Solicitudes HTTP (+trabajo con cookies, proxy, sesiones)
Métodos de la clase base
Para recopilar datos de una página web, es necesario realizar una solicitud HTTP. En la JavaScript API v2 de A-Parser se ha implementado un método de ejecución de solicitudes HTTP fácil de usar, que devuelve un objeto JSON como respuesta dependiendo de los argumentos del método especificados. A continuación, aprenderá: cómo se realiza una solicitud HTTP, qué argumentos y opciones tiene el método, los resultados de dichas opciones, cómo especificar la condición de éxito de una solicitud HTTP, y más.
Estos métodos se heredan de BaseParser y son la base para crear sus propios extractores.
Obtención de una respuesta HTTP mediante una solicitud; se especifican como argumentos:
method- método de la solicitud (GET, POST...)url- enlace para la solicitudqueryParams- hash con parámetros get o hash con el cuerpo de la solicitud post solicitudes HTTP o guardar para que otro hilo las ejecute utilizando el Gestor de sesiones.
Estos métodos se heredan de BaseParser y son la base para crear extractores propios
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Obtención de una respuesta HTTP mediante una solicitud; se especifican como argumentos:
method- método de la solicitud (GET, POST...)url- enlace para la solicitudqueryParams- hash con parámetros get o hash con el cuerpo de la solicitud postopts- hash con opciones de la solicitud
opts.check_content
check_content: [ condición1, condición2, ...] - matriz de condiciones para verificar el contenido recibido; si la verificación no
se cumple, la solicitud se repetirá con otro proxy.
Posibilidades:
- uso de cadenas como condiciones (búsqueda por coincidencia de cadena)
- uso de expresiones regulares como condiciones
- uso de funciones de verificación propias, a las que se pasan los datos y los encabezados de la respuesta
- se pueden establecer varios tipos de condiciones a la vez
- para la negación lógica, coloque la condición en una matriz, es decir,
check_content: ['xxxx', [/yyyy/]]significa que la solicitud se considerará exitosa si los datos recibidos contienen la subcadenaxxxxy, al mismo tiempo, la expresión regular/yyyy/no encuentra coincidencias en la página
Para una solicitud exitosa, deben cumplirse todas las verificaciones especificadas en la matriz
Ejemplo (en los comentarios se indica qué se necesita para que la solicitud se considere exitosa):
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // en la página recibida debe activarse esta expresión regular
['XXXX'], // en la página recibida no debe estar esta subcadena
'</html>', // en la página recibida debe estar esta subcadena
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // esta función debe devolver true
]
});
opts.decode
decode: 'auto-html' - detección automática de la codificación y conversión a utf8
Valores posibles:
auto-html- basado en encabezados, etiquetas meta y el contenido de la página (opción recomendada óptima)utf8- indica que el documento está en codificación utf8<encoding>- cualquier otra codificación
opts.headers
headers: { ... } - hash con encabezados, el nombre del encabezado se especifica en minúsculas, se puede incluir cookie.
Ejemplo:
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - permite redefinir el orden de clasificación de los encabezados
opts.onlyheaders
onlyheaders: 0 - determina la lectura de data; si está activado (1), solo obtiene los encabezados
opts.recurse
recurse: N - número máximo de saltos por redirecciones, por defecto 7, use 0 para desactivar el seguimiento de
redirecciones
opts.proxyretries
proxyretries: N - número de intentos de ejecución de la solicitud, por defecto se toma de la configuración del extractor
opts.parsecodes
parsecodes: { ... } - lista de códigos de respuesta HTTP que el extractor considerará exitosos, por defecto se toma de la
configuración del extractor. Si se especifica '*': 1, todas las respuestas se considerarán exitosas.
