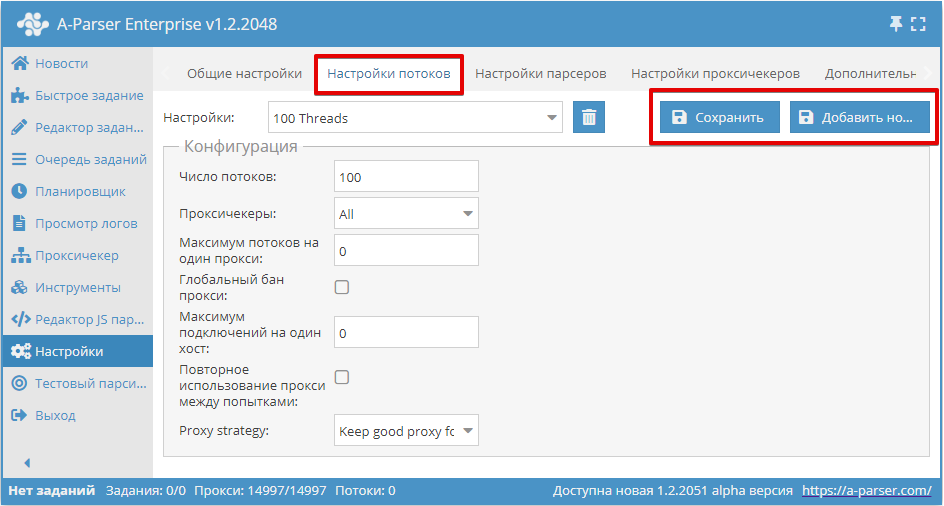
Число потоков (Threads count)
Данный параметр задает количество потоков, в которое будет работать задание, запущенное с этим конфигом. Количество потоков может быть любое, но нужно учитывать возможности вашего сервера, а также ограничение тарифа прокси, если такое ограничение предусмотрено. Например для наших прокси можно указать не больше выбранного тарифа.
Также важно помнить, что общее кол-во потоков в парсере равно сумме работающих заданий и включенных проксичекеров с проверкой прокси. Например, если запущено одно задание на 20 потоков и два задания по 100 потоков каждое, а также работает один проксичекер, в котором включена проверка прокси в 15 потоков, то суммарно парсер будет использовать 20+100+100+15=235 потоков. При этом, если тариф прокси расчитан на 200 потоков, то будет множество неудачных запросов. Чтобы их избежать, нужно понизить используемое кол-во потоков. Например, отключить проверку прокси (если она не нужна, то это сэкономит 15 потоков) и понизить кол-во потоков в каком-то из задания еще на 20 потоков. Таким образом для одного из работающих заданий нужно создать конфиг на 80 потоков, остальные оставить как есть
Проксичекеры (Proxy Checkers)
Этот параметр дает возможность выбора проксичекера с определенными настройками. Здесь можно выбрать параметр All, который означает использование всех работающих проксичекеров, либо только те, которые нужно использовать в задании (доступен выбор нескольких позиций)
Эта настройка позволяет запускать задание только с нужными проксичекерами. Процесс настройки проксичекера рассмотрен здесь
Максимум потоков на один прокси (Max threads per proxy)
Здесь задается максимальное количество потоков, на которых одновременно будет использоваться один и тот же прокси. Позволяет задать разные параметры, например работу 1 поток = 1 прокси.
По-умолчанию, данный параметр равен 0, что отключает эту функцию. В большинстве случаев этого достаточно. Но если требуется ограничить нагрузку на каждую прокси, тогда имеет смысл поменять значение
Глобальный бан прокси (Global proxy ban)
Все задания запущенные с этой опцией имеют общую базу бана прокси. Особенность этого параметра в том, что список забаненных прокси для каждого парсера общий для всех работающих заданий.
Например, забаненный прокси в SE::Google в задании 1 будет также забанен для SE::Google и в задании 2, но при этом он может свободно работать в  SE::Yandex в обоих заданиях
SE::Yandex в обоих заданиях
Максимум подключений на один хост (Max connections per host)
Данный параметр указывает максимальное количество соединений на хост, предназначено для уменьшения нагрузки на сайт при парсинге с него информации. По сути, указание этого параметра дает возможность контролировать количество запросов в один момент, на каждый конкретный домен. Включение этого параметра распространяется на задание, если запускать несколько заданий одновременно с одинаковым конфигом потоков, то лимит будет считаться для всех заданий.
