Scrapers en JavaScript : Aperçu des fonctionnalités
Les scrapers JavaScript offrent la possibilité de créer vos propres scrapers complets avec une logique arbitrairement complexe en utilisant le langage JavaScript. De plus, les scrapers JS permettent d'utiliser toutes les fonctionnalités des scrapers standards.
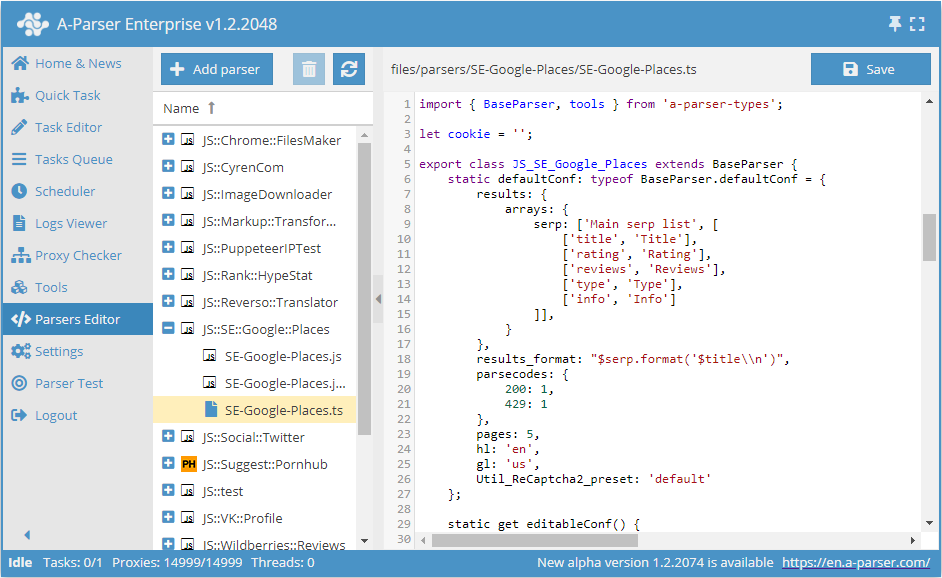
Caractéristiques
En utilisant toute la puissance d'A-Parser, il est désormais possible d'écrire son propre scraper/reger/poster avec une logique aussi complexe que souhaitée. Pour l'écriture du code, JavaScript avec les fonctionnalités ES6 (moteur v8) est utilisé.
Le code des scrapers est aussi concis que possible, permettant de se concentrer sur l'écriture de la logique ; A-Parser prend en charge le travail avec le multithreading, le réseau, les proxys, les résultats, les logs, etc. Le code peut être écrit directement dans l'interface du scraper en ajoutant un nouveau scraper dans l'Éditeur de scrapers. Il est également possible d'utiliser des éditeurs tiers, comme VSCode, pour écrire les scrapers.
Le versionnage automatique est utilisé lors de l'enregistrement du code du scraper via l'éditeur intégré.
Le travail avec les scrapers JavaScript est disponible pour les licences Pro et Enterprise
Accès à l'Éditeur de scrapers JS
Si A-Parser est utilisé à distance, l'Éditeur de scrapers JS n'est pas accessible par défaut pour des raisons de sécurité. Pour y autoriser l'accès, il est nécessaire de :
- Définir un mot de passe dans l'onglet Settings (Paramètres) -> Global Settings (Paramètres généraux)
- Ajouter la ligne suivante dans config/config.txt :
allow_javascript_editor: 1 - Redémarrer A-Parser
Instructions de travail
Dans l'Éditeur de scrapers, créez un nouveau scraper et définissez son nom. Par défaut, un exemple simple sera chargé, à partir duquel vous pourrez rapidement commencer à créer votre propre scraper.
Si un éditeur tiers est utilisé pour écrire le code, vous devez ouvrir le fichier du scraper en cours d'édition dans le dossier /parsers/. Structure des fichiers du programme installé.
Une fois le code prêt, enregistrez-le et utilisez-le comme un scraper ordinaire : dans l'Éditeur de tâches, sélectionnez le scraper créé, et si nécessaire, définissez les paramètres requis, la configuration des threads, le nom du fichier, etc.
Le scraper créé peut être édité à tout moment. Tous les changements concernant l'interface apparaîtront après avoir resélectionné le scraper dans la liste ou après avoir redémarré A-Parser ; les changements dans la logique du scraper sont appliqués lors du relancement d'une tâche avec ce scraper.
Pour chaque scraper créé, une icône standard est affichée par défaut. Vous pouvez ajouter la vôtre au format png ou ico en la plaçant dans le dossier du scraper dans /parsers/ :

Principes généraux de fonctionnement
Par défaut, un exemple de scraper simple est créé, prêt pour une édition ultérieure.
