Preguntas frecuentes
1. Preguntas relacionadas con la demo, el pago y la compra
1.1. ¿Cómo descargar los resultados en la versión Demo?
En la versión Demo, los resultados del trabajo no están disponibles para su descarga. Los proporcionamos bajo petición. Envíe sus consultas e indique qué extractor le interesa, y le enviaremos los resultados (dentro de la demo, su cantidad es limitada).
1.2. ¿Es necesario pagar algo adicional después de comprar A-Parser?
No. Más detalladamente: licencias y complementos, página de compra.
1.3. ¿Dónde y cómo se pueden pagar los proxies?
Al comprar una licencia, se le proporcionan proxies de bonificación.
Lite - 20 hilos por 2 semanas, Pro y Enterprise - 50 hilos por un mes.
Puede comprar más hilos o renovarlos en su Área de clientes en la pestaña Tienda, subsección Proxy.
1.4. ¿Podrían configurarme una tarea por dinero?
El soporte técnico para cuestiones relacionadas con el funcionamiento de A-Parser se ofrece de forma gratuita. Para ayuda de pago en la configuración de tareas, puede dirigirse aquí: Servicios de pago para la creación de tareas, ayuda con la configuración y formación en el uso de A-Parser.
1.5. ¿Puedo realizar el pago del extractor a través del banco Privat24? ¿A través de KIWI?
La lista de sistemas de pago con los que trabajamos se indica aquí: comprar A-Parser.
1.6. Si solo necesito extraer la cantidad de páginas indexadas en Yandex, ¿qué extractor es mejor comprar?
Para tales fines es suficiente la versión Lite, pero la Pro es más práctica y flexible en el trabajo.
1.7. ¿Dónde ver la información sobre mi licencia?
1.8. ¿Es posible utilizar los proxies comprados desde varias IP?
No.
2. Preguntas sobre instalación, ejecución y actualizaciones
2.1. Pulso el botón Download - pero el archivo no se descarga. ¿Qué hacer?
Compruebe si tiene espacio libre en el disco duro, desactive el antivirus. Siga las instrucciones de instalación. También consulte Cómo empezar a trabajar.
2.2. Compré la versión Enterprise, pero se sigue instalando la PRO. ¿Qué hacer?
Elimine la versión anterior. En el Members Area, compruebe si su dirección IP está correctamente registrada. Antes de la descarga, pulse el botón Update (Actualizar). Descargue la versión más reciente. Más detalles en las instrucciones de instalación.
2.3. Instalé el programa, pero no se inicia, ¿qué hacer?
Compruebe las aplicaciones en ejecución, desactive el antivirus, verifique el volumen disponible de memoria RAM libre. También en el Área de clientes compruebe si su dirección IP está correctamente registrada. Más detalles: instrucciones de instalación.
2.4. ¿Qué hacer si tengo una dirección IP dinámica?
No se preocupe, A-Parser admite el trabajo con direcciones IP dinámicas. Simplemente, cada vez que cambie, debe registrarla en el Members Area. Para evitar estas manipulaciones, se recomienda utilizar una dirección IP estática.
2.5. ¿Cuáles son los parámetros óptimos del servidor o computadora para instalar el extractor?
Todos los requisitos del sistema se pueden ver aquí: requisitos del sistema.
2.6. Inicié una tarea. El extractor se cayó y ya no se inicia, ¿qué hacer?
Es necesario detener el servidor, comprobar si el proceso sigue en memoria e intentar ejecutarlo de nuevo. También puede intentar ejecutar A-Parser deteniendo todas las tareas. Para ello, debe ejecutarlo con el parámetro -stoptasks. Detalles sobre la ejecución con parámetro.
2.7. ¿Qué contraseña introducir al abrir la dirección 127.0.0.1:9091?
Si es el primer inicio, la contraseña está vacía. Si no es el primero, la que usted haya establecido. Si olvidó la contraseña: restablecimiento de contraseña.
2.8. En el Área de clientes introduzco mi IP, pero no cambia en el campo Su IP actual. ¿Por qué?
El campo Your current IP (Su IP actual) muestra la IP que tiene válida en este momento, y no debe cambiar. Es esta la que debe escribir en el campo IP 1.
2.9. ¿Puedo ejecutar simultáneamente dos copias?
