Здравствуйте,
Подскажите пожалуйста как выполнить сабж.
В моем случае :
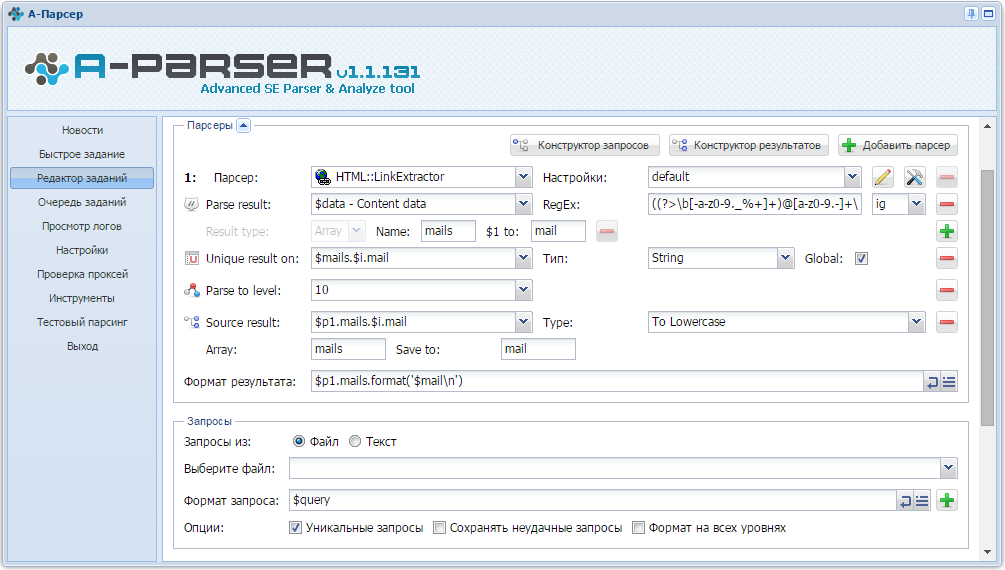
- По определенным кейвордам получаю список сайтов, как указано здесь
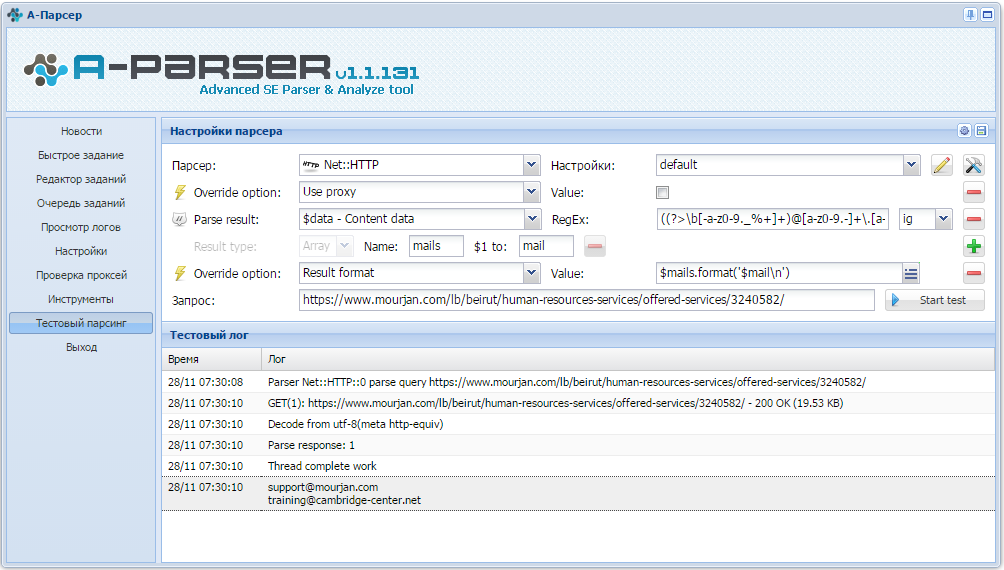
- Далее я хотел бы проверить все страницы этих сайтов на наличие email адресов ( не только Контакты, Реклама, Поддержка и т.д. ) и спарсить при наличии на странице.
Дополнительный вопрос:
Можно ли поставить в задании условие - подставлять к каждому кейворду из файла определенную фразу ( forum, portal, etc... )
Заранее благодарен )
Подскажите пожалуйста как выполнить сабж.
В моем случае :
- По определенным кейвордам получаю список сайтов, как указано здесь
- Далее я хотел бы проверить все страницы этих сайтов на наличие email адресов ( не только Контакты, Реклама, Поддержка и т.д. ) и спарсить при наличии на странице.
Дополнительный вопрос:
Можно ли поставить в задании условие - подставлять к каждому кейворду из файла определенную фразу ( forum, portal, etc... )
Заранее благодарен )






")