Порядок обработки запросов
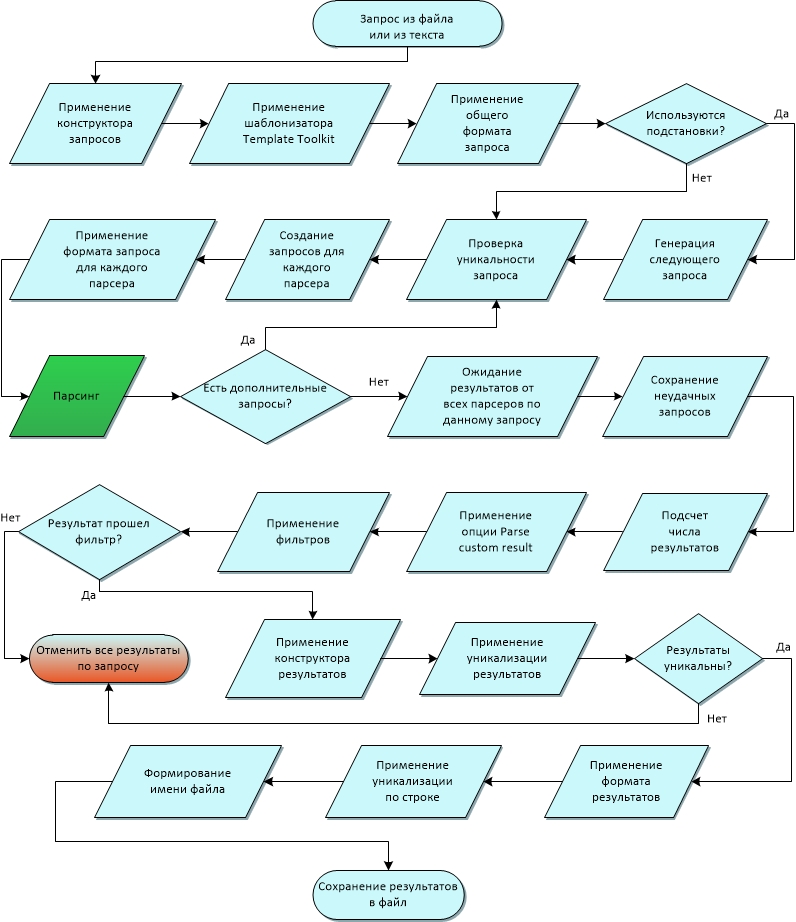
В A-Parser существует множество функций и возможностей, на данной диаграмме представлен порядок обработки запроса от его чтения из файла(или текста) до сохранения конечного результата в файл
Схематически порядок обработки запроса
Примечания
- При фильтрации и уникализации результатов запрос и его результаты отменяются целиком если в качестве сравнения используется простой результат, если в сравнении используется массив то удаляются элементы из этого массива
- Многие шаги на диаграмме опциональны и зависят от настроек указанных в Редакторе заданий
- Дополнительные запросы могут появляться при использовании опций Parse all result и Parse to level. Все дополнительные запросы имеют следующий уровень по отношению к запросу от которого были созданы дополнительные запросы, отсчет уровней начинается с нуля, т.е. исходные запросы из файла или текста всегда имеют уровень 0. Запросы после применения подстановок также имеют уровень 0
Неудачные запросы
Запрос считается неудачным и пропускается, если его не удалось выполнить за указанное число попыток.
Как определить, почему запрос неудачный? Включите ведение лога или запустите Тест задания. Все ошибки логируются. Изучив лог, вы сможете понять, что пошло не так.
