Paramètres
A-Parser contient les groupes de paramètres suivants :
- Global Settings - paramètres principaux du programme : langue, mot de passe, paramètres de mise à jour, nombre de tâches actives
- Config Presets - paramètres des threads et méthodes de déduplication pour les tâches
- Parser Presets - possibilité de configurer chaque scraper individuellement
- Paramètres de vérification des proxys - nombre de threads et tous les paramètres pour le proxychecker
- Advanced Settings - paramètres optionnels pour les utilisateurs avancés
- Task presets - sauvegarde des tâches pour une utilisation ultérieure
Tous les paramètres (sauf les paramètres généraux et supplémentaires) sont enregistrés dans des présélections - des ensembles de paramètres pré-enregistrés, par exemple :
- Différents préréglages de paramètres pour le scraper
 SE::Google - l'un pour la collecte de liens avec une profondeur maximale de 10 pages, l'autre pour l'évaluation de la concurrence par requête, avec une profondeur de collecte de 1 page
SE::Google - l'un pour la collecte de liens avec une profondeur maximale de 10 pages, l'autre pour l'évaluation de la concurrence par requête, avec une profondeur de collecte de 1 page - Différentes présélections de paramètres du proxychecker - distincts pour les proxys HTTP et SOCKS
Pour tous les paramètres, il existe une présélection par défaut (default), il ne peut pas être modifié, tous les changements doivent être enregistrés dans des présélections avec de nouveaux noms.
Paramètres généraux
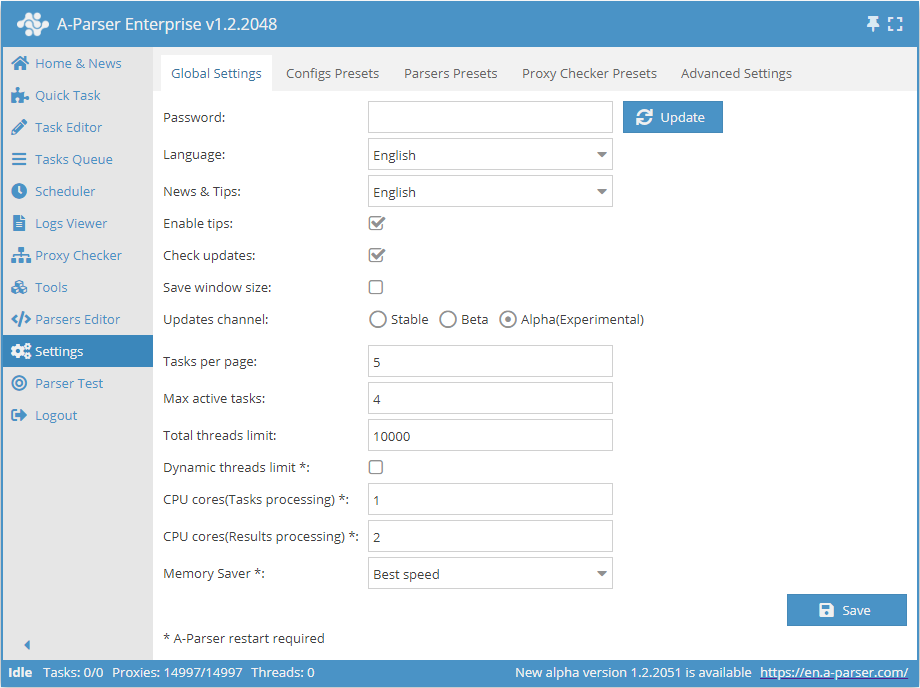
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Password | Pas de mot de passe | Définir un mot de passe pour accéder à A-Parser |
| Language | English | Langue de l'interface |
| News & Tips | English | Langue des actualités et des astuces |
| Enable tips | ☑ | Détermine s'il faut afficher les astuces |
| Check updates | ☑ | Détermine s'il faut afficher les informations sur la disponibilité d'une nouvelle mise à jour dans la Barre d'état |
| Save window size | ☐ | Détermine s'il faut enregistrer la taille de la fenêtre |
| Updates channel | Stable | Choix du canal de mise à jour (Stable, Bêta, Alpha) |
| Tasks per page | 5 | Nombre de tâches par page dans la File des tâches |
| Max active tasks | 1 | Nombre maximum de tâches actives |
| Total threads limit | 10000 | Limite globale de threads dans A-Parser. La tâche ne démarrera pas si la limite globale de threads est inférieure au nombre de threads de la tâche |
| Dynamic thread limit | ☐ | Détermine s'il faut utiliser la Limite dynamique de threads |
| CPU cores (task processing) | 2 | Support du traitement des tâches sur différents cœurs de processeur (uniquement pour la licence Enterprise). Décrit plus en détail ci-dessous |
| CPU cores (result processing) | 4 | Plusieurs cœurs sont utilisés uniquement lors du filtrage, du Constructeur de résultats, et de Parse custom result (tous types de licences) |
| Memory Saver | Best speed | Permet de déterminer la quantité de mémoire que le scraper peut utiliser (Best speed / Medium memory usage / Save max memory). En savoir plus... |
Cœurs CPU (traitement des tâches)
