Конструктор результатов
Конструктор результатов - позволяет преобразовывать результаты от каждого парсера перед их форматированием и сохранением на диск
Возможности
- Разделение результата на части с помощью регулярного выражения или с помощью произвольного разделителя
- Замена подстроки в результате или замена регулярным выражением
- Выделение домена или главного домена из ссылки
- Приведение результата к верхнему\нижнему регистру
- Удаление HTML тегов (
<b>text</b>->text) - Преобразование HTML сущностей в их Unicode эквиваленты (
©->©) - Получение данных с помощью XPath-запросов
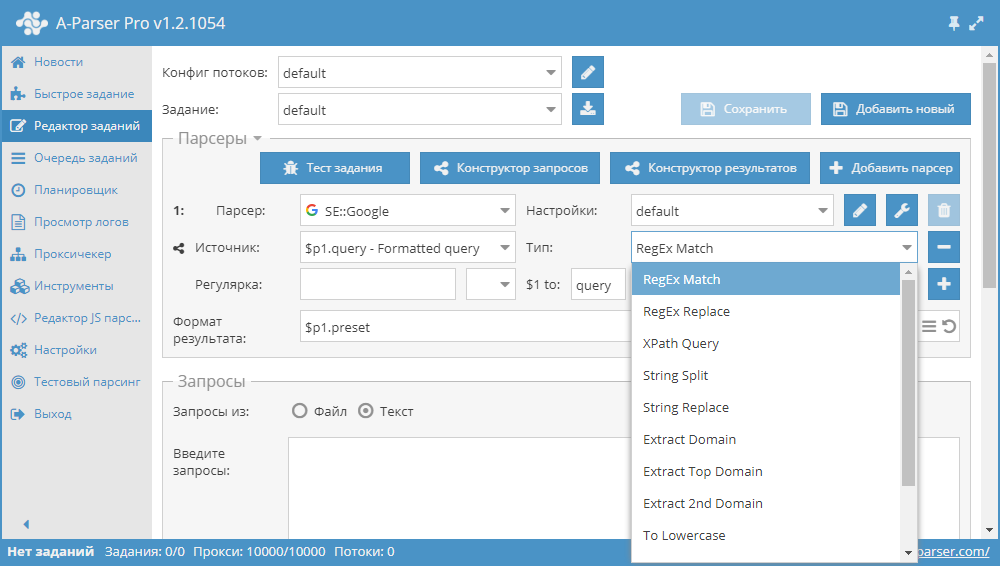
Примеры
Парсинг доменов
Сохранение только доменов при парсинге ссылок с поисковых систем:
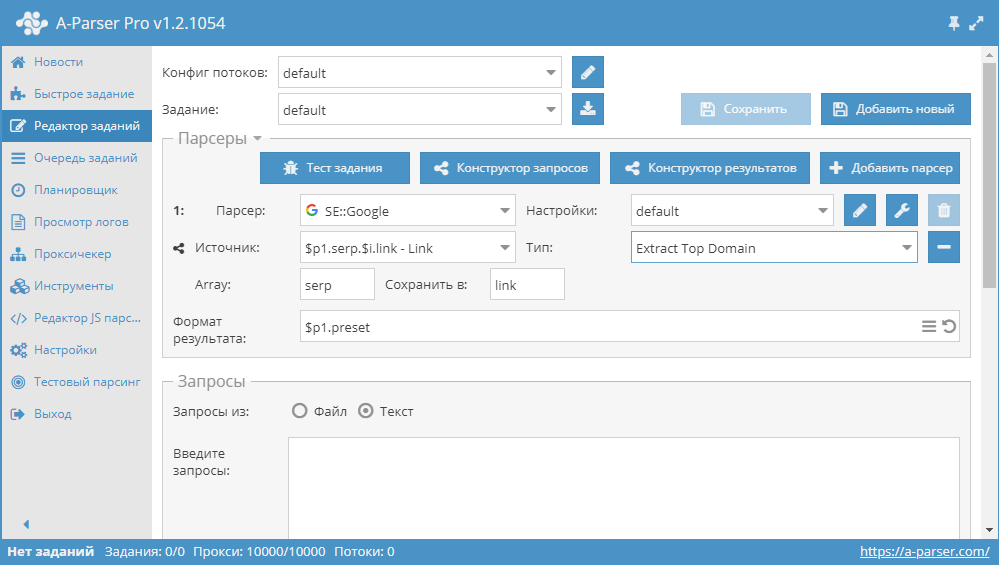
В качестве источника используются элементы link из массива serp из первого парсера, к каждому элементу будет применена функция извлечения главного домена из ссылки, новый результат будет сохранен под тем же именем (элемент link в массиве serp) - поэтому изменять формат результата не требуется