По умолчанию этот параметр имеет значение 0, т.е. отключен.
Повторное использование прокси между попытками (Reuse proxy between retries)
Эта настройка отключает проверку на уникальность прокси для каждой попытки, а так же не будет работать бан прокси. Это в свою очередь означает возможность использовать 1 прокси для всех попыток.
Данный параметр рекомендуется включать например в тех случаях, когда планируется использовать 1 прокси, при каждом подключении к которому меняется выходной IP.
Стратегия использования прокси (Proxy strategy)
Позволяет управлять стратегией выбора прокси при использовании сессий: сохранять прокси из успешного запроса для следующего запроса или всегда использовать рандомную прокси.
Рекомендации
В этой статье рассмотрены все настройки, которые дают возможность управлять потоками. Стоит отметить, что при настройках конфига потоков не обязательно задавать все параметры, указанные в статье, достаточно задать только те, которые обеспечат получение корректного результата. Обычно нужно менять только Threads count, остальные настройки можно оставлять по умолчанию.
Настройки парсеров
Каждый парсер имеет множество настроек и позволяет сохранять разные наборы настроек в пресеты. Система пресетов позволяет использовать один и тот же парсер с разными настройками в зависимости от ситуации, разберем на примере парсера SE::Google:
Пресет 1: "Парсинг максимального числа ссылок"
- Количество страниц (Pages count):
10
Таким образом парсер будет собирать максимальное количество ссылок, переходя по всем страницам поисковой выдачи
Пресет 2: "Парсинг конкуренции по запросу"
- Количество страниц (Pages count):
1 - Формат результата (Results format):
$query: $totalcount\n
В данном случае мы получаем количество результатов выдачи по запросу (конкуренция запроса) и для большей скорости нам достаточно спарсить только первую страницу
Создание пресетов
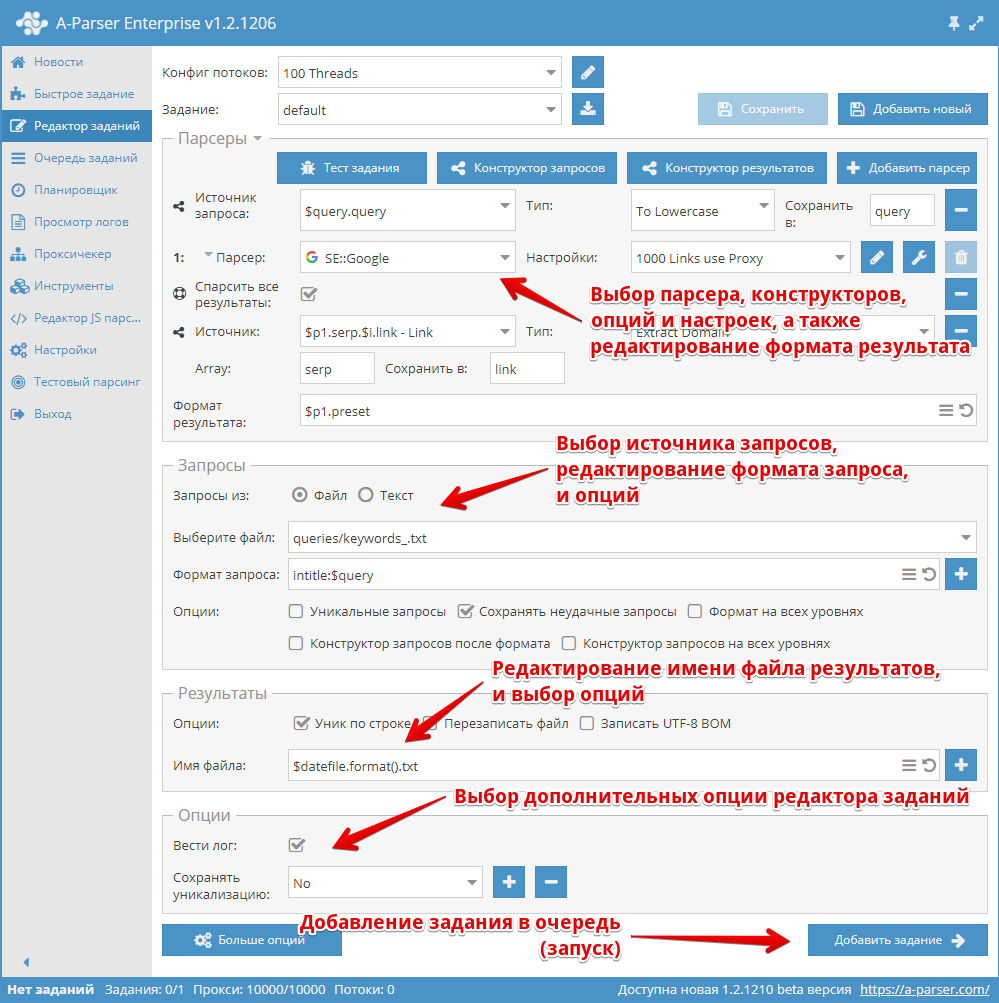
Создание пресет начинается с выбора парсера/парсеров и определением результата, который нужно получить.
