Gestion de Chrome (puppeteer)
A-Parser permet d'utiliser le navigateur Chrome (Chromium) comme moteur de téléchargement et de rendu de pages, en utilisant la bibliothèque populaire puppeteer.
Principaux avantages de l'utilisation de puppeteer avec A-Parser :
- support de proxies séparés pour chaque onglet du navigateur
- gestion multithread des onglets du navigateur
- interception des requêtes
- toutes les fonctionnalités d'A-Parser pour la gestion de la file d'attente, la génération des requêtes et le traitement des résultats
L'utilisation du navigateur Chrome ouvre les possibilités suivantes :
- rendu du
DOMet duJavaScript - possibilité d'interaction avec les éléments des sites :
- remplissage de formulaires
- navigation via les liens
- drag & drop
- téléchargement de fichiers
- émulation de la souris
- et bien plus encore, toutes les actions standard peuvent être automatisées
- contournement plus facile des diverses protections contre la collecte de données, car le navigateur Chromium ressemble au maximum à celui utilisé par les utilisateurs
- possibilité de travailler en mode
Headless, c'est-à-dire sans interface graphique du navigateur, ce qui permet d'économiser des ressources et de lancer le navigateur sur des serveurs sans environnement graphique
Il faut tenir compte du fait que le fonctionnement du navigateur est beaucoup plus exigeant en ressources (CPU, Mémoire) que les threads ordinaires d'A-Parser.
Selon la complexité du site, il est recommandé d'utiliser un nombre de threads (onglets du navigateur) ne dépassant pas 1 à 2 pour chaque cœur de processeur disponible, par exemple pour des processeurs à 8 cœurs - de 8 à 16 onglets.
Exemple d'utilisation
Analysons l'exemple du scraper Chrome::ScreenshotMaker2 :
- le scraper prend des captures d'écran de sites à la taille indiquée et peut également réduire (redimensionner) l'image
- peut optionnellement utiliser des proxies
- crée un onglet de navigateur distinct pour chaque thread d'A-Parser
import { BaseParser, PuppeteerTypes } from 'a-parser-types';
let browser: PuppeteerTypes.Browser;
let jimp;
class JS_Chrome_ScreenshotsMaker2 extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.2.1',
results: {
flat: [
['screenshot', 'PNG screenshot'],
]
},
results_format: '$screenshot',
load_timeout: 30,
width: 1024,
height: 768,
log_screenshots: 0,
headless: 1,
};
static editableConf: typeof BaseParser.editableConf = [
['log_screenshots', ['checkbox', 'Log Screenshots']],
['width', ['textfield', 'Viewport Width']],
['height', ['textfield', 'Viewport Height']],
['resize_width', ['textfield', 'Resize Width']],
['resize_height', ['textfield', 'Resize Height']],
['headless', ['checkbox', 'Chrome Headless']],
];
async init() {
// initialisons le navigateur
browser = await this.puppeteer.launch({
headless: this.conf.headless,
logConnections: false,
defaultViewport: {
width: parseInt(this.conf.width),
height: parseInt(this.conf.height),
}
});
if (this.conf.resize_width) {
// connectons le module jimp si nécessaire pour redimensionner la capture d'écran
jimp = require('jimp');
};
};
async destroy() {
// fermons le navigateur à la fin de la tâche
if (browser)
await browser.close();
}
page: PuppeteerTypes.Page;
async threadInit() {
// créons une page de navigateur lors de l'initialisation du thread
this.page = await browser.newPage();
// méthodes standard de puppeteer
await this.page.setCacheEnabled(true);
await this.page.setDefaultNavigationTimeout(this.conf.timeout * 1000);
// indiquons à A-Parser d'utiliser un proxy pour cette page
await this.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
async parse(set, results) {
const self = this;
const { conf, page } = self;
for (let attempt = 1; attempt <= conf.proxyretries; attempt++) {
try {
self.logger.put(`Attempt #${attempt}`);
// allons à la page indiquée dans la requête
await page.goto(set.query);
// masquons la barre de défilement pour la capture d'écran
await page.evaluate(() => { document.querySelector('html').style.overflow = 'hidden'; });
// obtenons la capture d'écran
results.screenshot = await page.screenshot();
if (parseInt(conf.resize_width)) {
// redimensionnons l'image si nécessaire
let image = await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width), parseInt(conf.resize_height));
results.screenshot = await image.getBufferAsync('image/png');
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt("" + (results.screenshot.length / 1024))}KB`);
if (conf.log_screenshots)
self.logger.putHTML("<img src='data:image/png;base64," + results.screenshot.toString('base64') + "'>");
results.success = 1;
// fermons les connexions actuelles car le navigateur utilise keep-alive
await self.puppeteer.closeActiveConnections();
break;
}
catch (error) {
self.logger.put(`Fetch page error: ${error}`);
// fermons les connexions actuelles car le navigateur utilise keep-alive
await self.puppeteer.closeActiveConnections();
// changeons le proxy pour l'onglet du navigateur
await self.proxy.next();
}
}
return results;
}
}
Cet exemple démontre la simplicité d'utilisation de différents proxies pour chaque onglet, ainsi que le fonctionnement multithread (1 thread = 1 onglet de navigateur).