Se pueden ejecutar dos copias en una misma máquina solo si tienen configurado un puerto diferente en el archivo de configuración.
Ejecutar dos A-Parser en máquinas diferentes simultáneamente solo es posible si ha adquirido una IP adicional en el Área de clientes.
2.10. ¿Tiene el extractor vinculación al hardware?
No. Para el control de licencias se utiliza su IP.
2.11. Pregunta sobre la actualización - ¿actualizar solo el .exe? config/config.db y files/Rank-CMS/apps.json - ¿para qué son estos archivos?
A menos que se indique lo contrario, actualice solo el .exe. El primer archivo es para almacenar la configuración de A-Parser, y el segundo es la base para determinar el CMS y el funcionamiento del propio extractor ![]() Rank::CMS.
Rank::CMS.
2.12. Tengo Win Server 2008 Web Edition - el extractor no se inicia...
A-Parser no funcionará en esta versión del SO. La única opción es cambiar el SO.
2.13. Tengo un procesador de 4 núcleos. ¿Por qué A-Parser utiliza solo un núcleo?
A-Parser utiliza de 2 a 4 núcleos; los núcleos adicionales se utilizan solo durante el filtrado, el Constructor de resultados y Parse custom result.
2.14. Ha empezado a aparecerme un error de segmentación (segmentation failed, segmentation error). ¿Qué hacer?
Lo más probable es que su IP haya cambiado. Compruébelo en el Área de clientes.
2.15. Tengo Linux. A-Parser se inició, pero no se abre en el navegador. ¿Cómo solucionarlo?
Compruebe el firewall; lo más probable es que esté bloqueando el acceso.
2.16. Tengo Windows 7. A-Parser se inició, pero no se abre en el navegador y en el administrador de tareas no aparece el proceso Node.js. ¿Cómo solucionarlo?
Debe comprobar las actualizaciones de Windows e instalar las últimas disponibles. Específicamente, se necesita la actualización Windows 7 SP1.
2.17. A-Parser no se inicia y en aparser.log aparece el error FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Lo más probable es que surja un problema con alguna tarea (carpeta /config/tasks/), como consecuencia de un error de disco (por ejemplo, si se desconectó la alimentación de la PC sin un apagado correcto); se puede obtener más información si se ejecuta A-Parser con el flag -morelogs
Solución: ejecutar A-Parser con el parámetro -stoptasks. Si no ayuda, limpie todo el contenido de /config/tasks/. Si después de esto el problema persiste, instale el extractor de nuevo en un directorio nuevo y mueva el config del antiguo (si no está dañado).
3. Preguntas sobre la configuración de A-Parser y otros ajustes
3.1. ¿Cómo configurar el comprobador de proxy?
La instrucción detallada se encuentra aquí: configuración de proxy.
3.2. No hay proxies vivos - ¿por qué?
Compruebe su conexión a Internet, así como la corrección de la configuración del comprobador de proxy. Si todo se ha hecho correctamente, significa que en este momento su lista de proxies no contiene servidores operativos. La solución a este problema es: o bien usar otros proxies, o intentar de nuevo más tarde. Si utiliza nuestros proxies, compruebe la dirección IP en el Área de clientes en la sección Proxies (Proxy). También es posible que su proveedor bloquee el acceso a otros DNS; intente realizar los pasos descritos aquí: http://a-parser.com/threads/1240/#post-3582
3.3. ¿Cómo conectar antigate?
Instrucción detallada sobre la configuración de antigate aquí.
3.4. Cambié los parámetros en la configuración del extractor, pero no se aplicaron. ¿Por qué?
El ajuste preestablecido por defecto (default) no se puede cambiar; si se realizan cambios, debe pulsar Save as New Preset (Guardar como nuevo ajuste preestablecido) y luego utilizarlo en su tarea.
3.5. ¿Se pueden cambiar los ajustes de una tarea en ejecución?
Se puede, pero no todos. En una tarea en ejecución, puede pulsar pausa y en el mismo menú desplegable seleccionar Edit (Editar).
3.6. ¿Cómo importar un ajuste preestablecido?
Pulsar el botón junto al campo de selección de tarea en el Editor de tareas. Detalles aquí.
3.7. ¿Cómo configurar el extractor para que no use proxy?
En la configuración del extractor correspondiente, desmarcar la casilla Use proxy.
