Новый парсер
 HTML::TextExtractor - парсит текстовые блоки с указанной страницы, можно использовать для парсинга огромного количества текста для наполнения своих сайтов и доров, можно настроить минимальную длину текстового блока для парсинга
HTML::TextExtractor - парсит текстовые блоки с указанной страницы, можно использовать для парсинга огромного количества текста для наполнения своих сайтов и доров, можно настроить минимальную длину текстового блока для парсинга

В парсере
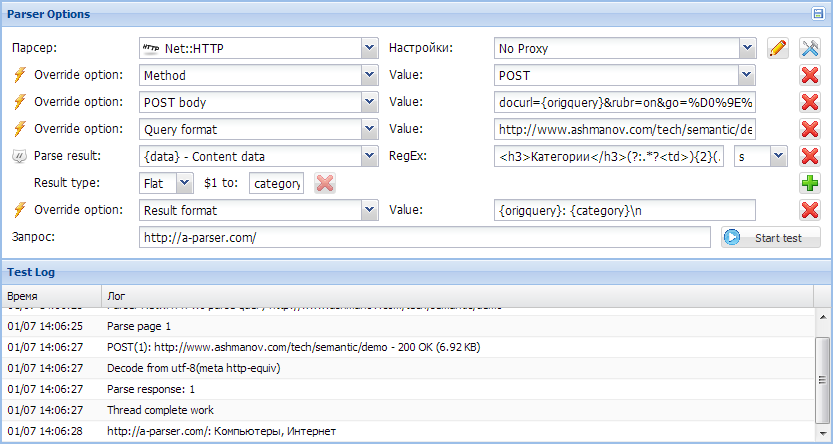
 Net::HTTP появилась возможность использовать POST и HEAD запросы, пример парсинга с POST запросом:
Net::HTTP появилась возможность использовать POST и HEAD запросы, пример парсинга с POST запросом:
Другие улучшения:
В парсере
Другие улучшения:
- Теперь в формате результата есть возможность указать исходный запрос - {firstquery}, позволяет при парсинге в глубину сохранять результаты по файлам с именами изначальных запросов
- В парсер Net::Whois добавлен парсинг NS серверов и статусов доменов

- В парсере Net::Whois теперь используется единый формат даты регистрации и окончания регистрации - dd.mm.yyyy для всех зон
- Новые результаты для всех парсеров:
- {retries} - использованное количество попыток на данный запрос
- {querynum} - порядковый номер запроса
- {lvl} - уровень вложенности запроса(при использовании опций Parse all results, Parse to level)
- Для парсера Net::HTTP добавлен параметр Max redirects count - определяет максимальное количество редиректов
- Для всех парсеров SE::Google::* добавлен домен www.google.by

- Теперь есть возможно указать задержку между запросами(актуально только при парсинге в 1 поток)
- Исправлен парсинг подсказок SE::Bing::Suggest

- Исправлено сохранение результатов с двоичными данными(изображения, видео и т.п.)