Ejemplo:
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - tiempo de espera de la respuesta en segundos, por defecto se toma de la configuración del extractor
opts.do_gzip
do_gzip: 1 - determina si se debe usar compresión (gzip/deflate/br), por defecto activado (1); para desactivarlo
se debe establecer el valor 0
opts.max_size
max_size: N - tamaño máximo de la respuesta en bytes, por defecto se toma de la configuración del extractor
opts.cookie_jar
cookie_jar: { ... } - hash con cookies. Ejemplo de hash:
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - indica el número del intento actual; al usar este parámetro, se ignora el controlador de intentos integrado para
esta solicitud
opts.browser
browser: 1 - emulación automática de encabezados de navegador (1 - activado, 0 - desactivado)
opts.use_proxy
use_proxy: 1 - redefine el uso de proxy para una solicitud individual dentro del extractor JS por encima del
parámetro global Use proxy (1 - activado, 0 - desactivado)
opts.noextraquery
noextraquery: 0 - desactiva la adición de Extra query string a la URL de la solicitud (1 - activado, 0 - desactivado)
opts.save_to_file
save_to_file: file - permite descargar un archivo directamente al disco, omitiendo la escritura en memoria. En lugar de file, se especifica el nombre y
la ruta bajo la cual guardar el archivo. Al usar esta opción, se ignora todo lo relacionado con data (la verificación de contenido
en opts.check_content no se realizará, response.data estará vacío, etc.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - evasión automática de la protección JavaScript de CloudFlare utilizando el navegador Chrome (1 - activado, 0 -
desactivado)
El control de Chrome Headless en este caso se realiza mediante los ajustes del extractor bypassCloudFlareChromeMaxPages
y bypassCloudFlareChromeHeadless, que deben especificarse en static defaultConf y static editableConf:
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - permite seguir las redirecciones declaradas a través de la etiqueta meta HTML:
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - permite establecer una función de filtrado para el seguimiento de redirecciones; si la función
devuelve 1, el extractor seguirá la redirección (teniendo en cuenta el parámetro opts.recurse); si devuelve 0, el seguimiento de
redirecciones se detendrá:
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - determina si se deben seguir las redirecciones estándar (por ejemplo, http -> https
y/o www.domain.com -> domain.com); si se especifica 1, el extractor seguirá las redirecciones estándar sin tener en cuenta
el parámetro opts.recurse
opts.http2
opts.http2: 0 - determina si se debe utilizar el protocolo HTTP/2 al realizar solicitudes; por defecto