3.8. ¡No tengo el botón Añadir anulación / Override option!
Esta opción se puede añadir directamente en el Editor de tareas. Opciones del extractor.
3.9. ¿Cómo sobrescribir en el mismo archivo de resultados?
Al crear la tarea, activar la opción Overwrite file (Sobrescribir archivo).
3.10. ¿Dónde cambiar la contraseña del extractor?
3.11. Puse 6 millones de claves para extraer, también indiqué que todos los dominios fueran únicos. ¿Cómo hacer para que cuando ponga nuevos 6 millones de claves, se graben solo dominios únicos que no se crucen con la extracción anterior?
Es necesario utilizar la opción Keep unique (Guardar uniquización) al crear la primera tarea, e indicar la base guardada en la segunda. Detalles en Opciones adicionales del editor de tareas.
3.12. ¿Cómo evitar la limitación de 1000 resultados para Google?
Utilice la opción Parse all results.
3.13. ¿Cómo evitar la limitación de 1024 hilos en Linux?
3.14. ¿Cuál es el límite de hilos en Windows?
Hasta 10000 hilos.
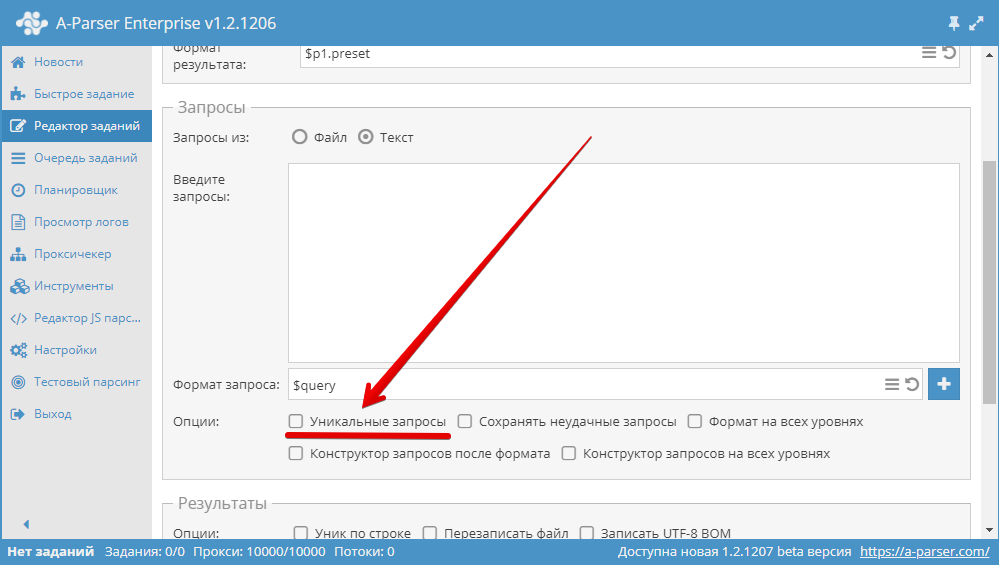
3.15. ¿Cómo hacer que las consultas sean únicas?
Utilizar la opción Unique queries (Consultas únicas) en el bloque Queries (Consultas) en el Editor de tareas.
3.16. ¿Cómo desactivar la comprobación de proxies?
En Configuración - Configuración del comprobador de proxy, seleccionar el comprobador deseado y añadir la marca No check proxies (No comprobar proxies). Guardar y seleccionar el ajuste preestablecido guardado.
3.17. ¿Qué es Proxy ban time? ¿Puedo ponerlo en 0?
Tiempo de baneo del proxy en segundos. Sí, puede.
3.18. ¿Cuál es la diferencia entre Exact Domain y Top Level Domain en el extractor  SE::Google::Position?
SE::Google::Position?
Exact Domain es una coincidencia estricta, es decir, si en los resultados aparece www.domain.com y buscamos domain.com, no habrá coincidencia. Top Level Domain compara todo el dominio de nivel superior, por lo que aquí sí habrá coincidencia.
3.19. Si ejecuto una extracción de prueba funciona todo, si es una normal obtengo el error Some error.
Lo más probable es que el problema esté en el DNS; intente seguir esta instrucción de configuración de DNS.
3.20. ¿Dónde se define el Formato de resultado?
