Установить приложение
Как установить приложение на iOS
Следуйте инструкциям в видео ниже, чтобы узнать, как установить наш сайт как веб-приложение на главный экран вашего устройства.
Примечание: Эта функция может быть недоступна в некоторых браузерах.
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Необходимо обновить браузер или попробовать использовать другой.
Как спарсить title?
- Автор темы BlackAlex
- Дата начала
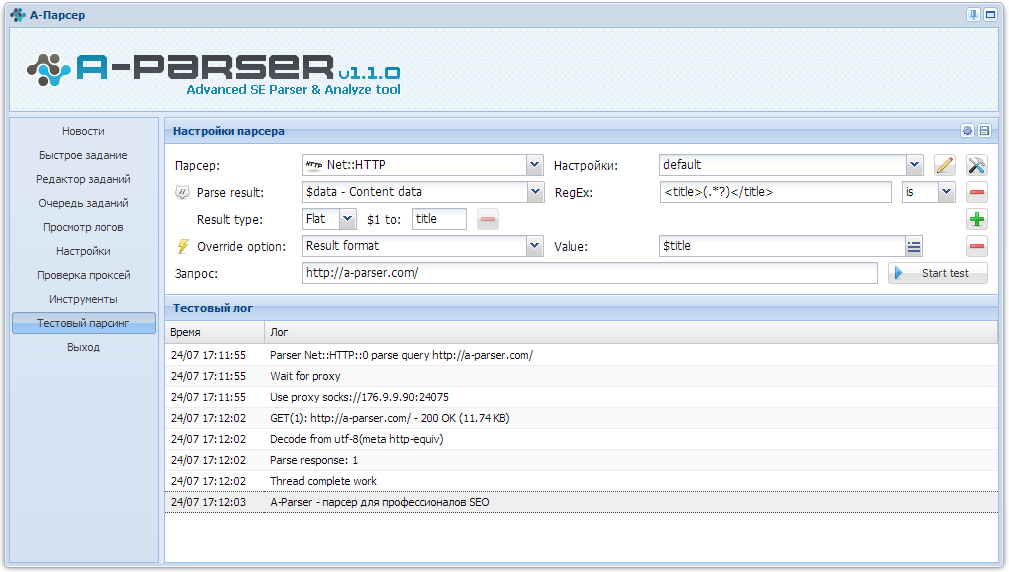

Используйте  HTML::LinkExtractor, задавая нужную глубину.
HTML::LinkExtractor, задавая нужную глубину.

Остальные Parse result добавляются аналогично.
HTML::LinkExtractor, задавая нужную глубину.
Остальные Parse result добавляются аналогично.

Составить правильную регулярку и/или воспользоваться Remove HTML tags в Конструкторе результатов, чтобы очистить от лишних тегов.Как вытянуть чистые данные?
например есть itemprop="name" в h1 или в h1 есть <span> а в нем itemprop="name" , как быть в таких ситуациях?
Регулярка которая игнорирует атрибуты, флаг i:
Код:
<h1[^>]*>(.*?)</h1>
Поделиться:
О нас
A-Parser - это профессиональная платформа для сбора данных промышленного масштаба: 10 000+ потоков, 110+ парсеров и гибкость Node.js. Автоматизируйте задачи в SEO, e-commerce и арбитраже трафика с непревзойденной скоростью и масштабируемостью
Быстрая навигация
Поддержка
Нужна помощь с настройкой или работой парсера? Напишите в поддержку, поможем довести все до результата.
Написать в поддержку