Support du traitement des tâches sur différents cœurs de processeur, cette fonctionnalité est disponible uniquement pour la licence Enterprise
Cette option accélère (considérablement) le traitement de plusieurs tâches dans la file d'attente (Settings -> Max active tasks), mais n'accélère en rien l'exécution d'une seule tâche
Une distribution intelligente des tâches sur les cœurs de travail basée sur la charge CPU de chaque processus est également implémentée Le nombre de cœurs de processeur utilisés est défini dans les paramètres, par défaut - 2, maximum - 32
Comme pour les threads, il est préférable d'aborder le choix du nombre de cœurs de manière expérimentale, des valeurs raisonnables seraient 2-3 cœurs pour des processeurs 4 cœurs, 4-6 pour des processeurs huit cœurs, etc. Il faut tenir compte du fait qu'avec un grand nombre de cœurs et une charge élevée, une charge de 100% du processus de contrôle principal (aparser/aparser.exe) peut survenir, ce qui rendrait toute augmentation supplémentaire des processus de traitement des tâches contre-productive ou instable. Il faut également noter que chaque processus de traitement de tâches peut créer une charge supplémentaire allant jusqu'à 300% (c'est-à-dire charger 100% de 3 cœurs simultanément), cette particularité est liée au traitement multithread du garbage collector dans le moteur JavaScript v8
Paramètres des threads
Le fonctionnement d'A-Parser est basé sur le principe du traitement multithread des données. Le scraper exécute les tâches en parallèle dans des threads séparés, dont le nombre peut varier de manière flexible en fonction de la configuration du serveur.
Description du fonctionnement des threads
Voyons ce que sont les threads en pratique. Supposons que vous deviez préparer un rapport pour trois mois.
Option 1
Vous pouvez préparer le rapport d'abord pour le 1er mois, puis pour le 2ème, et enfin pour le 3ème. C'est un exemple de travail monothread. Les tâches sont résolues l'une après l'autre.
Option 2
Embaucher trois comptables qui prépareront chacun un rapport pour un mois. Ensuite, après avoir reçu les résultats des trois, faire un rapport global. C'est un exemple de traitement multithread. Les tâches sont résolues simultanément.
Comme on le voit dans ces exemples, le traitement multithread permet d'exécuter la tâche plus rapidement, mais nécessite en même temps plus de ressources (nous avons besoin de 3 comptables au lieu d'un seul). Le traitement multithread fonctionne de la même manière dans A-Parser. Supposons que vous deviez collecter des données à partir de plusieurs liens :
- avec un seul thread, l'application traitera chaque site l'un après l'autre
- en travaillant avec plusieurs threads, chacun traitera son propre lien, et une fois terminé, passera au suivant non traité dans la liste
Ainsi, dans la deuxième option, toute la tâche sera accomplie beaucoup plus rapidement, mais cela nécessite plus de ressources serveur, il est donc recommandé de respecter les Configuration requise
Configuration des threads
La configuration des threads dans A-Parser s'effectue séparément pour chaque tâche, en fonction des paramètres requis pour son exécution. Par défaut, 2 configurations de threads sont disponibles : pour 20 et 100 threads, pour default et 100 Threads respectivement.
