HTTP запросы (+работа с куками, прокси, сессии)
Методы базового класса
Чтобы собрать данные с веб-страницы нужно выполнить HTTP запрос. В JavaScript API v2 А-Парсера реализован легкий в
использовании метод выполнения HTTP запросов, который в ответ возвращает JSON объект в зависимости от указанных
аргументов метода. Далее вы узнаете: как производится HTTP запрос, какие аргументы и опции имеет метод, результаты
указанных опций, как указывать условие успешности HTTP запроса, и другое.
Также описаны методы позволяющие легко манипулировать куками, прокси и сессией в создаваемом парсере. После успешного выполнения HTTP запроса, или перед выполнением, вы можете установить/изменить данные прокси/кук/сессии для выполнения HTTP запросов или сохранить для выполнения другим потоком с помощью Менеджера сессий.
Данные методы наследуются от BaseParser и являются основой для создания собственных парсеров
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Получение HTTP ответа по запросу, в качестве аргументов указывается:
method- метода запроса (GET, POST...)url- ссылка для запросаqueryParams- хэш с get параметрами или хэш с телом post-запросаopts- хэш с опциями запроса
opts.check_content
check_content: [ условие1, условие2, ...] - массив условий для проверки получаемого контента, если проверка не
проходит, то запрос будет повторен с другим прокси.
Возможности:
- использование в качестве условий строк (поиск по вхождению строки)
- использование в качестве условий регулярных выражений
- использование своих функций проверок, в которые передаются данные и хедеры ответа
- можно задать сразу несколько разных типов условий
- для логического отрицания поместите условие в массив, т.е.
check_content: ['xxxx', [/yyyy/]]означает что запрос будет считаться успешным, если в полученных данных содержится подстрокаxxxxи при этом регулярное выражение/yyyy/не находит совпадений на странице
Для успешного запроса должны пройти все указанные в массиве проверки
Пример (в комментариях указано что нужно для того, чтобы запрос считался успешным):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // на полученной странице должно сработать это регулярное выражение
['XXXX'], // на полученной странице не должно быть этой подстроки
'</html>', // на полученной странице должна быть такая подстрока
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // эта функция должна вернуть true
]
});
opts.decode
decode: 'auto-html' - автоматическое определение кодировки и преобразование в utf8
Возможные значения:
auto-html- на основе заголовков, тегов meta и по содержимому страници (оптимальный рекомендуемый вариант)utf8- указывает что документ в кодировке utf8<encoding>- любая другая кодировка
opts.headers
headers: { ... } - хэш с заголовками, название заголовка задается в нижнем регистре, можно указать в т.ч. cookie.
Пример:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - позволяет переопределить порядок сортировки заголовков
opts.onlyheaders
onlyheaders: 0 - определяет чтение data, если включено (1), получает только заголовки
opts.recurse
recurse: N - максимальное число переходов по редиректам, по умолчанию 7, используйте 0 для отключения перехода по
редиректам
opts.proxyretries
proxyretries: N - число попыток выполнения запроса, по умолчанию берется из настроек парсера
opts.parsecodes
parsecodes: { ... } - перечень кодов HTTP ответов, которые парсер будет считать удачными, по умолчанию берется из
настроек парсера. Если указать '*': 1 то все ответы будут считаться удачными.