se utiliza HTTP/1.1
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - esta opción permite evitar el bloqueo de sitios por huella digital TLS (1 - activado, 0 -
desactivado)
opts.tlsOpts
tlsOpts: { ... } – permite
pasar configuraciones para
conexiones https
await this.cookies.*
Trabajo con cookies para la solicitud actual
.getAll()
Obtención de una matriz de cookies
await this.cookies.getAll();
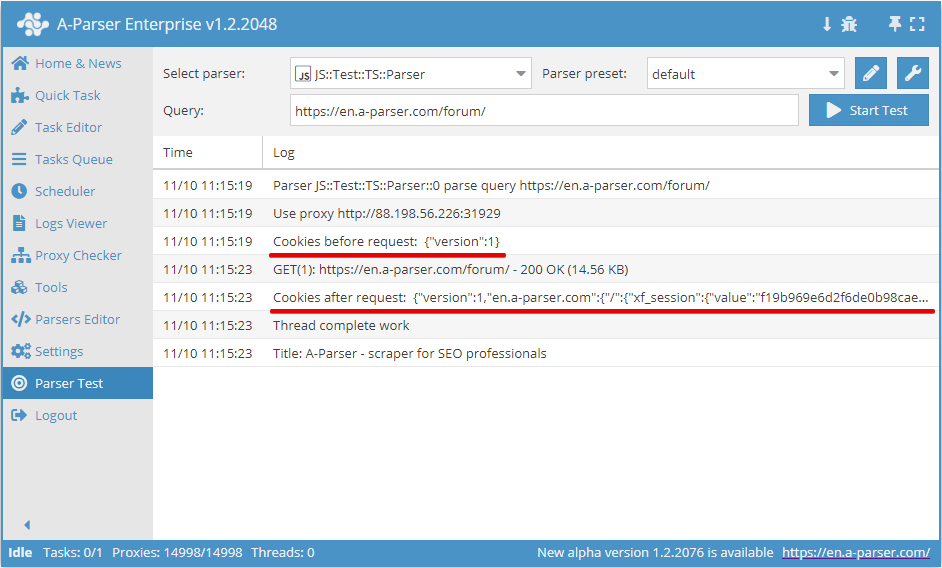
.setAll(cookie_jar)
Establecimiento de cookies; se debe pasar como argumento un hash con las cookies
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
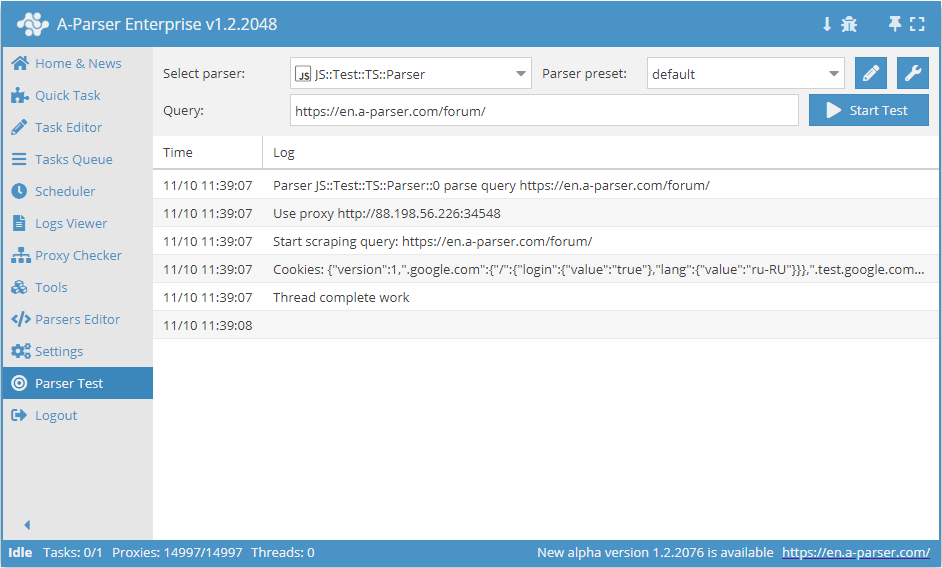
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - establecimiento de una sola cookie.
El ámbito de visibilidad de la cookie depende directamente del formato del dominio especificado, por lo que en host se tiene en cuenta la presencia de un punto antes del host:
- si se especifica el punto (
this.cookies.set('.domain.com', ...)), la cookie se utilizará para todos los subdominios (por ejemplo, a.domain.com, b.a.domain.com) - si el host se especifica sin punto delante (
this.cookies.set('site.com', ...)), la cookie se utilizará estrictamente para el host especificado (host-only cookie) y no se transmitirá a los subdominios
Esta distinción es críticamente importante, ya que la existencia simultánea de cookies con y sin punto puede llevar a su duplicación y a un funcionamiento impredecible del sitio. Para una emulación correcta, verifique siempre cómo establece las cookies el sitio de destino (con el atributo Domain o sin él) y utilice el formato correspondiente.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
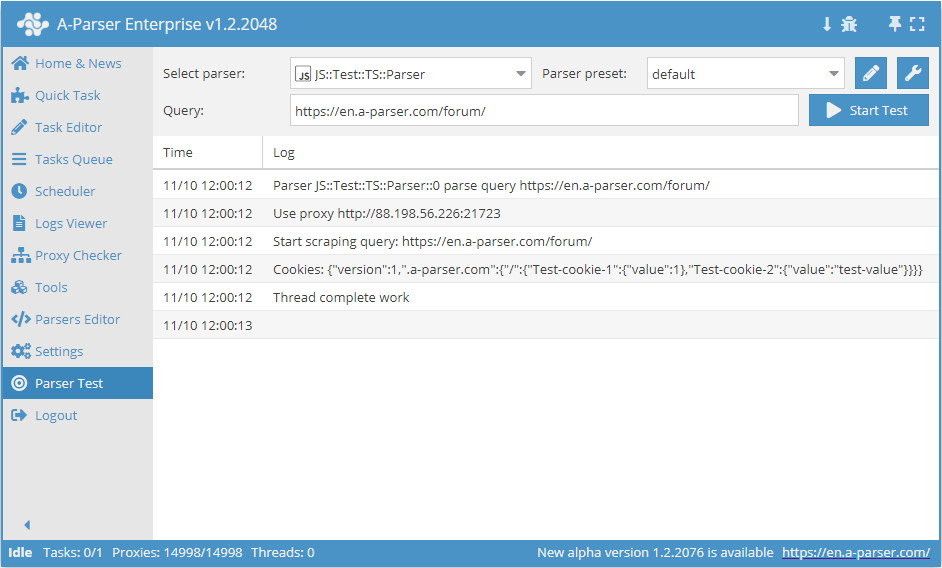
await this.proxy.*
Trabajo con proxy
.next()
Cambiar el proxy al siguiente; el proxy antiguo ya no se utilizará para la solicitud actual
.ban()
Cambiar y banear el proxy (es necesario usarlo cuando el servicio bloquea el trabajo por IP); el proxy será baneado por el tiempo
especificado en la configuración del extractor (proxybannedcleanup)
.get()
Obtener el proxy actual (el último proxy con el que se realizó la solicitud)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - establecer un proxy para la siguiente solicitud. El parámetro noChange es opcional; si se establece en true, el proxy no cambiará entre intentos. Por defecto noChange = false
await this.sessionManager.*
Métodos para trabajar con sesiones. Cada sesión almacena obligatoriamente el proxy y las cookies utilizados. También se pueden guardar adicionalmente datos arbitrarios.
Para utilizar sesiones en un extractor JS, primero es obligatorio inicializar el Gestor de sesiones. Esto se hace mediante el método await this.sessionManagerinit() en init()
