- Минимальная версия A-Parser
- 1.2
В этой статье будет рассмотрен способ поиска и сбора ссылок на RSS ленты. Решение будет иметь 3 этапа:
Составляем вполне стандартный пресет на основе SE::Google, в результат выводим только домены:
SE::Google, в результат выводим только домены:

Результат:
Составляем пресет на базе Net::HTTP.
Net::HTTP.
Добавляем опцию Good status и выбираем 200 OK.
Выбираем опцию User agent и прописываем юзер-агент любого современного браузера. Это необходимо на тот случай, если сайт не отдает контент при запросе с юзер-агентом IE7, который используется в A-Parser по-умолчанию.
Выбираем функцию Использовать регулярку и применяем к переменной $data - Content data регулярное выражение с флагом ig.
Добавляем фильтр и применяем его к переменной $links.$i.link. При помощи регулярного выражения
проверяем чтобы ссылки были внутренние и в результат выводились только ссылки содержащие rss.
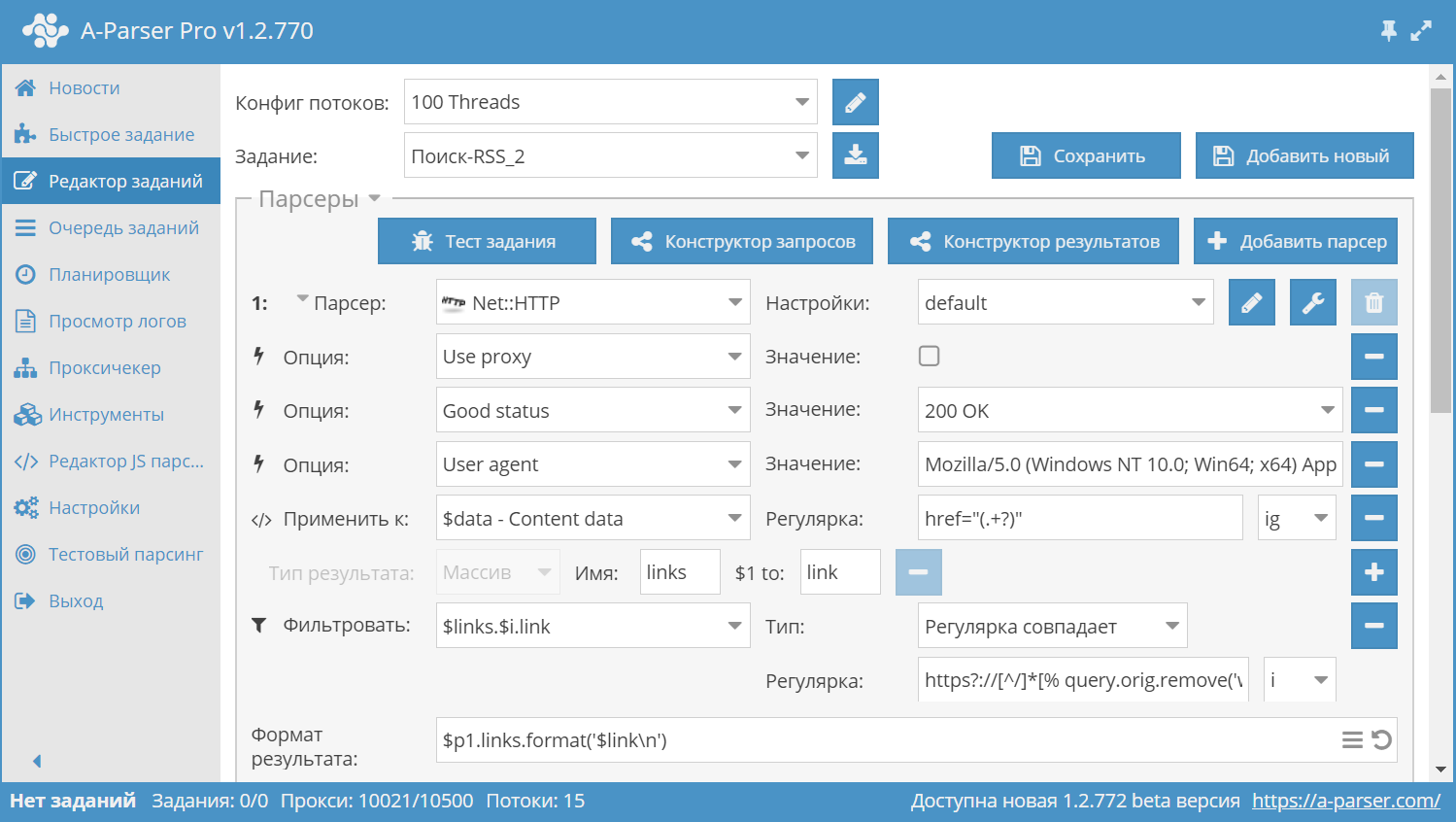
Результат:
Проверяем контент по полученным на 2-м этапе ссылкам, если это действительно rss лента, то выводит в результат ссылку. Проверка происходит по наличию тегов <rss или <?xml. Фильтр применяем к переменной $data - Content data, флаг i и используем регулярку
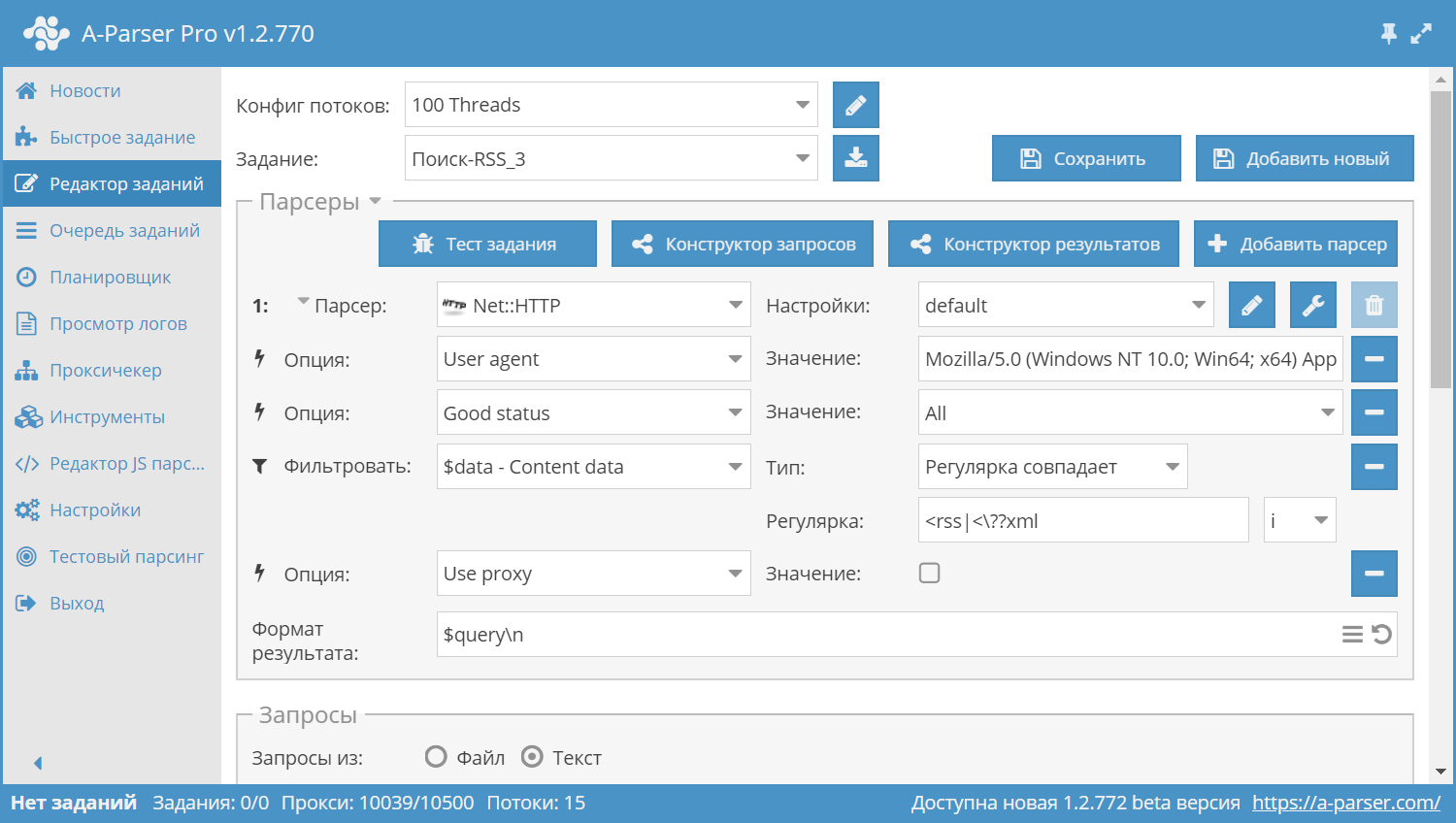
В итоге получили ссылки на RSS ленты:
Данный пример можно модифицировать и применять если нужно получить в результат ссылки с определенным значениями, например: наличие формы комментария в коде страницы или поиск кода формы обратной связи.
Готовый пресет Поиск и сбор rss лент можно скачать в Каталоге.