Пример:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - таймаут ответа в секундах, по умолчанию берется из настроек парсера
opts.do_gzip
do_gzip: 1 - определяет использовать ли компрессию (gzip/deflate/br), по умолчанию включено (1), для выключения
нужно задать значение 0
opts.max_size
max_size: N - максимальный размер ответа в байтах, по умолчанию берется из настроек парсера
opts.cookie_jar
cookie_jar: { ... } - хэш с куками. Пример хэша:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - указывает на номер текущей попытки, при использовании этого параметра встроенный обработчик попыток для
данного запроса игнорируется
opts.browser
browser: 1 - автоматическая эмуляция заголовков браузера (1 - включено, 0 - выключено)
opts.use_proxy
use_proxy: 1 - переопределяет использование прокси для отдельного запроса внутри JS парсера поверх глобального
параметра Use proxy (1 - включено, 0 - выключено)
opts.noextraquery
noextraquery: 0 - отключает добавление Extra query string к урлу запроса (1 - включено, 0 - отключено)
opts.save_to_file
save_to_file: file - позволяет скачать файл напрямую на диск, минуя запись в память. Вместо file указывается имя и
путь под каким сохранить файл. При использовании этой опции игнорируется все, что связано с data (проверка контента
в opts.check_content не будет выполнена, response.data будет пустой и т.д.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - автоматический обход JavaScript защиты CloudFlare используя браузер Chrome (1 - включено, 0 -
выключено)
Контроль Chrome Headless в этом случае осуществляется настройками парсера bypassCloudFlareChromeMaxPages
и bypassCloudFlareChromeHeadless, которые нужно указать в static defaultConf и static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - позволяет переходить по редиректам, объявленным через HTML метатег:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - позволяет задать функцию фильтрации перехода по редиректам, если функция
возвращает 1, то парсер перейдет по редиректу (учитывая параметр opts.recurse), при возврате 0 переход по
редиректам прекратиться:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - определяет переходить ли по стандартным редиректам (например http -> https
и/или www.domain.com -> domain.com), если указать 1 то парсер будет переходить по стандартным редиректам без учета
параметра opts.recurse
opts.http2
opts.http2: 0 - определяет переходить использовать ли протокол HTTP/2 при выполнении запросов, по умолчанию
используется HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - данная опция позволяет обходить бан сайтов по TLS отпечатку (1 - включено, 0 -
выключено)
opts.tlsOpts
tlsOpts: { ... } – позволяет
передавать настройки для
https соединений
await this.cookies.*
Работа с cookies для текущего запроса
.getAll()
Получение массива cookies
await this.cookies.getAll();
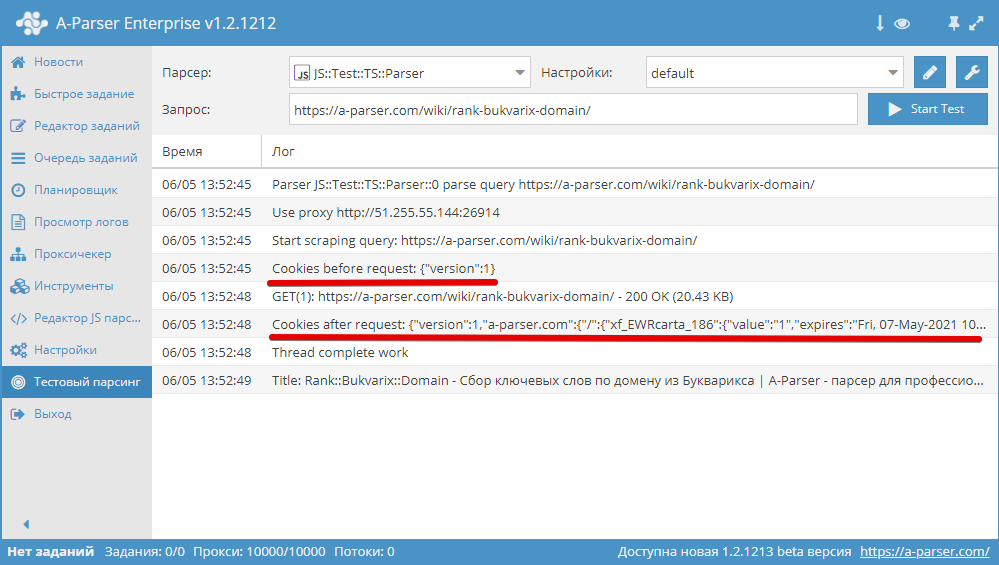
.setAll(cookie_jar)
Установка cookies, в качестве аргумента должен быть передан хэш с куками
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
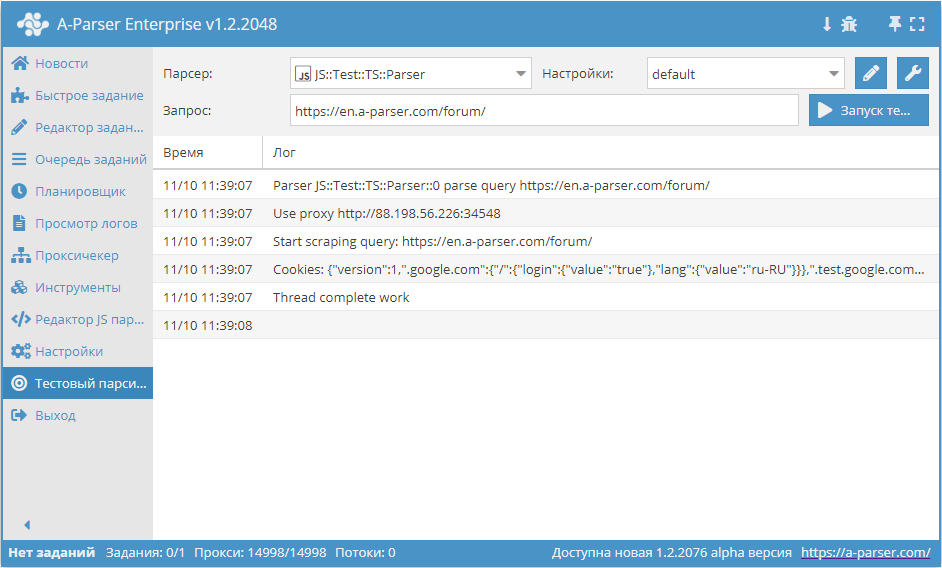
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - установка одиночного cookie.