Парсинг сниппетов с очисткой
Сохранение сниппетов с поисковых систем с очисткой от HTML тегов и преобразованием HTML сущностей
По умолчанию анкоры и сниппеты парсятся со всеми вложенными тегами, что позволяет сохранять такое же форматирование как при просмотре выдачи с поисковых систем. Если необходим только чистый текст то можно воспользоваться возможностями Конструктора результатов:
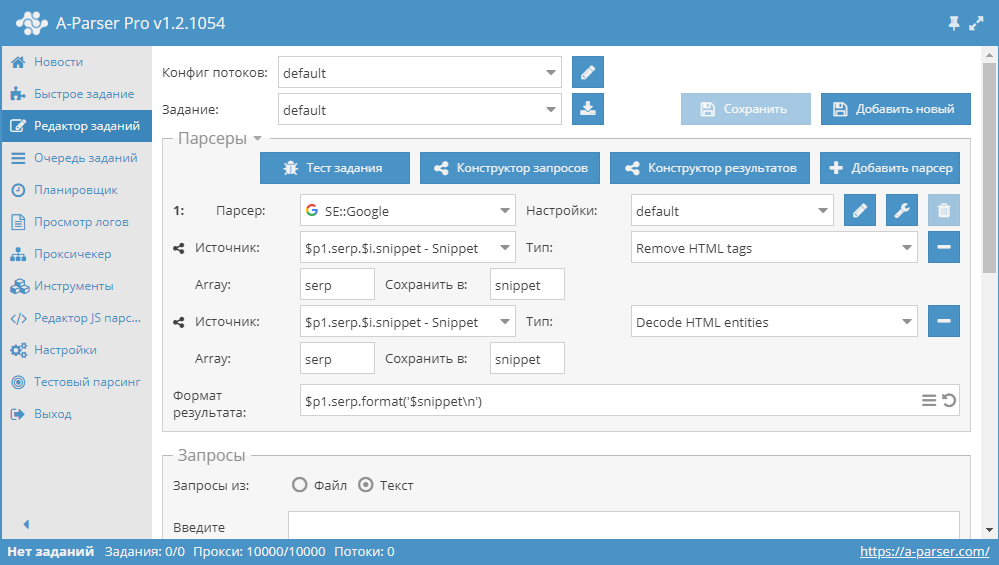
В данном примере к сниппетам последовательно применено два Конструктора результатов - удаление HTML тегов и преобразование HTML сущностей
Парсинг с помощью XPath
Парсинг ссылок из поисковой выдачи с помощью XPath:
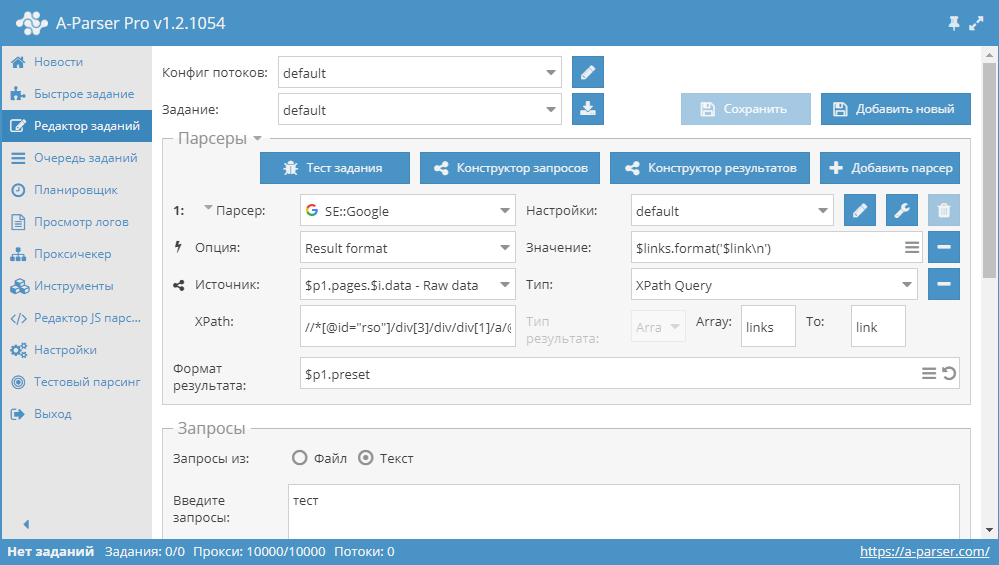
В данном примере показан парсинг ссылок из поисковика Google. Используется XPath-запрос:
//*[@id="rso"]/div[3]/div/div[1]/a/@href