Pour accéder aux paramètres de la configuration choisie, vous devez cliquer sur l'icône du crayon ![]() , après quoi ses paramètres s'ouvriront.
, après quoi ses paramètres s'ouvriront. 
Il est également possible d'accéder aux paramètres des threads via le menu : Settings -> Config Presets
Ici, nous pouvons :
- créer une nouvelle configuration avec ses propres paramètres et l'enregistrer sous son propre nom (bouton Ajouter nouveau)
- apporter des modifications à une configuration existante en la sélectionnant dans la liste déroulante (bouton Enregistrer)
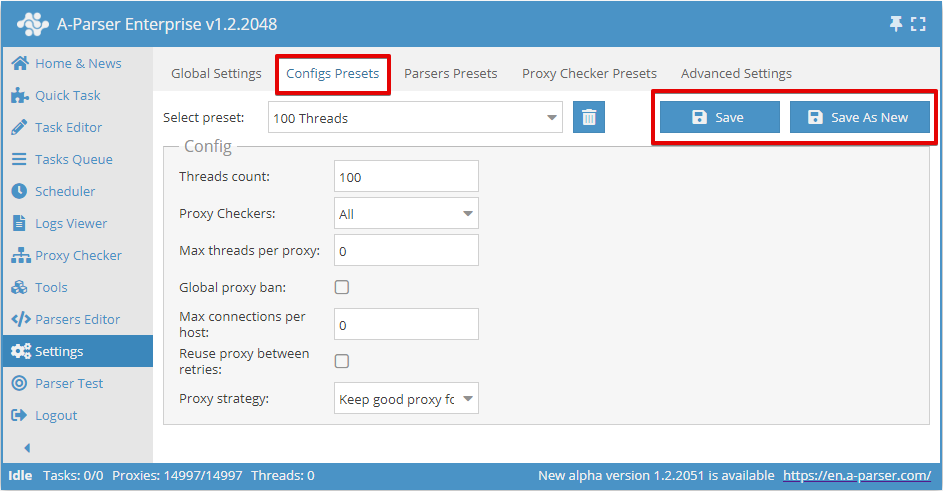
Nombre de threads (Threads count)
Ce paramètre définit le nombre de threads dans lesquels la tâche lancée avec cette configuration fonctionnera. Le nombre de threads peut être n'importe lequel, mais il faut tenir compte des capacités de votre serveur, ainsi que de la limite du forfait proxy, si une telle limite est prévue. Par exemple, pour nos proxies, vous pouvez indiquer un nombre ne dépassant pas le forfait choisi.
Il est également important de se rappeler que le nombre total de threads dans le scraper est égal à la somme des tâches en cours et des testeurs de proxy activés avec vérification de proxy. Par exemple, si une tâche à 20 threads et deux tâches à 100 threads chacune sont lancées, et qu'un testeur de proxy fonctionne avec une vérification de proxy en 15 threads, alors au total le scraper utilisera 20+100+100+15=235 threads. Dans ce cas, si le forfait proxy est prévu pour 200 threads, il y aura de nombreuses requêtes échouées. Pour les éviter, il faut réduire le nombre de threads utilisés. Par exemple, désactiver la vérification de proxy (si elle n'est pas nécessaire, cela économisera 15 threads) et réduire le nombre de threads dans l'une des tâches de 20 threads supplémentaires. Ainsi, pour l'une des tâches en cours, il faut créer une configuration à 80 threads, et laisser les autres telles quelles
Testeurs de proxy (Proxy Checkers)
Ce paramètre permet de choisir un testeur de proxy avec des paramètres spécifiques. Ici, vous pouvez sélectionner le paramètre All, qui signifie l'utilisation de tous les testeurs de proxy actifs, ou seulement ceux qui doivent être utilisés dans la tâche (plusieurs positions peuvent être sélectionnées)
Ce paramètre permet de lancer la tâche uniquement avec les testeurs de proxy nécessaires. Le processus de configuration du testeur de proxy est examiné ici
Maximum de threads par proxy (Max threads per proxy)
Ici est défini le nombre maximum de threads sur lesquels un même proxy sera utilisé simultanément. Permet de définir différents paramètres, par exemple un fonctionnement 1 thread = 1 proxy.