3.21. En  SE::Google falta el idioma neerlandés, aunque en la configuración de Google sí está. ¿Por qué?
SE::Google falta el idioma neerlandés, aunque en la configuración de Google sí está. ¿Por qué?
El idioma neerlandés es Dutch, está en la lista. Detalles en la mejora sobre la adición del idioma neerlandés.
4. Preguntas sobre extracción de datos y errores durante el proceso
4.1. ¿Qué son los hilos?
Todos los procesadores modernos pueden realizar tareas en varios hilos, lo que aumenta significativamente la velocidad de su ejecución. Para comparar, se puede citar un autobús normal, que transporta una cierta cantidad de personas por unidad de tiempo: esto sería un procesamiento normal de un solo hilo, y un autobús de dos pisos, que transporta el doble de personas en el mismo tiempo: esto sería un procesamiento multihilo. A-Parser puede procesar simultáneamente hasta 10000 hilos.
4.2. La tarea no se inicia - dice Some Error - ¿por qué?
Compruebe la dirección IP en el Área de clientes.
4.3. Todas las consultas resultan fallidas, ¿qué hacer?
Lo más probable es que la tarea esté mal configurada o se esté utilizando un formato de consulta incorrecto. También compruebe si hay proxies vivos. Además, puede intentar aumentar la opción Request retries (más detalles aquí: consultas fallidas).
4.4. ¿Cuántas cuentas es necesario registrar para realizar la extracción de datos de 1 000 000 de palabras clave con  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
No se puede decir con exactitud cuántas cuentas se necesitan, ya que una cuenta puede dejar de ser válida tras un número desconocido de consultas. Pero siempre puede registrar nuevas cuentas utilizando el extractor  SE::Yandex::Register o simplemente añadir cuentas existentes al archivo files/SE-Yandex/accounts.txt.
SE::Yandex::Register o simplemente añadir cuentas existentes al archivo files/SE-Yandex/accounts.txt.
4.5. No se inicia la tarea, dice Error: Lock 100 threads failed(20 of limit 100 used) ¿qué hacer?
Es necesario aumentar la cantidad máxima de hilos disponibles en la configuración del extractor, o bien reducirla en la configuración de la tarea. Detalles en Configuración.
4.6. ¿Se pueden ejecutar 2 tareas simultáneamente?
Sí, A-Parser admite la ejecución de varias tareas simultáneamente. La cantidad de tareas que funcionan al mismo tiempo se regula en Configuración - Configuración general: Máximo de tareas activas.
4.7. ¿Dónde está el archivo con los resultados?
En la pestaña Tasks Queue (Tasks queue) (Cola de tareas), tras finalizar cada tarea, puede descargar los resultados del trabajo. Físicamente se encuentran en la carpeta results.
4.8. ¿Se puede descargar el archivo de resultados si la extracción no ha terminado?
No, mientras no haya terminado la extracción de datos, no se pueden descargar los resultados. Pero se puede copiar de la carpeta aparser/results con la tarea detenida o en pausa.
4.9. ¿Se puede con su extractor extraer 1.000.000 de enlaces por una sola consulta?
Sí, utilizando la opción Parse all results.
4.10. ¿Se puede realizar la extracción de datos con  Rank::CMS y
Rank::CMS y  Net::Whois sin proxy?
Net::Whois sin proxy?
Net::Whois - no es deseable.4.11. ¿Cómo extraer enlaces de Google?
Es necesario utilizar SE::Google.
4.12. ¿Puede el extractor seguir enlaces?
Sí, esto lo hace el extractor  HTML::LinkExtractor al usar la opción Analizar hasta nivel / Parse to level
HTML::LinkExtractor al usar la opción Analizar hasta nivel / Parse to level
4.13. Google extrae muy lento, ¿qué hacer?
En primer lugar, debe revisar los registros de la tarea; es posible que todas las consultas hayan fallado. Si es así, debe encontrar la razón por la cual las consultas fallan y corregirla. Al realizar la extracción de datos con SE::Google, los intentos fallidos en los registros suelen deberse a que Google muestra captchas, lo cual es normal. Puede conectar Anti-Captcha para omitir los captchas y evitar que el extractor agote los intentos.
Además, hay un artículo donde se describen los factores que influyen en la velocidad de extracción de datos y cómo lo hacen: velocidad y principio de funcionamiento de los extractores.