Description des méthodes
await this.puppeteer.launch(opts?)
Cette méthode est analogue à la méthode .launch de la bibliothèque puppeteer, elle lance le navigateur Chromium avec les options opts nécessaires. La principale différence réside dans l'intégration avec A-Parser et le support des proxies pour chaque onglet, ainsi que dans la présence d'options supplémentaires :
logConnections?: boolean
Active la journalisation de toutes les connexions (qu'elles utilisent un proxy ou non), la sortie du log est effectuée séparément par thread.
stealth?: boolean
Utilise le plugin puppeteer-extra pour masquer Chromium en tant que véritable Chrome.
stealthOpts?: any
Options supplémentaires pour le plugin puppeteer-extra.
extraPlugins?: array
Utilisation de plugins supplémentaires, comme par exemple puppeteer-extra/packages.
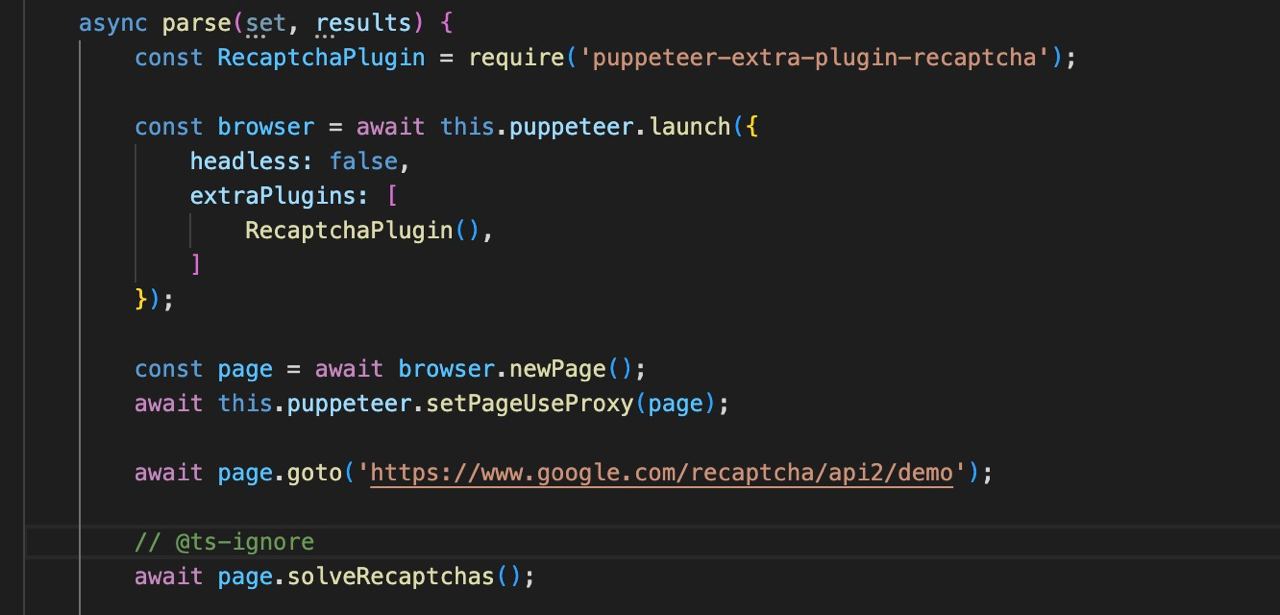
Autres options
Toutes les autres options de lancement peuvent être consultées dans la documentation originale de puppeteer.
await this.puppeteer.setPageUseProxy(page)
Cette méthode lie la page du navigateur au thread d'A-Parser pour le bon fonctionnement du proxy, elle doit être appelée immédiatement après la création de la page :
const page = await browser.newPage();
await this.puppeteer.setPageUseProxy(page);
await this.puppeteer.closeActiveConnections(page?)
Cette méthode doit être appelée après la fin du traitement de la requête ou avant de changer de proxy pour traiter la tentative suivante.
Le navigateur Chrome laisse par défaut les connexions ouvertes avec les sites auxquels il se connecte, cette méthode permet de contrôler le nombre de ressources utilisées et réduit également la charge sur le proxy.
L'argument page est optionnel, lors d'un appel sans argument, A-Parser fermera les connexions pour l'onglet lié au thread actuel.
await this.puppeteer.logScreenshot()
La méthode enregistre une capture d'écran de la page actuelle dans le log.