- TypeScript
- JavaScript
import { BaseParser } from 'a-parser-types';
export class JS_v2_example extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'HTML title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: '$query: $title\\n',
};
static editableConf: typeof BaseParser.editableConf = [];
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
let response = await this.request('GET', set.query, {}, {
check_content: ['<\/html>'],
decode: 'auto-html',
});
if (response.success) {
let matches = response.data.match(/<title>(.*?)<\/title>/i);
if (matches)
results.title = matches[1];
}
results.success = response.success;
return results;
}
}
const { BaseParser } = require("a-parser-types");
class JS_v2_example_js extends BaseParser {
static defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'HTML title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: '$query: $title\\n',
};
static editableConf = [];
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
let response = await this.request('GET', set.query, {}, {
check_content: ['<\/html>'],
decode: 'auto-html',
});
if (response.success) {
let matches = response.data.match(/<title>(.*?)<\/title>/i);
if (matches)
results.title = matches[1];
}
results.success = response.success;
return results;
}
}
Le constructeur est appelé une seule fois pour chaque tâche. Il est impératif de définir this.defaultConf.results et this.defaultConf.results_format, les autres champs sont facultatifs et prendront des valeurs par défaut.
Le tableau this.editableConf définit quels paramètres peuvent être modifiés par l'utilisateur depuis l'interface d'A-Parser. Les types de champs suivants peuvent être utilisés :
combobox- menu déroulant de sélection. Il est également possible de créer un menu de sélection de préréglage d'un scraper standard, par exemple :
['Util_AntiGate_preset', ['combobox', 'AntiGate preset']]
comboboxavec possibilité de sélection multiple. Il faut définir en plus le paramètre{'multiSelect': 1}:
['proxyCheckers', ['combobox', 'Proxy Checkers', {'multiSelect': 1}, ['*', 'All']]]
checkbox- case à cocher, pour les paramètres ne pouvant avoir que 2 valeurs (true/false)textfield- champ de textetextarea- champ de texte avec saisie multiligne
La méthode parse est une fonction asynchrone et doit retourner await pour toute opération bloquante (c'est la principale et unique différence par rapport à une fonction classique). La méthode est appelée pour chaque requête entrée en traitement. set (un hash avec la requête et ses paramètres) et results (un modèle vide pour les résultats) sont obligatoirement transmis. Il est également impératif de retourner le results rempli, après avoir préalablement défini le flag success.
Versionnage automatique
La version a le format Major.Minor.Revision
- TypeScript
- JavaScript
this.defaultConf: typeof BaseParser.defaultConf = {
version: '0.1.1',
...
}
this.defaultConf = {
version: '0.1.1',
...
}
La valeur Revision (le dernier chiffre) est automatiquement incrémentée à chaque enregistrement. Les autres valeurs (Major, Minor) peuvent être modifiées manuellement, et la Revision peut être réinitialisée à 0.
Si, pour une raison quelconque, il est nécessaire de modifier la Revision uniquement manuellement, la version doit être entourée de doubles guillemets ""
Traitement par lots des requêtes
Dans certains cas, il peut être nécessaire de prendre plusieurs requêtes à la fois dans la file d'attente et de les traiter en une seule fois. Ce mode est utilisé par les scrapers intégrés lorsqu'il est nécessaire de demander des données pour plusieurs clés (par lot) en un seul passage.
Pour implémenter cette même fonctionnalité dans un scraper JS, vous devez définir la valeur bulkQueries: N dans this.defaultConf, où N est le nombre requis de requêtes dans le lot. Dans ce cas, le scraper prendra les requêtes par lots de N unités et toutes les requêtes de l'itération actuelle seront contenues dans le tableau set.bulkQueries (incluant toutes les variables standards : query.first, query.orig, query.prev, etc.). Voici un exemple d'un tel tableau :
[
{
"first": "test",
"prev": "",
"lvl": 0,
"num": 0,
"query": "test",
"queryUid": "6eb301",
"orig": "test"
},
{
"first": "vérification",
"prev": "",
"lvl": 0,
"num": 1,
"query": "vérification",
"queryUid": "774563",
"orig": "vérification"
},
{
"first": "third query",
"prev": "",
"lvl": 0,
"num": 2,
"query": "third query",
"queryUid": "2bc8ed",
"orig": "third query"
}
]
Les résultats lors du traitement par lots doivent être remplis dans le tableau results.bulkResults, où chaque élément est un objet results. Les éléments dans results.bulkResults sont disposés dans le même ordre que celui de set.bulkQueries.
Liens utiles
📄️ Exemple bulkQueries
Exemple d'utilisation de bulkQueries avec l'appel d'un scraper intégré
🔗 Exemples et discussion
Sujet sur le forum avec des exemples et une discussion sur les fonctionnalités des scrapers JS
🔗 Catalogue de scrapers JS
Section du catalogue de ressources dédiée aux scrapers JS
🔗 Aperçu des fonctionnalités de base d'ES6
Article sur habrahabr consacré à l'aperçu des fonctionnalités de base d'ES6