Подскажите, пожалуйста, как настроить Апарсер, чтоб собирать урлы заранее искомых доменов в кеше Яндекса? Цель - проверка проиндексированности беклинка Яндексом.
Установить приложение
Как установить приложение на iOS
Следуйте инструкциям в видео ниже, чтобы узнать, как установить наш сайт как веб-приложение на главный экран вашего устройства.
Примечание: Эта функция может быть недоступна в некоторых браузерах.
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нём неправильно.
Необходимо обновить браузер или попробовать использовать другой.
Необходимо обновить браузер или попробовать использовать другой.
Парсинг кеша Яндекса
- Автор темы WelcomePartners
- Дата начала
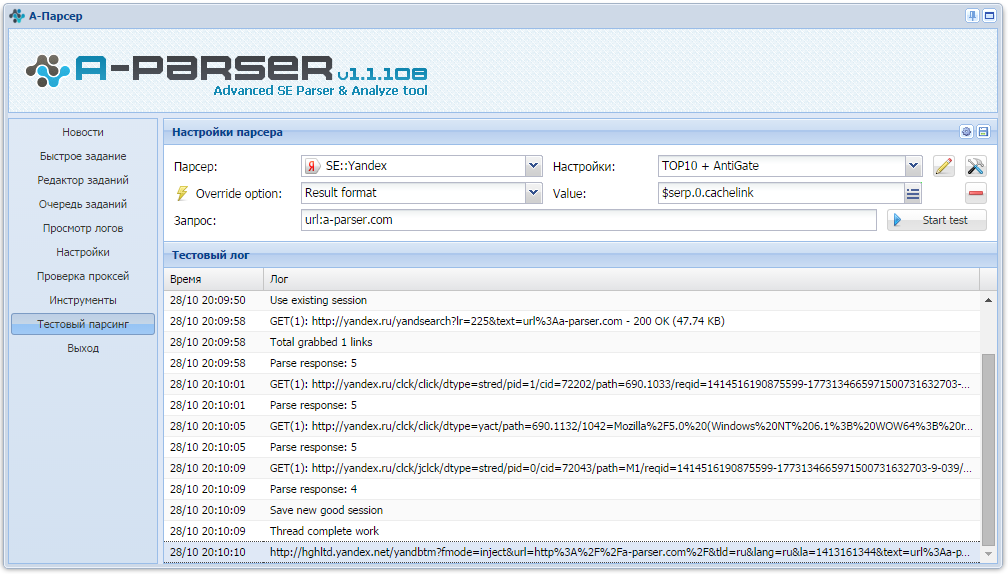
Не совсем понятно что с этим делать. Вот так выглядит результат работы парсера:

Тут искать дату последнего обновления страницы или что?
Тут искать дату последнего обновления страницы или что?
Задача следующая. Есть список страниц разных сайтов, на которых размещена ссылка на продвигаемую страницу http://domain.com/page.html
Необходимо проверить существует ли ссылка на продвигаемую страницу в кеше Яндекса исследуемых страниц.
Необходимо проверить существует ли ссылка на продвигаемую страницу в кеше Яндекса исследуемых страниц.
Необходимо сначала получить ссылки на кэш с помощью SE::Yandex и примера указанного выше, после этого вторым заданием можно проверить нахождение бэклинка с помощью парсера  Check::BackLink
Check::BackLink
Check::BackLinkСоздаю запрос для парсера Check::Backlink cо строкой:
На выходе не получаю ничего:

Что я делаю не так?
Код:
http://hghltd.yandex.net/yandbtm?fmode=inject&url=http%3A%2F%2Fa-parser.com%2Fwiki%2Fcheck-backlink%2F&tld=ru&lang=ru&la=1412051328&text=url%3Aa-parser.com%2Fwiki%2Fcheck-backlink%2F&l10n=ru&mime=html&sign=e54312c1a207366c72af013535c4a990&keyno=0 http://xenforo.com/Что я делаю не так?
Что значит ничего? результат в последней строке:
Код:
http://hghltd.yandex.net/yandbtm?fmode=inject&url=http%3A%2F%2Fa-parser.com%2Fwiki%2Fcheck-backlink%2F&tld=ru&lang=ru&la=1412051328&text=url%3Aa-parser.com%2Fwiki%2Fcheck-backlink%2F&l10n=ru&mime=html&sign=e54312c1a207366c72af013535c4a990&keyno=0 - http://xenforo.com/: 1, blocked by robots.txt: noneДействительно, не догадался в коне строки посмотреть ")
Но теперь я не могу составить правильный набор правил. Пробую так, но где-то закралась ошибка:

Но теперь я не могу составить правильный набор правил. Пробую так, но где-то закралась ошибка:
Поделиться:
О нас
A-Parser - это профессиональная платформа для сбора данных промышленного масштаба: 10 000+ потоков, 110+ парсеров и гибкость Node.js. Автоматизируйте задачи в SEO, e-commerce и арбитраже трафика с непревзойденной скоростью и масштабируемостью
Быстрая навигация
Поддержка
Нужна помощь с настройкой или работой парсера? Напишите в поддержку, поможем довести все до результата.
Написать в поддержку