Область видимости куки напрямую зависит от формата указанного домена, поэтому в host учитывается наличие точки перед хостом:
- если точка указана (
this.cookies.set('.domain.com', ...)), то кука будет использоваться для всех поддоменов (например a.domain.com, b.a.domain.com) - если хост указан без точки спереди (
this.cookies.set('site.com', ...)), то кука будет использоваться строго для указанного хоста (host-only cookie) и не передается на поддомены
Это различие критически важно, так как одновременное существование кук с точкой и без может привести к их дублированию и непредсказуемой работе сайта. Для корректной эмуляции всегда проверяйте, как именно целевой сайт устанавливает куки (с атрибутом Domain или без), и используйте соответствующий формат.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
await this.proxy.*
Работа с прокси
.next()
Сменить прокси на следующий, старый прокси больше не будет использован для текущего запроса
.ban()
Сменить и забанить прокси (необходимо использовать когда сервис блокирует работу по IP), прокси будет забанен на время,
указанное в настройках парсера (proxybannedcleanup)
.get()
Получить текущий прокси (последний прокси с которым был сделан запрос)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - установить прокси для следующего запроса. Параметр noChange необязательный, если задан true то прокси не будет меняться между попытками. По умолчанию noChange = false
await this.sessionManager.*
Методы для работы с сессиями. Каждая сессия обязательно хранит использованный прокси и куки. Также можно дополнительно сохранять произвольные данные.
Для использования сессий в JS парсере сначала обязательно нужно инициализировать Менеджер сессий. Делается это с помощью метода await this.sessionManagerinit() в init()
.init(opts?)
Инициализация Менеджера сессий. В качестве аргумента можно передавать объект (opts) с дополнительными параметрами (все параметры необязательны):
name- позволяет переопределить имя парсера, которому принадлежат сессии, по-умолчанию равно имени парсера, в котором происходит инициализацияwaitForSession- указывает парсеру ждать сессию пока она не появится (это актуально только когда работают несколько заданий, например одно генерирует сессии, второе их использует), т.е..get()и.reset()будут всегда ждать сессиюdomain- указывает искать сессии среди всех сохраненных для этого парсера (если значение не задано), или же только для конкретного домена (необходимо указывать домен с точкой спереди, например.site.com)sessionsKey- позволяет задать вручную названия хранилища сессий, если он не задан, то имя формируется автоматически на основеname(или названия парсера, еслиnameне задан), домена и проксичекераexpire- задает время жизни сессии в минутах, по-умолчанию неограничено
Пример использования:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Получение новой сессии, необходимо вызывать перед осуществлением запроса (перед первой попыткой). Возвращает объект с произвольными данными, сохраненными в сессии. В качестве аргумента можно передавать объект (opts) с дополнительными параметрами (все параметры необязательны):
waitTimeout- возможность указать сколько минут ждать появления сессии, работает независимо от параметраwaitForSessionв.init()(игнорирует его), по истечению будет использована пустая сессияtag- получение сесии с заданным тегом, можно использовать например имя домена для привязки сессий к доменам с которых они получены