.init(opts?)
Inicialización del Gestor de sesiones. Como argumento se puede pasar un objeto (opts) con parámetros adicionales (todos los parámetros son opcionales):
name- permite redefinir el nombre del extractor al que pertenecen las sesiones; por defecto es igual al nombre del extractor en el que ocurre la inicializaciónwaitForSession- indica al extractor que espere por una sesión hasta que aparezca (esto es relevante solo cuando funcionan varias tareas, por ejemplo, una genera sesiones y la segunda las utiliza), es decir,.get()y.reset()siempre esperarán por una sesióndomain- indica buscar sesiones entre todas las guardadas para este extractor (si no se establece valor), o bien solo para un dominio específico (es necesario indicar el dominio con un punto delante, por ejemplo,.site.com)sessionsKey- permite establecer manualmente el nombre del almacenamiento de sesiones; si no se establece, el nombre se forma automáticamente basado enname(o el nombre del extractor sinameno se establece), el dominio y el proxycheckerexpire- establece el tiempo de vida de la sesión en minutos; por defecto es ilimitado
Ejemplo de uso:
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Obtención de una nueva sesión; debe llamarse antes de realizar la solicitud (antes del primer intento). Devuelve un objeto con datos arbitrarios guardados en la sesión. Como argumento se puede pasar un objeto (opts) con parámetros adicionales (todos los parámetros son opcionales):
waitTimeout- posibilidad de especificar cuántos minutos esperar a que aparezca la sesión; funciona independientemente del parámetrowaitForSessionen.init()(lo ignora); al expirar se utilizará una sesión vacíatag- obtención de una sesión con una etiqueta determinada; se puede usar, por ejemplo, el nombre del dominio para vincular las sesiones a los dominios de los que se obtuvieron
Ejemplo de uso:
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Limpieza de cookies y obtención de una nueva sesión. Debe usarse si la solicitud no fue exitosa con la sesión actual. Devuelve un objeto con datos arbitrarios guardados en la sesión. Como argumento se puede pasar un objeto (opts) con parámetros adicionales (todos los parámetros son opcionales):
waitTimeout- posibilidad de especificar cuántos minutos esperar a que aparezca la sesión; funciona independientemente del parámetrowaitForSessionen.init()(lo ignora); al expirar se utilizará una sesión vacíatag- obtención de una sesión con una etiqueta determinada; se puede usar, por ejemplo, el nombre del dominio para vincular las sesiones a los dominios de los que se obtuvieron
Ejemplo de uso:
