Kreola
Member
Приветствую!
Есть объявление http://www.bezaat.com/ksa/mecca/properties-for-sale/multi-family-home/archive/11219476
Еще нерабочие: http://www.bezaat.com/tunisia/tunis/business-finance/business-records/ad/11438870
http://www.bezaat.com/ksa/mecca/travel/external-tourism/ad/9612031
Там есть строка с городом.

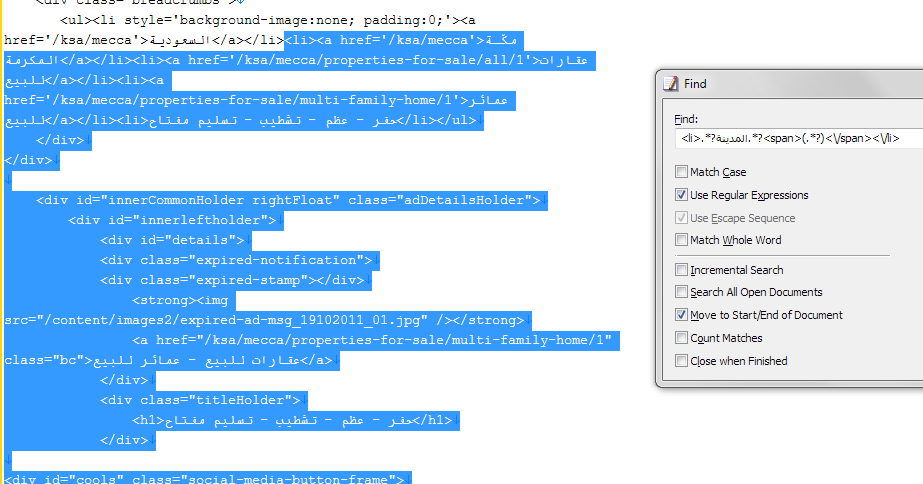
Пишу такую регулярку: <li>.*?المدينة.*?<span>(.*?)<\/span><\/li>
В http://www.regexr.com/3a4b8 все работает четко, только сам убираю переносы строк.
В парсере же вижу вот такое:
<city>1 شهر</span>
</li>
<li>
البلد
<span>السعودية</city>
Почему он захватывает лишний <span> не могу понять.
Таких ошибок немного, но они есть. Хотелось бы их исключить.
При этом тут http://www.bezaat.com/ksa/mecca/properties-for-sale/hotels/ad/10991164
Все работает правильно.
Подскажите как правильнее сделать.
Есть объявление http://www.bezaat.com/ksa/mecca/properties-for-sale/multi-family-home/archive/11219476
Еще нерабочие: http://www.bezaat.com/tunisia/tunis/business-finance/business-records/ad/11438870
http://www.bezaat.com/ksa/mecca/travel/external-tourism/ad/9612031
Там есть строка с городом.
Пишу такую регулярку: <li>.*?المدينة.*?<span>(.*?)<\/span><\/li>
В http://www.regexr.com/3a4b8 все работает четко, только сам убираю переносы строк.
В парсере же вижу вот такое:
<city>1 شهر</span>
</li>
<li>
البلد
<span>السعودية</city>
Почему он захватывает лишний <span> не могу понять.
Таких ошибок немного, но они есть. Хотелось бы их исключить.
При этом тут http://www.bezaat.com/ksa/mecca/properties-for-sale/hotels/ad/10991164
Все работает правильно.
Подскажите как правильнее сделать.