Control de Chrome (puppeteer)
A-Parser permite utilizar el navegador Chrome (Chromium) como motor para descargar y renderizar páginas, utilizando la popular biblioteca puppeteer.
Principales ventajas de trabajar con puppeteer junto con A-Parser:
- soporte de proxies independientes para cada pestaña del navegador
- gestión multihilo de las pestañas del navegador
- intercepción de solicitudes
- todas las capacidades de A-Parser para la gestión de colas, formación de consultas y procesamiento de resultados
El uso del navegador Chrome abre las siguientes posibilidades:
- renderizado de
DOMyJavaScript - posibilidad de trabajo interactivo con elementos de los sitios:
- completar formularios
- navegar por enlaces
- drag & drop
- carga de archivos
- emulación de ratón
- y mucho más, se puede automatizar cualquier acción estándar
- evasión más sencilla de diversas protecciones contra la extracción de datos, ya que el navegador Chromium es lo más parecido posible al utilizado por los usuarios
- posibilidad de trabajar en modo
Headless, es decir, sin interfaz gráfica del navegador, lo que permite ahorrar recursos y ejecutar el navegador en servidores sin entorno gráfico
Es necesario tener en cuenta que el funcionamiento del navegador es mucho más exigente en recursos (CPU, Memoria) que los hilos normales de A-Parser
Dependiendo de la complejidad del sitio, se recomienda utilizar un número de hilos (pestañas del navegador) no superior a 1-2 por cada núcleo de procesador disponible, por ejemplo, para procesadores de 8 núcleos - de 8 a 16 pestañas
Ejemplo de uso
Analicemos el ejemplo del extractor Chrome::ScreenshotMaker2:
- el extractor realiza capturas de pantalla de sitios del tamaño especificado y también puede reducir (escalar) la imagen
- puede utilizar proxy opcionalmente
- crea una pestaña de navegador independiente para cada hilo de A-Parser
import { BaseParser, PuppeteerTypes } from 'a-parser-types';
let browser: PuppeteerTypes.Browser;
let jimp;
class JS_Chrome_ScreenshotsMaker2 extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.2.1',
results: {
flat: [
['screenshot', 'PNG screenshot'],
]
},
results_format: '$screenshot',
load_timeout: 30,
width: 1024,
height: 768,
log_screenshots: 0,
headless: 1,
};
static editableConf: typeof BaseParser.editableConf = [
['log_screenshots', ['checkbox', 'Log Screenshots']],
['width', ['textfield', 'Viewport Width']],
['height', ['textfield', 'Viewport Height']],
['resize_width', ['textfield', 'Resize Width']],
['resize_height', ['textfield', 'Resize Height']],
['headless', ['checkbox', 'Chrome Headless']],
];
async init() {
// inicializamos el navegador
browser = await this.puppeteer.launch({
headless: this.conf.headless,
logConnections: false,
defaultViewport: {
width: parseInt(this.conf.width),
height: parseInt(this.conf.height),
}
});
if (this.conf.resize_width) {
// conectamos el módulo jimp si es necesario redimensionar la captura de pantalla
jimp = require('jimp');
};
};
async destroy() {
// cerramos el navegador al finalizar la tarea
if (browser)
await browser.close();
}
page: PuppeteerTypes.Page;
async threadInit() {
// creamos una página de navegador al inicializar el hilo
this.page = await browser.newPage();
// métodos estándar de puppeteer
await this.page.setCacheEnabled(true);
await this.page.setDefaultNavigationTimeout(this.conf.timeout * 1000);
// indicamos a A-Parser que use proxy para esta página
await this.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
async parse(set, results) {
const self = this;
const { conf, page } = self;
for (let attempt = 1; attempt <= conf.proxyretries; attempt++) {
try {
self.logger.put(`Attempt #${attempt}`);
// navegamos a la página indicada en la consulta
await page.goto(set.query);
// ocultamos la barra de desplazamiento para la captura de pantalla
await page.evaluate(() => { document.querySelector('html').style.overflow = 'hidden'; });
// obtenemos la captura de pantalla
results.screenshot = await page.screenshot();
if (parseInt(conf.resize_width)) {
// si es necesario redimensionamos la imagen
let image = await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width), parseInt(conf.resize_height));
results.screenshot = await image.getBufferAsync('image/png');
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt("" + (results.screenshot.length / 1024))}KB`);
if (conf.log_screenshots)
self.logger.putHTML("<img src='data:image/png;base64," + results.screenshot.toString('base64') + "'>");
results.success = 1;
// cerramos las conexiones actuales, ya que el navegador utiliza keep-alive
await self.puppeteer.closeActiveConnections();
break;
}
catch (error) {
self.logger.put(`Fetch page error: ${error}`);
// cerramos las conexiones actuales, ya que el navegador utiliza keep-alive
await self.puppeteer.closeActiveConnections();
// cambiamos el proxy para la pestaña del navegador
await self.proxy.next();
}
}
return results;
}
}
Este ejemplo demuestra la facilidad de uso de diferentes proxies para cada pestaña, así como el funcionamiento multihilo (1 hilo = 1 pestaña del navegador)
Descripción de métodos
await this.puppeteer.launch(opts?)