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Guardado de una sesión exitosa con la posibilidad de guardar datos arbitrarios en la sesión. Admite 2 argumentos opcionales:
sessionOpts- datos arbitrarios para almacenar en la sesión; puede ser un número, cadena, matriz u objetosaveOpts- objeto con parámetros de guardado de la sesión:multiply- parámetro opcional; permite multiplicar la sesión; se debe especificar un número como valortag- parámetro opcional; establece una etiqueta para la sesión guardada; se puede usar, por ejemplo, el nombre del dominio para vincular las sesiones a los dominios de los que se obtuvieron
Ejemplo de uso:
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Devuelve la cantidad de sesiones para el Gestor de sesiones actual
Ejemplo de uso:
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Elimina todas las sesiones con un id determinado. Devuelve la cantidad de sesiones eliminadas. El id de la sesión actual se encuentra en la variable this.sessionId
Ejemplo de uso:
const removedCount = await this.sessionManager.removeById(this.sessionId);
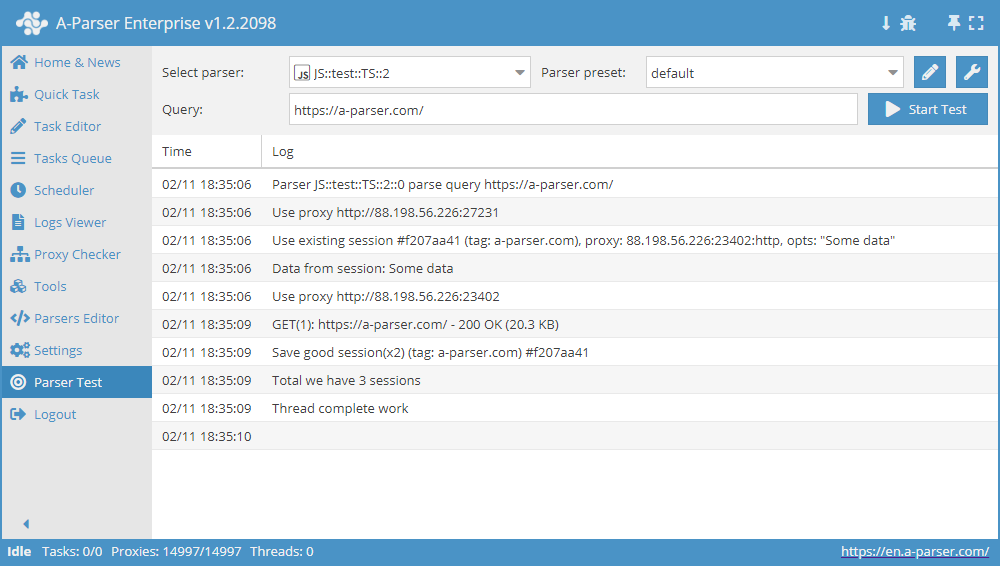
Ejemplo complejo de uso del Gestor de sesiones
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Métodos de solicitud await this.request
Método GET
Se pueden pasar los parámetros de la solicitud directamente en la cadena de consulta https://a-parser.com/users/?type=staff:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
O como un objeto en queryParams, donde key: value es igual a param=value:
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Método POST
Si se utiliza el método POST, el cuerpo de la solicitud se puede pasar de dos maneras:
Enumerar los nombres de las variables y sus valores en
queryParams, por ejemplo:{
"key": set.query,
"id": 1234,
"type": "text"
}Enumerarlos en
opts.body, por ejemplo:body: 'key=' + set.query + '&id=1234&type=text'
Si el cuerpo de la solicitud se pasa como un objeto, se convierte automáticamente al formato form-urlencoded; asimismo, si se especifica body y no
se especifica el encabezado content-type, se asignará automáticamente content-type: application/x-www-form-urlencoded:
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Si el cuerpo de la solicitud POST es una cadena o un búfer, se transmite tal cual:
// solicitud con cadena
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// solicitud con buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Carga de archivos
Envío de un archivo mediante una solicitud POST utilizando el módulo form-data:
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Ejemplo de envío de un archivo en una solicitud POST con el tipo de contenido multipart/form-data:
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});