и такой вопрос возник.
бывают сайты небольшие, 10-20 страничек, их можно спарсить на предмет мыл достаточно просто и быстро
а есть сайты с большим количеством страниц, и довольно часто бывает, что на них всех нет никаких мыл, и парсить сотни страниц такого сайта нет смысла. Есть ли возможность, чтобы устанавливать минимальное количество страниц при парсинге, если на них НЕ находятся мыла, то такой сайт пропускается.
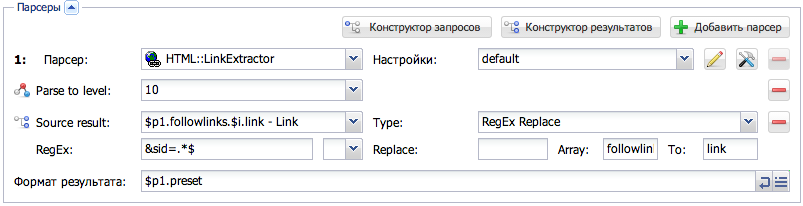
Речь идёт именно о парсере
HTML::LinkExtractor
например. выставляем Level Parsing - 3 и количество страниц - 40
я же правильно понимаю, что сначала сканируются все страницы первого уровня, и страницы типа ContactUs, about и т.п. уже по умолчанию попадают в первый уровень, т.к. ссылки на такие страницы как правило, всегда есть на любой странице сайта либо в верхнем меню, либо в футере.
Поэтому прямые контакты сайта уже спарсены.
Далее уже идёт поиск возможных мыл на втором и третьем уровне парсинга. И если на этих уровнях на первых 40 страницах в поиске уникальных мыл НЕ находится, то сайт откладывается и начинается сканирование другого сайта.
Иначе многостраничные сайты могут тормозить поиск очень сильно.
")