Пример использования:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Очистка кук и получение новой сессии. Необходимо использовать, если с текущей сессией запрос не был удачным. Возвращает объект с произвольными данными, сохраненными в сессии. В качестве аргумента можно передавать объект (opts) с дополнительными параметрами (все параметры необязательны):
waitTimeout- возможность указать сколько минут ждать появления сессии, работает независимо от параметраwaitForSessionв.init()(игнорирует его), по истечению будет использована пустая сессияtag- получение сесии с заданным тегом, можно использовать например имя домена для привязки сессий к доменам с которых они получены
Пример использования:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Cохранение успешной сессии с возможностью сохранять произвольные данные в сессии. Поддерживает 2 необязательных аргумента:
sessionOpts- произвольные данные для хранения в сессии, может быть число, строка, массив или объектsaveOpts- объект с параметрами сохранения сессии:multiply- необязательный параметр, позволяет размножить сессию, в качестве значения нужно указать числоtag- необязательный параметр, задает тег для сохраняемой сессии, можно использовать например имя домена для привязки сессий к доменам с которых они получены
Пример использования:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Возвращает количество сессий для текущего Менеджера сессий
Пример использования:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Удаляет все сессии с заданным id. Возвращает количество удаленных сессий. Id текущей сессии содержится в переменной this.sessionId
Пример использования:
const removedCount = await this.sessionManager.removeById(this.sessionId);
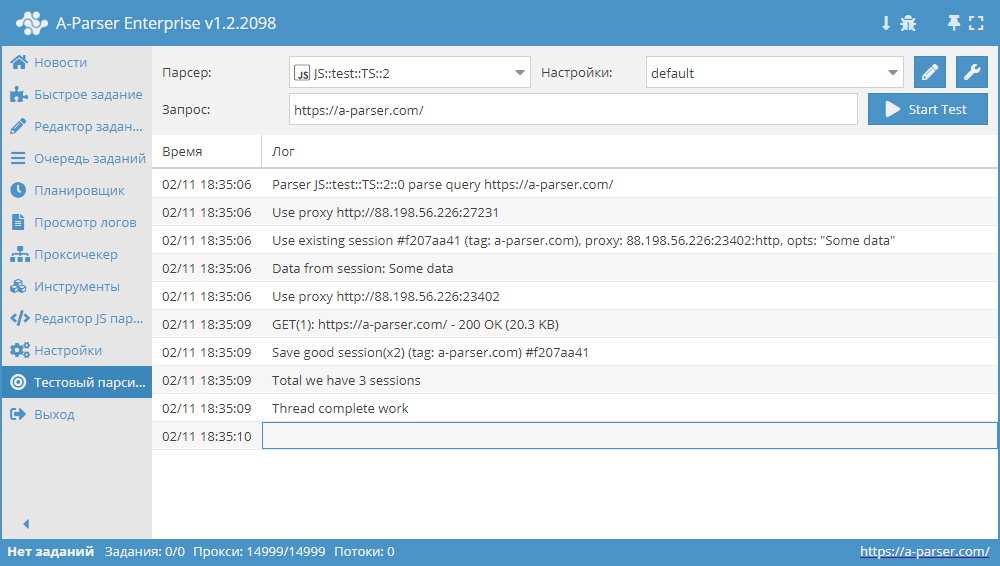
Комплексный пример использования Менеджера сессий
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Методы запросов await this.request
Метод GET
Передать параметры запроса можно напрямую в строке запроса https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Или как объект в queryParams, где key: value равно param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Метод POST
Если используется метод POST, тело запроса можно передать двумя способами:
Перечислить названия переменных и их значения в
queryParams, например:{
"key": set.query,
"id": 1234,
"type": "text"
}Перечислить их в
opts.body, например:body: 'key=' + set.query + '&id=1234&type=text'
Если тело запроса передается как объект он автоматически преобразуется в форму form-urlencoded, так же если указан body и не
указан content-type заголовок, то автоматически присвоится content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Если тело POST запроса строка или буффер, то оно так и передается:
// запрос со строкой
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// запрос с буффером
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Загрузка файлов
Отправка файла POST запросом с использованием модуля form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Пример отправки файла в POST запросе с типом контента multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});