4.14. ¿Se puede con su extractor extraer enlaces en los que el texto esté solo en japonés?
Sí, para ello es necesario establecer el idioma necesario en la configuración del extractor, así como utilizar palabras clave en japonés.
4.15. ¿Se puede con su extractor extraer enlaces solo en la zona de dominio .de o .ru?
Sí. Para ello debe utilizar un filtro.
4.16. ¿Cómo obtener cada resultado en el archivo en una línea nueva?
Al formatear el resultado utilice \n. Ejemplo:
$serp.format('$link\n')
4.17. ¿Cómo extraer el top 10 de sitios de Google?
Aquí está el ajuste preestablecido:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Añado una tarea, voy a la pestaña Cola de tareas - ¡y no está allí! ¿Por qué?
O bien se ha cometido un error al crear la tarea, o bien ya se ha completado y ha pasado a Completed (Finalizadas).
4.19. Dice que el archivo no está en utf-8, pero no lo he cambiado y ya es utf-8, ¿qué hacer?
Compruébelo de nuevo. También intente cambiar la codificación, por ejemplo con la ayuda de Notepad++.
4.20. En el archivo de resultados todo está en una sola línea, aunque en la tarea puse salto de línea - ¿por qué?
En la configuración adicional de A-Parser debe utilizar el salto de línea CRLF (Windows).
Pero si ya ha realizado la extracción sin esta opción, utilice para la visualización un visor más avanzado, por ejemplo Notepad++.
4.21. ¿Cuánto tiempo se tarda en comprobar la frecuencia de consultas en Yandex para 1.000 consultas?
Este indicador depende mucho de los parámetros de la tarea, las características del servidor, la calidad de los proxies, etc., por lo que es imposible dar una respuesta única.
4.22. ¿Cómo configuro el extractor para que el resultado sea consulta-enlace?
Formato de resultado:
$p1.serp.format('$query: $link\n')
El resultado será:
consulta: enlace 1
consulta: enlace 2
consulta: enlace 3
4.23. ¿Cómo vuelvo a procesar las consultas fallidas y dónde se guardan?
Para que las consultas fallidas se guarden, debe seleccionar la opción correspondiente en el bloque Queries (Consultas) en el Editor de tareas. Las consultas fallidas se guardan en queries\failed. Debe crear una nueva tarea e indicar como archivo de consultas el archivo con las consultas fallidas.
4.24. ¿Cómo deshacerse de las etiquetas HTML al extraer texto?
Utilice la opción Remove HTML tags en el Constructor de resultados.
4.25. ¿Cómo hacer para que se extraigan solo los dominios?
Utilice la opción Extract Domain en el Constructor de resultados.
4.26. ¿Cuál es el tamaño máximo de archivo de consultas que se puede usar en el extractor?
Los tamaños de los archivos de consultas y resultados no están limitados y pueden alcanzar valores de terabytes.
4.27. ¿Por qué cuando introduzco texto en el campo de consultas, el extractor da Queries length limited to 8192 characters?
Esto ocurre porque la longitud de la consulta está limitada a 8192 caracteres. Para utilizar consultas más largas, use archivos como fuente de consultas.
4.28. ¿Qué significa Hilos en espera - 3?
Esto significa que faltan proxies. Reduzca la cantidad de hilos o aumente la cantidad de proxies.
4.29. En la extracción de prueba dice 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) y no extrae, ¿por qué?
Esto indica que los proxies no funcionan.
4.30. ¿Cuál es la diferencia entre el idioma de los resultados y el país de búsqueda en el extractor de Google?
La diferencia es la siguiente: el país de búsqueda es la vinculación de los resultados a un país específico. Por ejemplo, si busca comprar ventanas vinculado a un país específico, tendrán prioridad los sitios que ofrecen comprar ventanas precisamente en ese país. Y el idioma de los resultados es el idioma en el que deben entregarse los resultados.
4.31. No se me extrae un sitio determinado. ¿Qué puede ser?
A menudo el problema es que ocurre un bloqueo debido a un user-agent antiguo en el lado del servidor. Se soluciona con un nuevo user-agent o con el siguiente código en el parámetro User agent:
[% tools.ua.random() %]
4.32. El extractor se cuelga, se cierra. En el log aparece la línea syswrite: No space left on device
A A-Parser le falta espacio en el disco duro. Libere más espacio.
