Kreola
Member
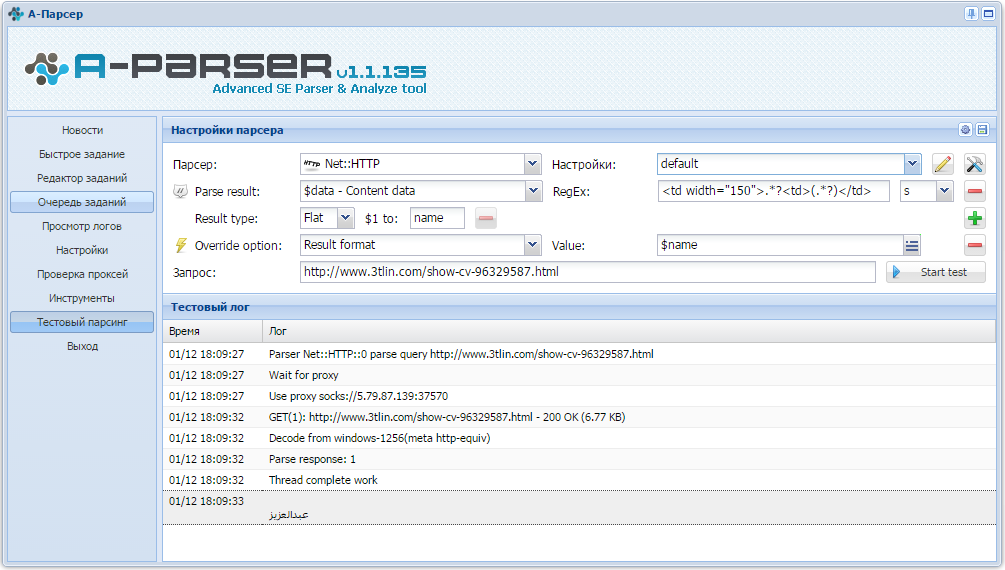
Суть не в арабском, Если я пытаюсь сделать по логике, то получается так.

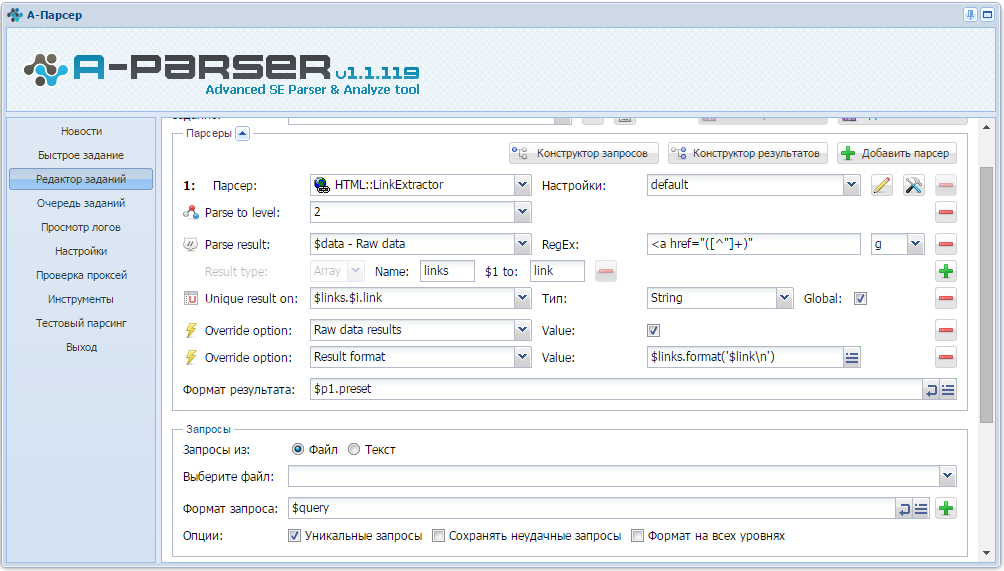
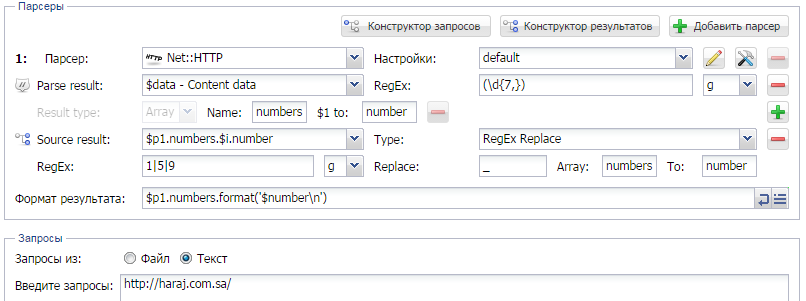
1) Формируем формат результата
2) Формируем списки замен.
3) Парсим резуьтат.
На деле же пункты 2 и 3 меняются местами.
Покажите пожалуйста на примере, как это должно выглядеть, либо ткните носом, где почитать про это.
Спасибо.
Вы говорите разобраться с основами, но в документации нет ни слова про нормальный рабочий пример, там только обрывки всяких задач, которые показывают только поверхностно, что умеет парсер, а не как пользоваться в той или иной ситуации.
1) Формируем формат результата
2) Формируем списки замен.
3) Парсим резуьтат.
На деле же пункты 2 и 3 меняются местами.
Покажите пожалуйста на примере, как это должно выглядеть, либо ткните носом, где почитать про это.
Спасибо.
Вы говорите разобраться с основами, но в документации нет ни слова про нормальный рабочий пример, там только обрывки всяких задач, которые показывают только поверхностно, что умеет парсер, а не как пользоваться в той или иной ситуации.



")