Далее нужно понять какие будут входные данные для выбранного парсера, на скриншоте выше выбран парсер SE::Google, у него входные данне это любые строки как если бы вы что-то искали в браузере. Можно выбрать файл запросов или ввести запросы в текстовое поле.
Теперь нужно переопределить настройки (выбрать опции) для парсера, добавить уникализацию. Можно использовать конструктор запросов, если нужно обработать запросы. Или использовать конструктор результатов, если нужно обработать каким-то образом результаты.
Далее нужно обратить внимание на редактирование имени файла результатов, и если нужно поменять на своё усмотрение.
Последним пунктом является выбор дополнительных опций, в особенности опция Вести лог. Очень полезная если вы хотите узнать причину ошибки парсинга.
После всего этого нужно сохранить пресет и добавить в очередь заданий.
Переопределение настроек
Override preset - быстрое переопределение настроек для парсера, эту опцию можно добавить непосредственно в Редакторе заданий. В один клик можно добавить несколько параметров. В списке настроек указаны дефолтные значения, а если опция выделена жирным то значит она уже переопределена в пресете
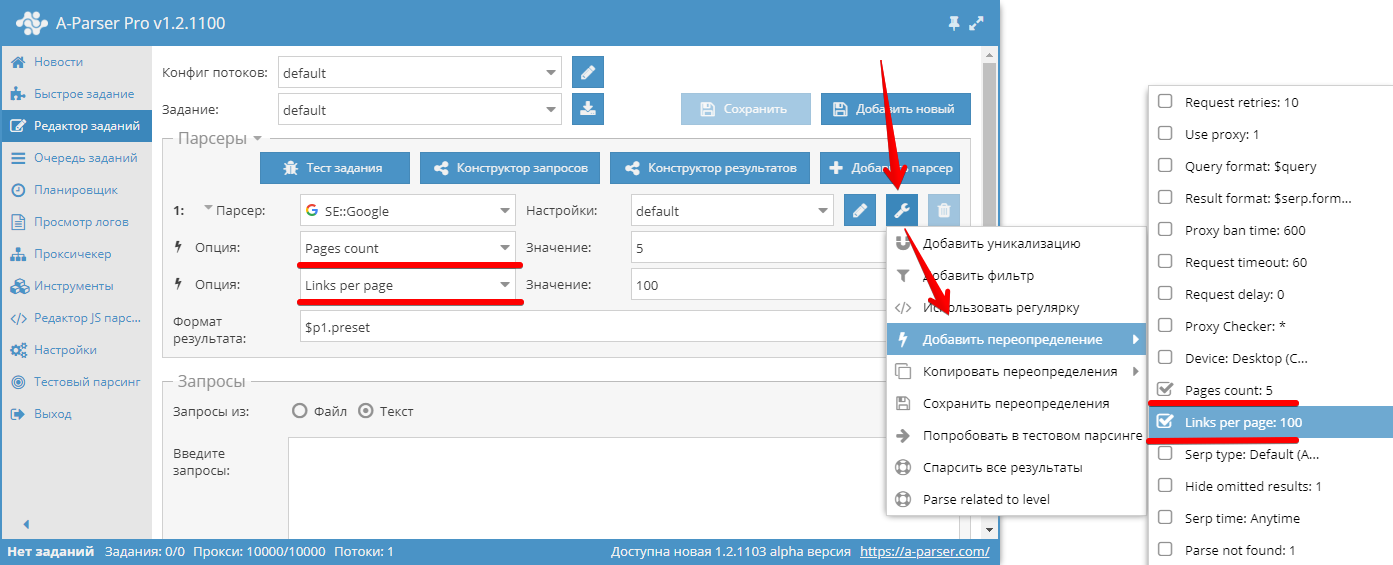
В данном примере переопределена опция Pages count (Количество страниц) — задано значение 5.
