Pourquoi les mises à jour sont-elles nécessaires et pourquoi sont-elles payantes ?
A-Parser évolue constamment. Avec la sortie de nouvelles versions, des améliorations et des corrections sont apportées. Dans cet article, nous allons analyser ce que représentent les mises à jour, en quoi elles diffèrent de la licence, quel rôle elles jouent et pourquoi elles sont payantes.
Licence ≠ mises à jour
En faisant l'acquisition de A-Parser, vous obtenez une licence perpétuelle pour son utilisation et 3 à 6 mois de mises à jour gratuites selon la licence achetée. Après la fin de la période de mises à jour gratuites, vous pouvez mettre à jour vers la dernière version stable disponible et continuer à utiliser le scraper dans son intégralité — dans la mesure où la version disponible au moment de la fin de l'abonnement le permet.
Pour renouveler l'abonnement, vous pouvez acheter l'un des trois packs de mises à jour : pour 3 mois, un an et à vie pour 49 $, 149 $ et 399 $ respectivement.
Vous n'avez pas besoin de payer pour les mises à jour en permanence. Il n'est pas nécessaire de payer pour la période pendant laquelle il n'y avait pas d'abonnement aux mises à jour.
Pourquoi les mises à jour sont-elles payantes ?
🐞 Corrections
Les sites et divers types de ressources évoluent assez rapidement. Tout changement, même le plus insignifiant de la part du site cible, peut influencer la collecte de données. Cela se produit parce qu'initialement les scrapers sont conçus pour une structure spécifique et les changements dans la mise en page, la protection ou d'autres mécaniques internes diverses entraînent des données incorrectes dans les résultats, leur absence totale et d'autres erreurs. La collecte de données elle-même affecte négativement les serveurs dédiés aux sites : les requêtes augmentent et par conséquent la charge aussi. Les services perdant des profits sont contraints de chercher une issue à cette situation, ce qui fait apparaître de nouveaux types de protections et évoluer les anciennes.
À chaque changement de ce type, il est nécessaire d'apporter des corrections. Derrière chacune d'elles se trouvent l'analyse du problème, la recherche d'une solution et sa mise en œuvre.
🧰 Chaque jour, chaque scraper intégré passe par un système de tests internes. Si les requêtes de test réussissent, les valeurs obtenues en résultat sont vérifiées. Un test échoué signale des erreurs présentes dans le scraper. Grâce aux tests, nous réagissons rapidement aux pannes et commençons immédiatement le travail de correction.
Parmi les plus complexes, demandés et donc prioritaires pour nous – les scrapers des moteurs de recherche Yandex et Google. Chacun se compose de nombreuses parties résolvant une tâche spécifique. Parmi elles, la préparation de la requête, la génération des en-têtes, l'obtention du code source de la page, divers formatages de résultats, le travail avec le captcha, etc. Tout cela doit être maintenu en état de fonctionnement. Le scraper prévoit la présence de variables contenant toutes les données nécessaires de la page : résultats de recherche, annonces publicitaires, mots-clés associés et autres valeurs. Elles sont extraites à l'aide d'expressions régulières supposant la présence sur la page d'une certaine structure de document (ordre des éléments, leurs types, classes et autres signes possibles). Lors d'un changement critique de cette structure, la regex qui convenait à sa version précédente cesse d'extraire le fragment souhaité, et le scraper est envoyé en révision.
✨ Améliorations
En plus du maintien de l'opérabilité des scrapers intégrés, à chaque version, de nouvelles fonctions sont ajoutées et diverses améliorations sont apportées, influençant tant la performance que la quantité de données obtenues. La version inclut de nouveaux scrapers, et de nouvelles méthodes sont implémentées dans l'API JavaScript.
Vous pouvez consulter tous les changements ici.
Problèmes liés à l'absence de mises à jour
L'absence de mises à jour opportunes provoque un fonctionnement incorrect des scrapers intégrés. Les raisons peuvent être diverses. Par exemple, la mise en page des pages a pu changer. Le scraper n'ayant pas reçu de mise à jour tente de collecter des données avec d'anciennes expressions régulières non adaptées au nouveau format. En conséquence, des requêtes échouées apparaissent, diverses erreurs surgissent et le résultat est absent.