Par défaut, ce paramètre est égal à 0, ce qui désactive cette fonction. Dans la plupart des cas, cela suffit. Mais s'il est nécessaire de limiter la charge sur chaque proxy, il est alors logique de changer la valeur
Bannissement global de proxy (Global proxy ban)
Toutes les tâches lancées avec cette option partagent une base commune de bannissement de proxy. La particularité de ce paramètre est que la liste des proxies bannis pour chaque scraper est commune à toutes les tâches en cours.
Par exemple, un proxy banni dans SE::Google dans la tâche 1 sera également banni pour SE::Google dans la tâche 2, mais il pourra fonctionner librement dans  SE::Yandex dans les deux tâches
SE::Yandex dans les deux tâches
Maximum de connexions par hôte (Max connections per host)
Ce paramètre indique le nombre maximum de connexions par hôte, destiné à réduire la charge sur le site lors de la collecte de données. En substance, l'indication de ce paramètre permet de contrôler le nombre de requêtes à un instant donné pour chaque domaine spécifique. L'activation de ce paramètre s'applique à la tâche ; si vous lancez plusieurs tâches simultanément avec la même configuration de threads, la limite sera calculée pour toutes les tâches.
Par défaut, ce paramètre a la valeur 0, c'est-à-dire qu'il est désactivé.
Réutilisation du proxy entre les tentatives (Reuse proxy between retries)
Ce paramètre désactive la vérification de l'unicité du proxy pour chaque tentative, et le bannissement du proxy ne fonctionnera pas non plus. Cela signifie en retour la possibilité d'utiliser 1 proxy pour toutes les tentatives.
Il est recommandé d'activer ce paramètre, par exemple, dans les cas où il est prévu d'utiliser 1 proxy dont l'IP de sortie change à chaque connexion.
Stratégie de proxy (Proxy strategy)
Permet de gérer la stratégie de sélection du proxy lors de l'utilisation de sessions : conserver le proxy d'une requête réussie pour la requête suivante ou toujours utiliser un proxy aléatoire.
Recommandations
Cet article a examiné tous les paramètres permettant de gérer les threads. Il convient de noter que lors de la configuration des threads, il n'est pas nécessaire de définir tous les paramètres indiqués dans l'article, il suffit de définir uniquement ceux qui assureront l'obtention d'un résultat correct. Généralement, il suffit de changer uniquement le Threads count, les autres paramètres peuvent être laissés par défaut.