В задании можно использовать неограниченное число опций Override preset, но если изменений много, удобнее создать новый пресет и в него сохранить все изменения.
Также сохранить переопределения можно легко с помощью функции Сохранить переопределения. Они будут сохранены как отдельный пресет для выбранного парсера.
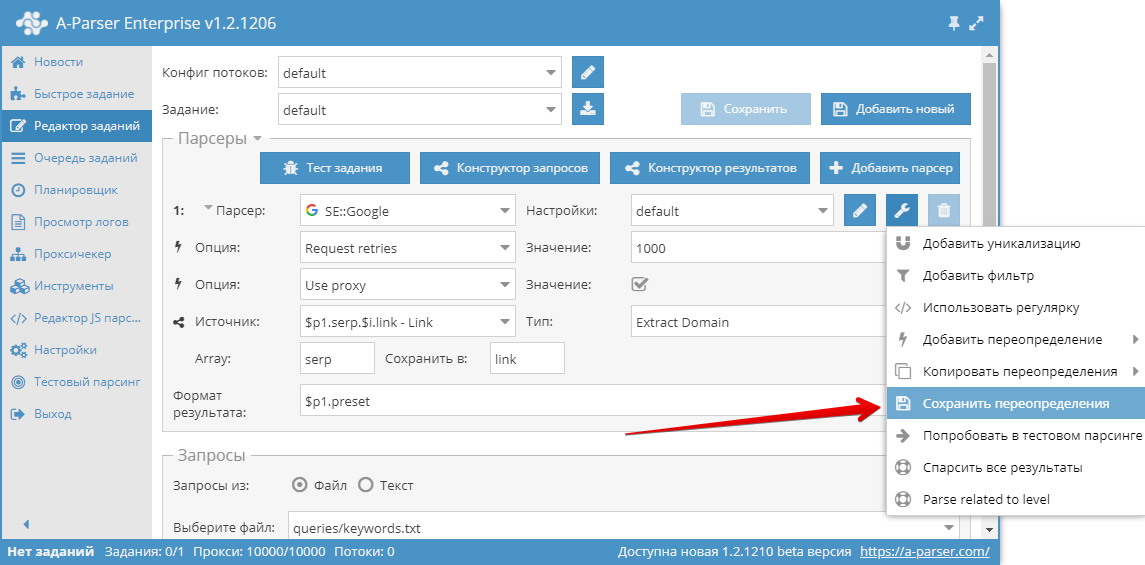
После чего в будущем достаточно просто выбрать из списка этот сохраненный пресет и использовать.
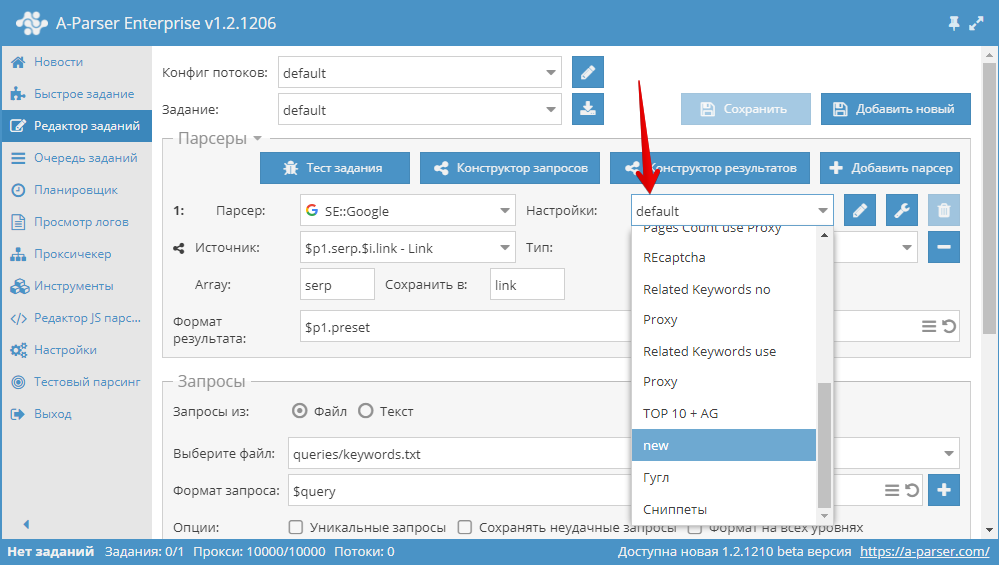
Общие настройки для всех парсеров
Каждый парсер имеет свой набор настроек, информацию по настройкам каждого парсера вы можете найти в соответсвующем разделе
В данной таблице мы представили общие настройки для всех парсеров
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Request retries | 10 | Количество попыток на каждый запрос, если запрос не удаётся выполнить за указанное число попыток то он считается неудачным и пропускается |
| Use proxy | ☑ | Определяет использовать ли прокси |
| Query format | $query | Формат запроса |
| Result format | У каждого парсера свое значение | Формат вывода результата |
| Proxy ban time | У каждого парсера свое значение | Время бана прокси в секундах |