- поиск сайтов в Google по ключевым словам, например, "погода rss"
- парсинг только внутренних ссылок с наличием в них rss
- проверка найденных ссылок
1. Поиск сайтов в Google по ключевым словам
Составляем вполне стандартный пресет на основе
SE::Google, в результат выводим только домены:
Результат:
2. Парсим из главных страниц сайтов ссылки и выводим в результат только те, которые содержат rss.
Составляем пресет на базе
Net::HTTP.Добавляем опцию Good status и выбираем 200 OK.
Выбираем опцию User agent и прописываем юзер-агент любого современного браузера. Это необходимо на тот случай, если сайт не отдает контент при запросе с юзер-агентом IE7, который используется в A-Parser по-умолчанию.
Выбираем функцию Использовать регулярку и применяем к переменной $data - Content data регулярное выражение с флагом ig.
Код:
href="(.+?)"
Код:
https?://[^/]*[% query.orig.remove('www\.') %]/.*rssРезультат:
3. Проверка содержимого по найденным ссылкам
Проверяем контент по полученным на 2-м этапе ссылкам, если это действительно rss лента, то выводит в результат ссылку. Проверка происходит по наличию тегов <rss или <?xml. Фильтр применяем к переменной $data - Content data, флаг i и используем регулярку
Код:
<rss|<\??xmlВ итоге получили ссылки на RSS ленты:
Заключение.
Данный пример можно модифицировать и применять если нужно получить в результат ссылки с определенным значениями, например: наличие формы комментария в коде страницы или поиск кода формы обратной связи.
Готовый пресет Поиск и сбор rss лент можно скачать в Каталоге.