Paramètres des scrapers
Chaque scraper possède de nombreux paramètres et permet d'enregistrer différents ensembles de paramètres dans des préréglages. Le système de préréglages permet d'utiliser le même scraper avec différents paramètres selon la situation, analysons l'exemple du scraper SE::Google :
Préréglage 1 : "Collecte du nombre maximum de liens"
- Nombre de pages (Pages count) :
10
Ainsi, le scraper collectera le nombre maximum de liens en parcourant toutes les pages des résultats de recherche
Préréglage 2 : "Collecte de la concurrence par requête"
- Nombre de pages (Pages count) :
1 - Format du résultat (Results format) :
$query: $totalcount\n
Dans ce cas, nous obtenons le nombre de résultats de la recherche par requête (concurrence de la requête) et pour une plus grande vitesse, il nous suffit de scraper uniquement la première page avec un nombre minimal de liens
Création de préréglages
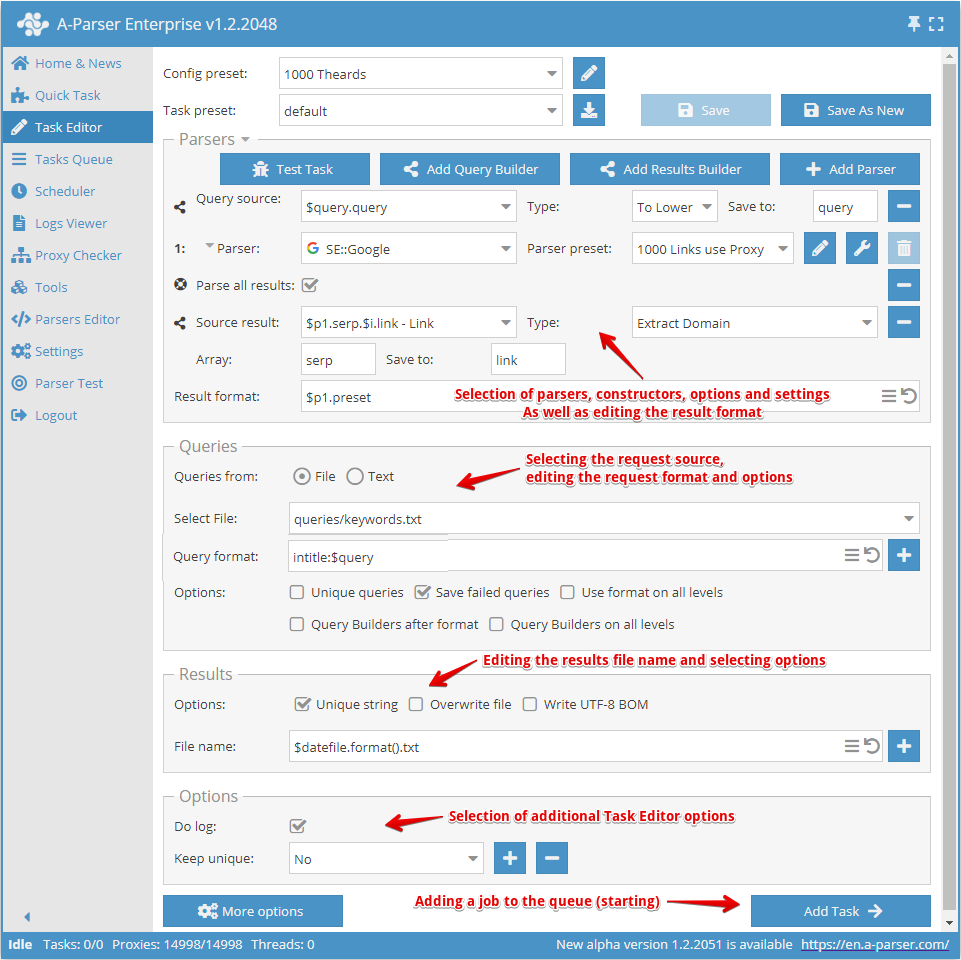
La création d'un préréglage commence par le choix du ou des scrapers et la définition du résultat à obtenir.
Ensuite, il faut comprendre quelles seront les données d'entrée pour le scraper choisi ; sur la capture d'écran ci-dessus, le scraper SE::Google est sélectionné, ses données d'entrée sont n'importe quelles chaînes de caractères comme si vous cherchiez quelque chose dans un navigateur. Vous pouvez choisir un fichier de requêtes ou saisir les requêtes dans un champ de texte.
Maintenant, il faut redéfinir les paramètres (choisir les options) pour le scraper, ajouter la déduplication. Vous pouvez utiliser le constructeur de requêtes s'il est nécessaire de traiter les requêtes. Ou utiliser le constructeur de résultats s'il est nécessaire de traiter les résultats d'une manière ou d'une autre.
Ensuite, il faut prêter attention à l'édition du nom du fichier de résultats, et le modifier à votre convenance si nécessaire.
Le dernier point est le choix des options supplémentaires, en particulier l'option Do log (Enable log) (Tenir un log). Très utile si vous voulez connaître la raison d'une erreur de collecte de données.
Après tout cela, il faut enregistrer le préréglage et l'ajouter à la file des tâches.