Exemple avec le scraper Google
Un utilisateur a contacté le support avec le problème suivant :
Je collecte les résultats de Google avec vos proxies. J'ai configuré 300 tentatives par requête. Toutes les requêtes échouent. Hier encore, tout fonctionnait.
À première vue, il semble que le problème vienne des proxies, mais les tests avec des paramètres et des requêtes identiques sur la dernière version réussissent. Le problème est donc ailleurs. Au cours du dialogue, il s'avère que l'utilisateur possède une version obsolète de A-Parser. C'est la véritable cause du fonctionnement incorrect du scraper Google.
Exemple avec le scraper Yandex
Sur Yandex, la mise en page des pages avec captcha a changé, ce qui a empêché sa résolution. Sur le forum, dans la section Tâches, un sujet correspondant a été créé.
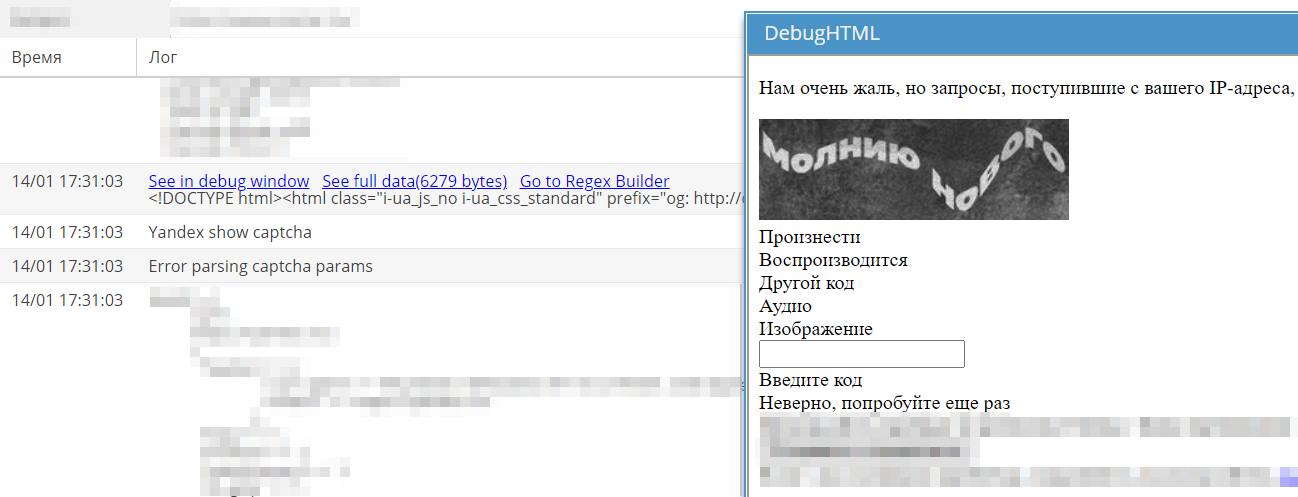
Le lendemain matin, un correctif a été publié. La tâche a été clôturée et déplacée vers la section Next release. On y trouve les sujets de toutes les corrections et améliorations qui seront incluses dans la prochaine version stable.
Par conséquent, dans un A-Parser n'ayant pas reçu la dernière mise à jour, le captcha sur Yandex ne se résolvait plus.
Conclusion
En achetant A-Parser, vous obtenez une licence d'utilisation perpétuelle du programme et un pack de mises à jour gratuites pour une période déterminée. Si nécessaire, à l'expiration de l'abonnement, vous pouvez le renouveler en achetant l'un des packs de mises à jour proposés.
Les sites sont instables – les scrapers nécessitent des ajustements et des améliorations constants. Maintenir leur état de fonctionnement est notre métier. C'est une tâche prioritaire dans laquelle nous investissons beaucoup d'efforts pour publier des correctifs fonctionnels le plus rapidement possible. Le coût des mises à jour justifie le travail qui se cache derrière. Chaque version n'est pas seulement une liste de corrections et d'améliorations – ce sont des mois de travail concentré de l'équipe A-Parser.