Используйте Конструктор результатов и либо RegEx match (чтобы регуляркой забирать вместе с http), либо Extract domain/Extract Top Domain
https://a-parser.com/wiki/result-builder/
https://a-parser.com/wiki/result-builder/
Следуйте инструкциям в видео ниже, чтобы узнать, как установить наш сайт как веб-приложение на главный экран вашего устройства.
Примечание: Эта функция может быть недоступна в некоторых браузерах.
Не понятно почему не извлекает домен верхнего уровня с такими настройками https://prnt.sc/k02x52Используйте Конструктор результатов и либо RegEx match (чтобы регуляркой забирать вместе с http), либо Extract domain/Extract Top Domain
https://a-parser.com/wiki/result-builder/
привет, тоже сталкивался с таким. Одно из решений вот этот пресет из каталога https://a-parser.com/resources/183/ Пресет для получения значения host из ссылкиНе понятно почему не извлекает домен верхнего уровня с такими настройками https://prnt.sc/k02x52
Здравствуйте. Замените $p1.query на $p1.serp.$i.link в конструкторе результатовНе понятно почему не извлекает домен верхнего уровня с такими настройками https://prnt.sc/k02x52

В целом информация актуальна. Разве что сейчас в качестве парсера Гугла лучше использовать1. актуальна ли информация, которая здесь в помощь?
 SE::Google::Modern.
SE::Google::Modern.парсишь признаками, а как словарь догрузить к запросам? я в запросы добавил все признаки форумов но не могу понять как добавить к запросу словарь[[/QUOTE]Как собирать главные страницы форумов phpbb
при изменении стираются все настройки пресета.да, поменяй просто гугл на яндекс, остальное все также
Для парсинга будем использовать всего одно ключевое слово "forum" дополняя его подстановками цифр и букв, при этом мы не будем использовать операторы inurl: что значительно увеличит скорость парсинга
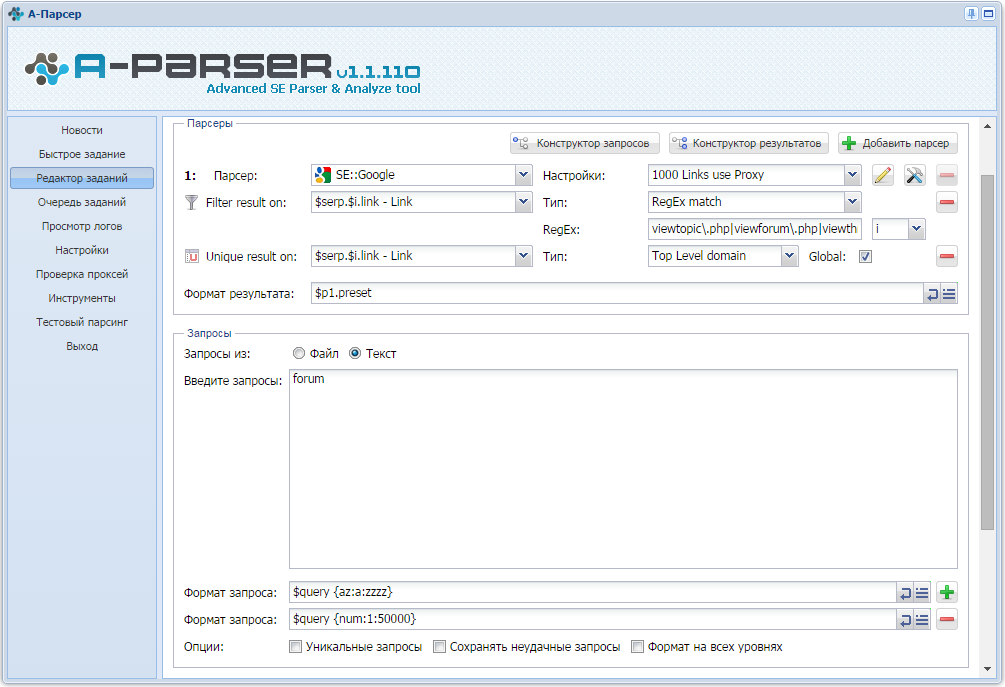
- Используем парсер
SE::Google с пресетом 1000 Links use Proxy
- Добавляем фильтрацию получаемых ссылок по регулярному выражению, под которое подходят только популярные форумы
- Добавляем уникализацию ссылок по главному домену
- Используем 2 формата запросов - перебор символов от a до zzzz и чисел от 1 до 50000
Код:eyJwcmVzZXQiOiJkZWZhdWx0IiwidmFsdWUiOnsicGFyc2VycyI6W1siU0U6Okdv b2dsZSIsIjEwMDAgTGlua3MgdXNlIFByb3h5Iix7InR5cGUiOiJmaWx0ZXIiLCJy ZXN1bHQiOlsic2VycCIsImxpbmsiXSwiZmlsdGVyVHlwZSI6InJlbWF0Y2giLCJ2 YWx1ZSI6InZpZXd0b3BpY1xcLnBocHx2aWV3Zm9ydW1cXC5waHB8dmlld3RocmVh ZFxcLnBocHx0aHJlYWQtfGZvcnVtXFwucGhwfHNob3d0aHJlYWRcXC5waHB8Zm9y dW1kaXNwbGF5XFwucGhwfFlhQkJcXC5wbHxZYUJCXFwuY2dpfHViYnRocmVhZHNc XC5waHB8dWx0aW1hdGViYlxcLnBocHx1bHRpbWF0ZWJiXFwuY2dpfGluZGV4XFwu