Redéfinition des paramètres
Override preset - redéfinition rapide des paramètres pour le scraper, cette option peut être ajoutée directement dans l'Éditeur de tâches. En un clic, vous pouvez ajouter plusieurs paramètres. Dans la liste des paramètres, les valeurs par défaut sont indiquées, et si l'option est en gras, cela signifie qu'elle est déjà redéfinie dans le préréglage
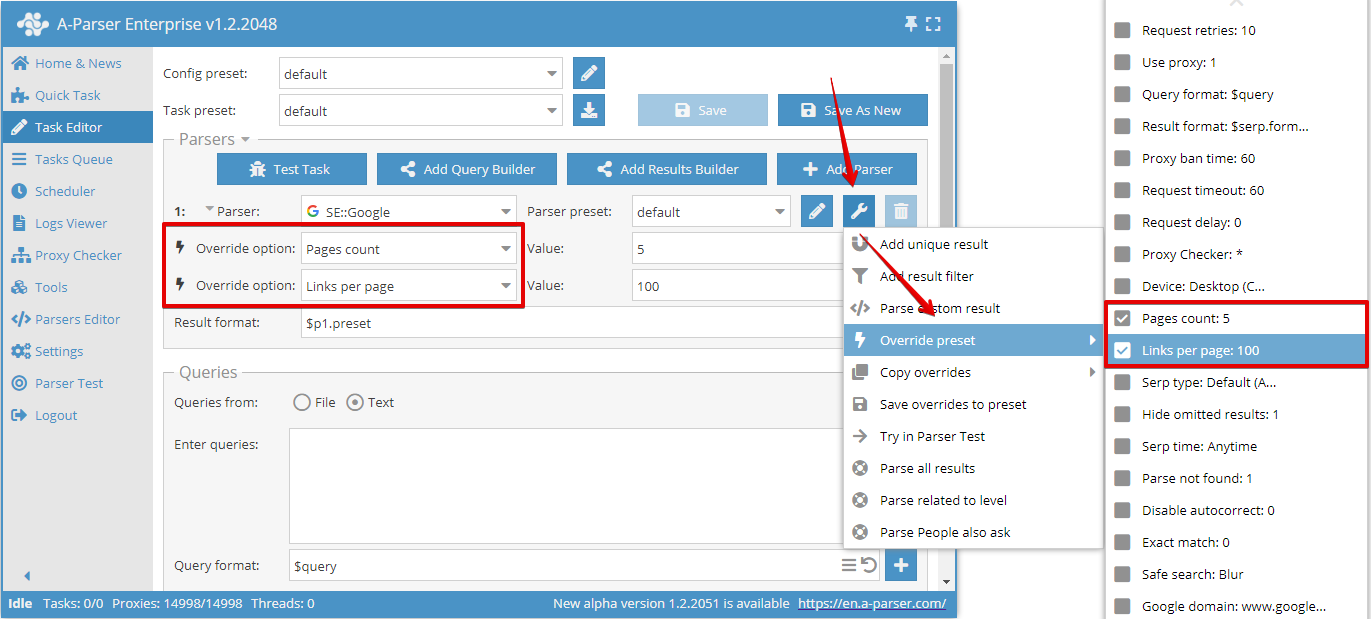
Dans cet exemple, l'option Pages count (Nombre de pages) est redéfinie : elle a été réglée sur 5.
Dans une tâche, vous pouvez utiliser un nombre illimité d'options Override preset, mais si les modifications sont nombreuses, il est plus pratique de créer un nouveau préréglage et d'y enregistrer toutes les modifications.
Il est également facile d'enregistrer les redéfinitions à l'aide de la fonction Save overrides to preset (Enregistrer les redéfinitions). Elles seront enregistrées comme un préréglage distinct pour le scraper sélectionné.