4.33. El extractor ha empezado a dar none en los resultados (o un resultado claramente incorrecto)
4.34. Constantemente aparece una ventana con el texto Failed fetch news
4.35. ¿Cómo mostrar los n primeros resultados de búsqueda?
4.36. ¿Cómo rastrear la cadena de redirecciones?
4.37. ¿Cómo comprobar la indexación de un enlace en el donante?
Para tales fines existe un extractor independiente:  Check::BackLink.
Más detalles en la discusión.
Check::BackLink.
Más detalles en la discusión.
4.38. El extractor se cierra en Linux. En el log aparece esta entrada: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Lo más probable es que necesite tunear el número de hilos, como se indica en la Documentación: Tuning de Linux para un mayor número de hilos.
4.39. ¿Dónde se pueden ver todos los parámetros posibles para su uso a través de la API?
Obtención de consulta API en la interfaz.
Además, se puede generar la configuración completa de la tarea en JSON. Para ello, debe tomar el código de la tarea y decodificarlo de base64.
4.40. Estoy descargando imágenes con  Net::HTTP, pero por alguna razón todas están dañadas. ¿Qué debo hacer?
Net::HTTP, pero por alguna razón todas están dañadas. ¿Qué debo hacer?
1) Compruebe el parámetro Max body size; posiblemente necesite aumentarlo. 2) Compruebe en la configuración de A-Parser el formato de salto de línea: Configuración adicional - Salto de línea.
Para que la imagen no esté dañada, debe utilizarse el formato UNIX.
4.41. ¿Cómo obtener el admin contact de WHOIS?
Esta tarea se resuelve fácilmente con la ayuda de la función Parse custom result y una expresión regular. Detalles en la discusión.
4.42. Expresión regular para extraer teléfonos
4.43. Identificación de sitios sin versión móvil
4.44. ¿Cómo saber el nombre del servidor NS?
4.45. ¿Cómo extraer enlaces a la caché de Yandex?
4.46. ¿Cómo extraer enlaces a todas las páginas de un sitio?
4.47. ¿Cómo extraer el title de una página?
4.48. ¿Cómo extraer todos los sitios en una zona de dominio determinada?
4.49. ¿Cómo recopilar todas las URL con parámetros?
4.50. ¿Cómo filtrar resultados por varios criterios y dividirlos en el informe?
4.51. ¿Cómo simplificar la construcción del filtro?
4.52. ¿Cómo clasificar por archivos en función del resultado?
4.53. Create new result directory every X number of files (English)
4.54. Primeros pasos de trabajo con WordStat
4.55. Recopilación de bloques de texto >1000 caracteres
4.56. Salida de una cantidad determinada de texto de la página
Esto también se resuelve con la ayuda de Template Toolkit. Más detalles en la discusión.
4.57. Comprobación de competencia y presencia en el título en Google
4.58. Filtrado por cantidad de apariciones de la consulta en el ancla y el fragmento
4.59. ¿Cómo obtener el contenido de un artículo en una sola línea?
4.60. ¿Cómo comparar dos fechas de cadena?
4.61. ¿Cómo extraer palabras resaltadas del fragmento?
4.62. Ejemplo de tarea utilizando varios extractores
4.63. ¿Cómo mezclar líneas en el resultado y cómo mostrar una cantidad aleatoria de resultados?
4.64. ¿Cómo firmar el resultado con MD5?
4.65. ¿Cómo convertir una fecha de Unix timestamp a una representación de cadena?
4.66. Parse to level, cómo extraer con limitación?
4.67. El extractor se cae en Linux al iniciar una tarea. En el log aparecen estas líneas: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
Es necesario ejecutar el comando en la consola:
apt-get --reinstall --purge install netbase
4.68. Error Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
Debe ejecutar A-Parser no como root. Específicamente: desde el usuario root debe crear un nuevo usuario sin privilegios de root (si ya existe uno, simplemente úselo) y luego permitir que este usuario interactúe con el directorio de A-Parser, después debe iniciar sesión con el nuevo usuario y ejecutarlo desde él.
Bajo el usuario root crear un usuario, puede seguir esta guía.