cGhwXFw/c2hvd3RvcGljPXx0aHJlYWRzfHRvcGljfG1lbWJlcnN8bWVtYmVyXFwu cGhwfG1lbWJlcmxpc3RcXC5waHB8cHJvZmlsZVxcLnBocHx1c2VyaW5mb1xcLnBo cHx2aWV3dG9waWN8dmlld2ZvcnVtfHZpZXd0aHJlYWR8dG9waWN8dGhyZWFkfHNo b3d0aHJlYWR8c2hvd3RvcGljfHNob3dmb3J1bSIsIm9wdGlvbiI6ImkifSx7InR5 cGUiOiJ1bmlxdWUiLCJyZXN1bHQiOlsic2VycCIsImxpbmsiXSwidW5pcXVlVHlw ZSI6InRvcGRvbWFpbiIsInVuaXF1ZUdsb2JhbCI6dHJ1ZX1dXSwicmVzdWx0c0Zv cm1hdCI6IiRwMS5wcmVzZXQiLCJyZXN1bHRzU2F2ZVRvIjoiZmlsZSIsInJlc3Vs dHNGaWxlTmFtZSI6Ik5vdi0wNV8xMS01Mi0xNS50eHQiLCJhZGRpdGlvbmFsRm9y bWF0cyI6W10sInJlc3VsdHNVbmlxdWUiOiJubyIsInF1ZXJ5Rm9ybWF0IjpbIiRx dWVyeSB7YXo6YTp6enp6fSIsIiRxdWVyeSB7bnVtOjE6NTAwMDB9Il0sInVuaXF1 ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmllcyI6ZmFsc2UsIml0ZXJh dG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwi a2VlcFVuaXF1ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJl cGVuZCI6IiIsInJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwi cmVzdWx0c0J1aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX0sInBhcnNl cnNDb25mUHJlc2V0cyI6eyJTRTo6R29vZ2xlIjp7IjEwMDAgTGlua3MgdXNlIFBy b3h5Ijp7InF1ZXJ5Zm9ybWF0IjoiJHF1ZXJ5IiwicGFyc2Vub3Rmb3VuZCI6dHJ1 ZSwiZ2wiOiIiLCJwYWdlY291bnQiOiIxMCIsImRvX2d6aXAiOnRydWUsImRvbWFp biI6Ind3dy5nb29nbGUuY29tIiwidGltZW91dCI6IjYwIiwidXNlcHJveHkiOnRy dWUsImFudGlnYXRlcHJlc2V0IjoiZGVmYXVsdCIsImV4dHJhcXVlcnkiOiIiLCJs b2NhdGlvbiI6IiIsInVzZXNlc3Npb25zIjp0cnVlLCJzZXJwdGltZSI6IiIsImxp bmtzcGVycGFnZSI6IjEwMCIsImZpbHRlciI6dHJ1ZSwic2VycCI6IiIsInVzZWFu dGlnYXRlIjpmYWxzZSwicHJveHlyZXRyaWVzIjoiMTUiLCJyZXF1ZXN0ZGVsYXki OiIwIiwicHJveHliYW5uZWRjbGVhbnVwIjoiNjAwIiwiZm9ybWF0cmVzdWx0Ijoi JHNlcnAuZm9ybWF0KCckbGlua1xcbicpIiwicmF3ZGF0YSI6MCwibHIiOiIiLCJ1 c2VjYXB0Y2hha2lsbGVyIjpmYWxzZSwibWF4X3NpemUiOiIyMDQ4MDAifX19fQ==
В результате получаем базу ссылок на форумы, содержащую 421618 уникальных домена:
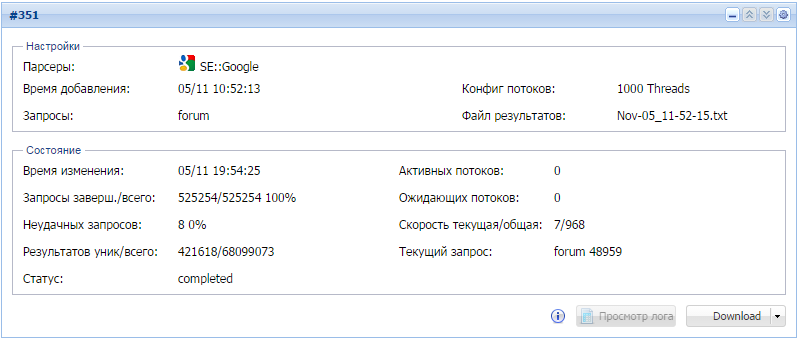
За 9 часов работы:
- Было обработано 525254 запроса на максимальную глубину
- Спаршено 68 миллионов ссылок, 420к из которых подходят под фильтр и уникальны по домену
- Средняя скорость парсинга составила 1000 запросов в минуту
По каким признакам или как парсер должен определять гео форума?Нужно отфильтровать по гео чтобы фармило немецкие и австрийские форумы, как это можно сделать?
Их уже нетотнюдь, авмпрокси безлимит 195 в месяц
A-Parser - это профессиональная платформа для сбора данных промышленного масштаба: 10 000+ потоков, 110+ парсеров и гибкость Node.js. Автоматизируйте задачи в SEO, e-commerce и арбитраже трафика с непревзойденной скоростью и масштабируемостью
Нужна помощь с настройкой или работой парсера? Напишите в поддержку, поможем довести все до результата.
Написать в поддержку