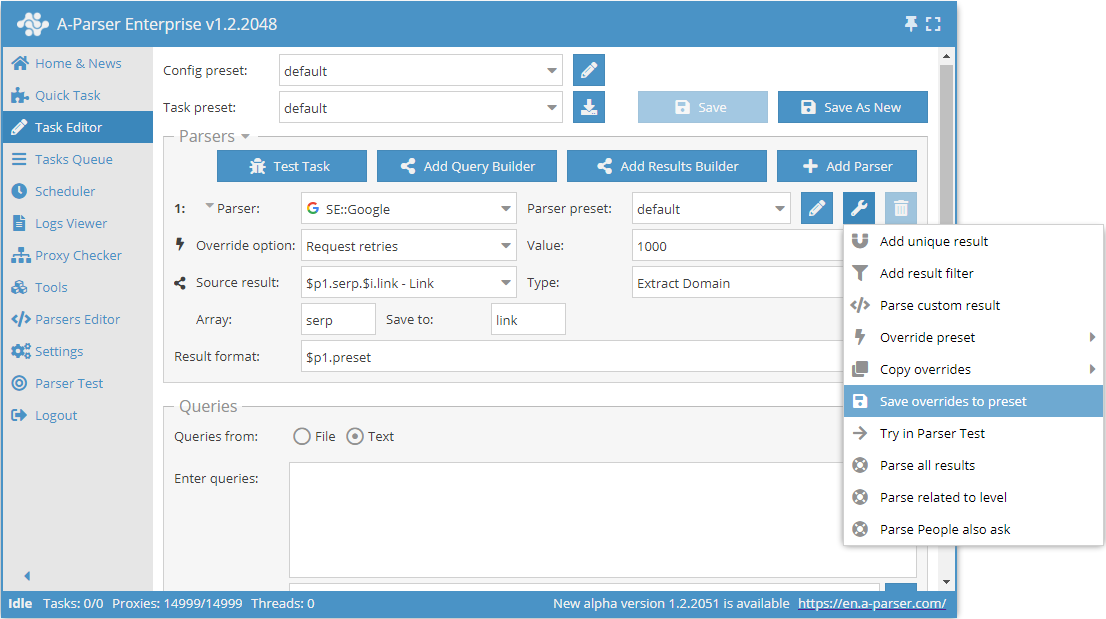
Après quoi, à l'avenir, il suffira de choisir ce préréglage enregistré dans la liste et de l'utiliser.
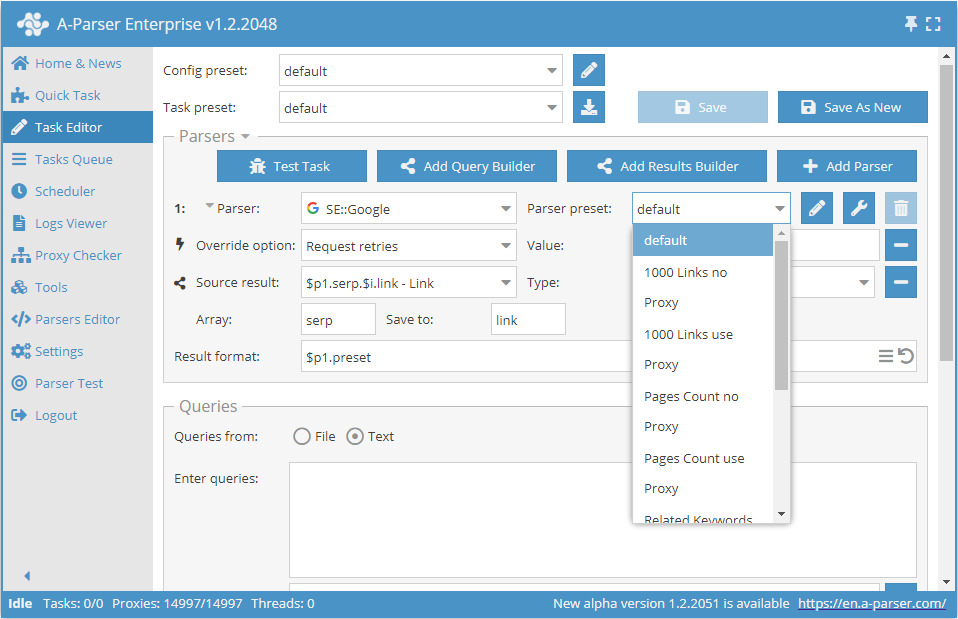
Paramètres communs à tous les scrapers
Chaque scraper possède son propre ensemble de paramètres, vous pouvez trouver des informations sur les paramètres de chaque scraper dans la section correspondante
Dans ce tableau, nous avons présenté les paramètres communs à tous les scrapers
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Request retries | 10 | Nombre de tentatives pour chaque requête ; si la requête ne peut pas être effectuée dans le nombre de tentatives spécifié, elle est considérée comme échouée et ignorée |
| Use proxy | ☑ | Détermine s'il faut utiliser des proxys |
| Query format | $query | Format de la requête |
| Result format | Chaque scraper a sa propre valeur | Format de sortie du résultat |
| Proxy ban time | Chaque scraper a sa propre valeur | Temps de bannissement du proxy en secondes |
| Request timeout | 60 | Temps d'attente maximum de la requête en secondes |
| Request delay | 0 | Délai entre les requêtes en secondes, une valeur aléatoire peut être définie dans une plage, par exemple 10,30 - délai de 10 à 30 secondes |