| Request timeout | 60 | Максимальное время ожидания запроса в секундах |
| Request delay | 0 | Задержка между запросами в секундах, можно задавать случайное значение в промежутке, например 10,30 - задержка от 10 до 30 секунд |
| Proxy Checker | All | Прокси от каких чекеров должны использоваться (выбор между всеми или перечисление конкретных) |
Общие для всех парсеров работающих по протоколу HTTP
| Название параметра | Значение по умолчанию | Описание |
|---|---|---|
| Max body size | У каждого парсера свое значение | Максимальный размер страницы выдачи в байтах |
| Use gzip | ☑ | Определяет использовать ли сжатие передаваемого трафика |
| Extra query string | Позволяет указать дополнительные параметры в строку запроса |
Настройки по умолчанию для каждого парсера могут отличаться. Они хранятся в пресете default в настройках каждого парсера.
Настройки проксичекеров
Подробнее о Настройке проксичекеров
Дополнительные настройки
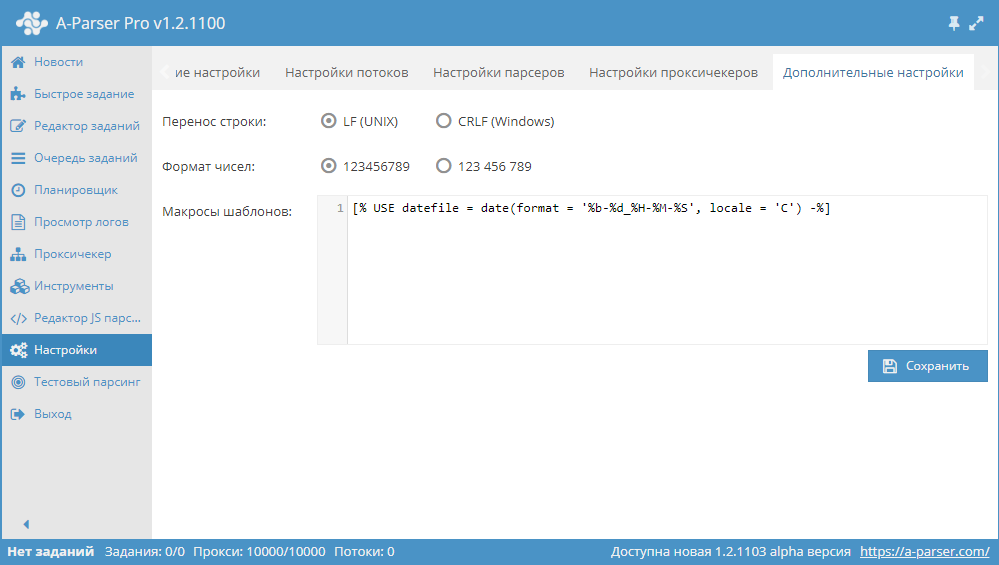
- Перенос строки позволяет выбрать между Unix и Windows вариантом окончания строк при сохранении результатов в файл
- Формат чисел - задает как выводить числа в интерфейсе A-Parser'а
- Макросы шаблонов