Para permitir que el usuario creado interactúe con el directorio de A-Parser, debe otorgarle permisos. Para ello, entre como usuario root y con el comando otorgue los permisos:
chown -R user:user aparser
4.69. Error Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Bajo el usuario root ejecutar el comando:
sysctl -w kernel.unprivileged_userns_clone=1
No se requiere reiniciar A-Parser.
Para CentOS 7 la solución está en este tema.
Bajo el usuario root ejecutar el comando:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Luego reiniciar sysctl con el comando:
sysctl -p
4.70. Error JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
El error ocurre debido a la falta de librerías en el SO para el funcionamiento de Chrome.
La lista de librerías necesarias para el funcionamiento de Chrome se puede encontrar en Chrome headless doesn't launch on UNIX.
4.71. ¿Por qué no se resuelve el captcha? En el log se ve que de xevil A-Parser recibió signos de interrogación en lugar de la respuesta del captcha
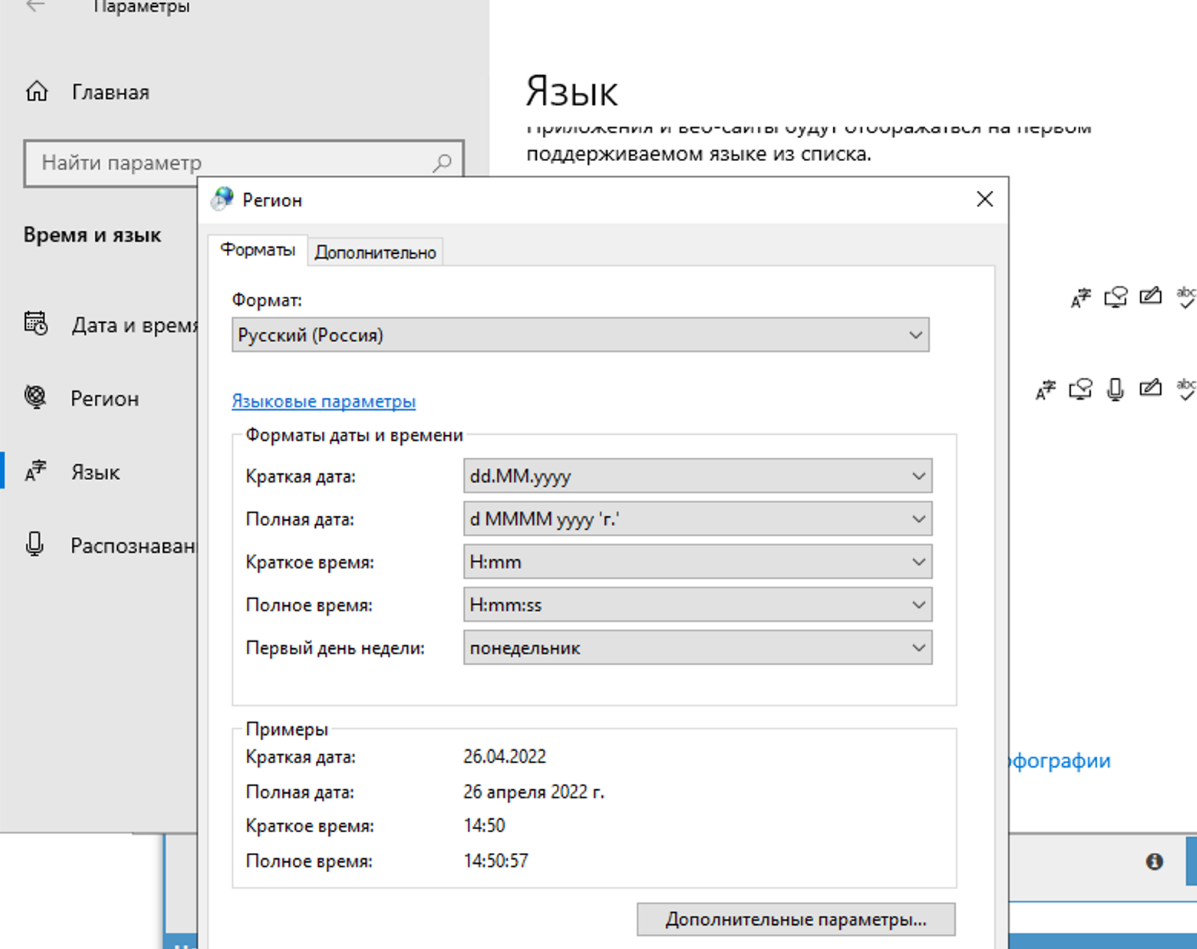
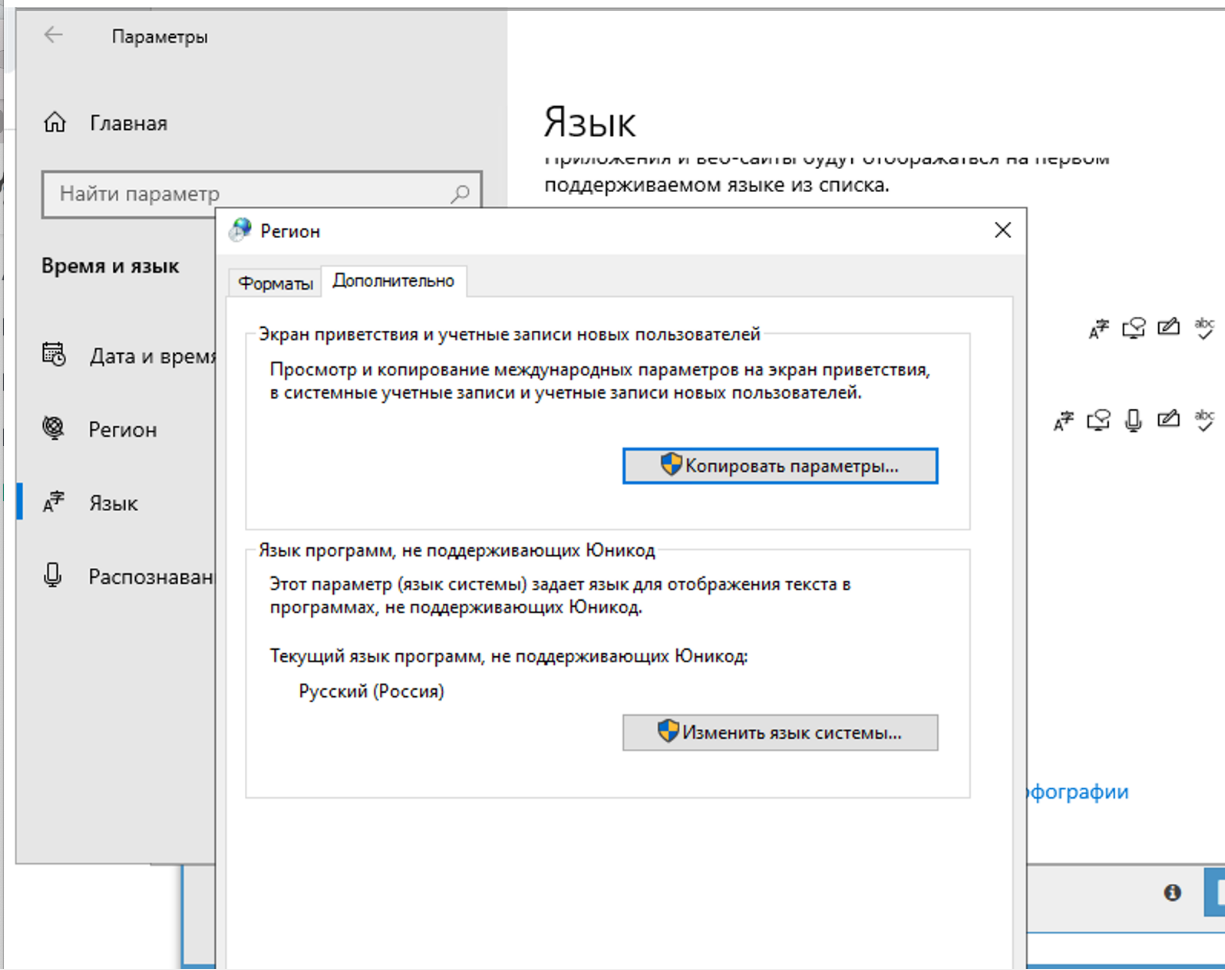
En la configuración regional debe cambiar a ruso.
Debe cambiar solo en la pestaña avanzado. Esto no influye en la resolución del captcha, pero en el propio xrumer habrá un problema con la codificación si se cambia en ambos sitios.