| Proxy Checker | All | Proxys de quels checkers doivent être utilisés (choix entre tous ou énumération de spécifiques) |
Communs à tous les scrapers fonctionnant via le protocole HTTP
| Nom du paramètre | Valeur par défaut | Description |
|---|---|---|
| Max body size | Chaque scraper a sa propre valeur | Taille maximale de la page de résultats en octets |
| Use gzip | ☑ | Détermine s'il faut utiliser la compression du trafic transmis |
| Extra query string | Permet de spécifier des paramètres supplémentaires dans la chaîne de requête |
Les paramètres par défaut pour chaque scraper peuvent différer. Ils sont stockés dans le préréglage default dans les paramètres de chaque scraper.
Paramètres des testeurs de proxy
En savoir plus sur la Configuration des proxycheckers
Paramètres supplémentaires
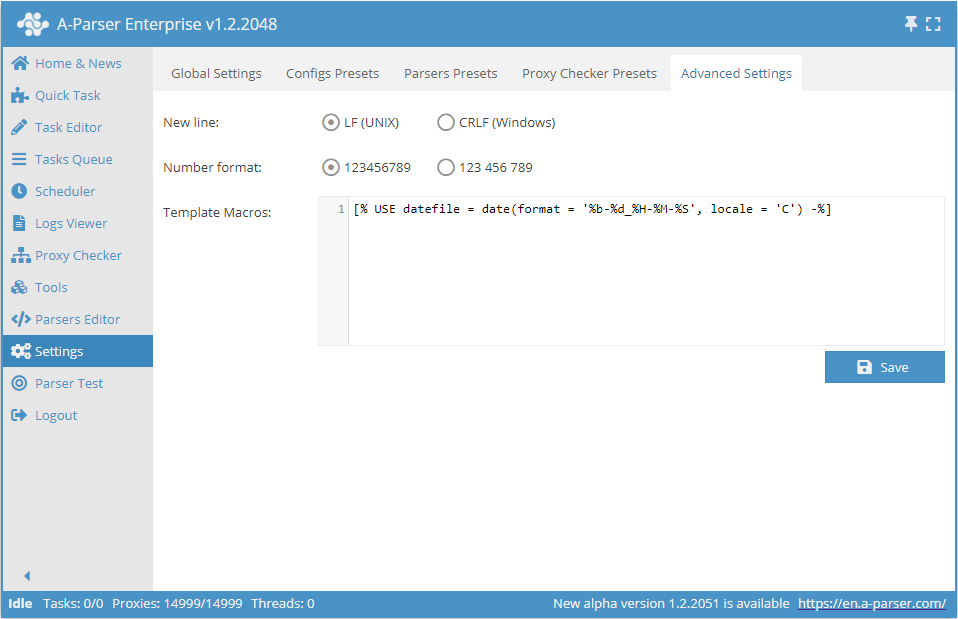
- Le saut de ligne permet de choisir entre l'option Unix et Windows pour la fin des lignes lors de l'enregistrement des résultats dans un fichier
- Format des nombres - définit comment afficher les nombres dans l'interface d'A-Parser
- Macros de templates