Este método es análogo al método .launch de la biblioteca puppeteer, inicia el navegador Chromium con las opciones necesarias opts. La principal diferencia radica en la integración con A-Parser y el soporte de proxy para cada pestaña, así como en la presencia de opciones adicionales:
logConnections?: boolean
Activa el registro de todas las conexiones (independientemente de si se usa proxy o no), la salida del registro se realiza por separado por hilos
stealth?: boolean
Utiliza el complemento puppeteer-extra para enmascarar Chromium como un Chrome real
stealthOpts?: any
Opciones adicionales para el complemento puppeteer-extra
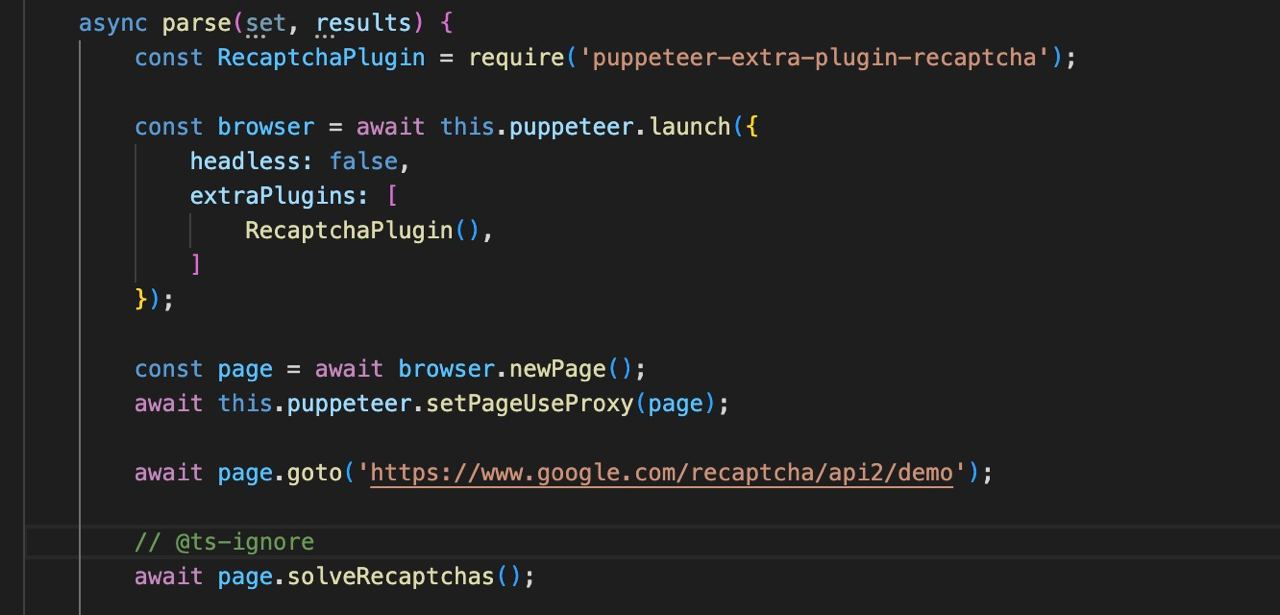
extraPlugins?: array
Uso de complementos adicionales, como por ejemplo puppeteer-extra/packages
Otras opciones
Todas las demás opciones de inicio se pueden consultar en la documentación original de puppeteer
await this.puppeteer.setPageUseProxy(page)
Este método vincula la página del navegador con el hilo de A-Parser para el correcto funcionamiento del proxy, debe llamarse inmediatamente después de crear la página:
const page = await browser.newPage();
await this.puppeteer.setPageUseProxy(page);
await this.puppeteer.closeActiveConnections(page?)
Este método debe llamarse después de completar el procesamiento de la consulta o antes de cambiar el proxy para procesar el siguiente intento
El navegador Chrome por defecto deja abiertas las conexiones con los sitios a los que se conecta, este método permite controlar el número de recursos utilizados y también reduce la carga sobre el proxy
El argumento page es opcional; si se llama sin argumento, A-Parser cerrará las conexiones de la pestaña vinculada al hilo actual
await this.puppeteer.logScreenshot()
El método registra una captura de pantalla de la página actual