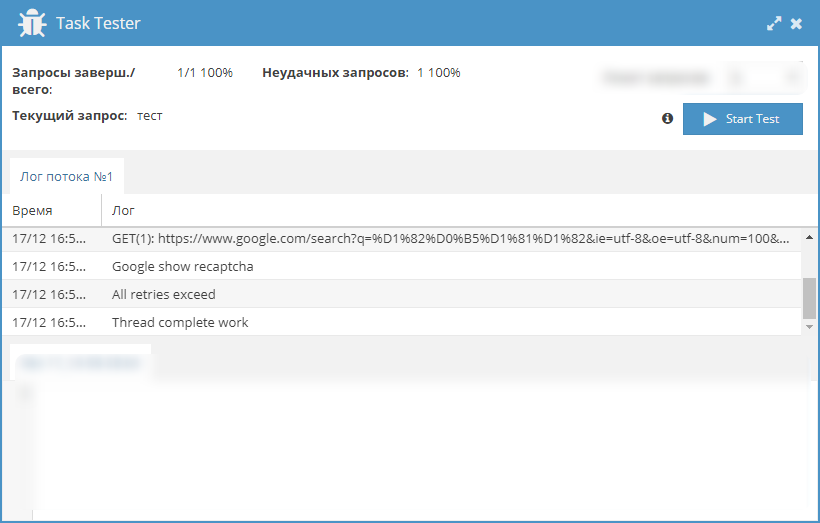
Пример неудачного запроса. Логи подсказывают, что запрос не удалось выполнить из-за капчи, а попытки закончились. В этом случае может помочь подключения сервиса разгадывания или увеличение числа попыток (только если вы парсите с прокси, в ином случае увеличивать попытки бесполезно).
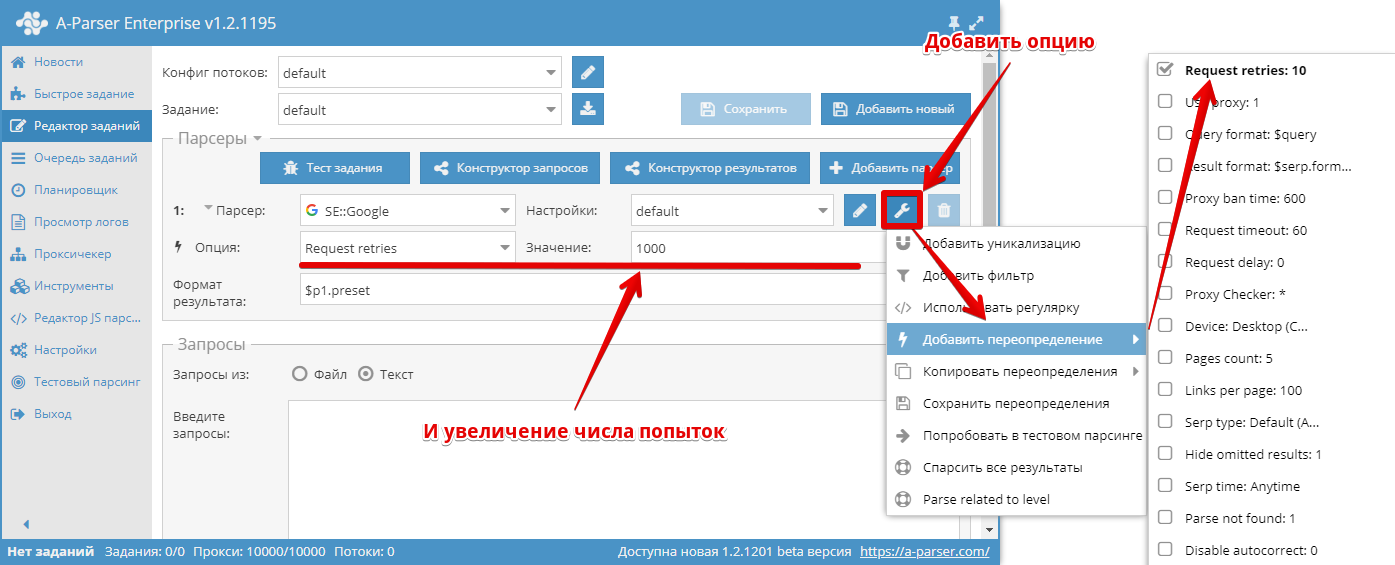
Как увеличить число попыток? Нужно переопределить опцию Request retries и выставить значение больше.