Foire aux questions
1. Questions liées à la démo, au paiement et à l'achat
1.1. Comment télécharger les résultats dans la version Demo ?
Dans la version Demo, les résultats ne sont pas disponibles au téléchargement. Nous les fournissons sur demande. Envoyez-nous vos requêtes et précisez quel scraper vous intéresse, et nous vous enverrons les résultats (leur nombre est limité dans le cadre de la démo).
1.2. Faut-il payer un supplément après l'achat d'A-Parser ?
Non. Plus de détails : licences et compléments, page d'achat.
1.3. Où et comment payer les proxys ?
Lors de l'achat d'une licence, des proxys bonus vous sont fournis.
Lite - 20 threads pendant 2 semaines, Pro et Enterprise - 50 threads pendant un mois.
Vous pouvez acheter plus de threads ou prolonger votre abonnement dans l' Espace Membres sous l'onglet Boutique, sous-section Proxy.
1.4. Pourriez-vous me configurer une tâche contre rémunération ?
Le support technique pour les questions liées au fonctionnement d'A-Parser est gratuit. Pour une aide payante dans la configuration des tâches, vous pouvez vous adresser ici : Services payants de configuration de tâches, aide au paramétrage et formation à l'utilisation d'A-Parser.
1.5. Puis-je payer le scraper via la banque Privat24 ? Via KIWI ?
La liste des systèmes de paiement avec lesquels nous travaillons est indiquée ici : acheter A-Parser.
1.6. Si je veux seulement collecter le nombre de pages indexées dans Yandex, quel scraper devrais-je acheter ?
Pour de tels objectifs, la version Lite est suffisante, mais la version Pro est plus pratique et flexible à l'usage.
1.7. Où consulter les informations sur ma licence ?
1.8. Est-il possible d'utiliser les proxys achetés depuis plusieurs IP ?
Non.
2. Questions sur l'installation, le lancement et les mises à jour
2.1. Je clique sur le bouton Download mais l'archive ne se télécharge pas. Que faire ?
Vérifiez si vous avez de l'espace libre sur votre disque dur, désactivez l'antivirus. Suivez les instructions d'installation. Consultez également Comment commencer à travailler.
2.2. J'ai acheté la version Enterprise, mais c'est toujours la PRO qui s'installe. Que faire ?
Supprimez la version précédente. Dans l'Espace Membres, vérifiez si votre adresse IP est correctement renseignée. Avant le téléchargement, cliquez sur le bouton Update (Mettre à jour). Téléchargez la version la plus récente. Plus de détails dans les instructions d'installation.
2.3. J'ai installé le programme mais il ne se lance pas, que faire ?
Vérifiez les applications en cours d'exécution, désactivez l'antivirus, vérifiez la quantité de mémoire vive disponible. Vérifiez également dans l' Espace Membres si votre adresse IP est correctement renseignée. Plus de détails : instructions d'installation.
2.4. Que faire si j'ai une adresse IP dynamique ?
Ce n'est pas un problème, A-Parser supporte le travail avec des adresses IP dynamiques. Il vous suffit de la mettre à jour dans l'Espace Membres à chaque changement. Pour éviter ces manipulations, il est recommandé d'utiliser une adresse IP statique.
2.5. Quels sont les paramètres optimaux du serveur ou de l'ordinateur pour installer le scraper ?
Toutes les exigences système peuvent être consultées ici : exigences système.
2.6. J'ai lancé une tâche. Le scraper a planté et ne se relance plus, que faire ?
Il est nécessaire d'arrêter le serveur, de vérifier si le processus ne reste pas en mémoire et d'essayer de le relancer. Vous pouvez également essayer de lancer A-Parser avec l'arrêt de toutes les tâches. Pour cela, lancez-le avec le paramètre -stoptasks. Détails sur le lancement avec paramètre.
2.7. Quel mot de passe saisir lors de l'ouverture de l'adresse 127.0.0.1:9091 ?
S'il s'agit du premier lancement, le mot de passe est vide. Sinon, c'est celui que vous avez défini. Si vous avez oublié votre mot de passe - réinitialisation du mot de passe.
2.8. Dans l'Espace Membres, je saisis mon IP mais elle ne change pas dans le champ Votre IP actuelle. Pourquoi ?
Le champ Your current IP (Votre IP actuelle) affiche l'IP qui est actuellement valide pour vous, et il ne doit pas changer. C'est cette adresse que vous devez saisir dans le champ IP 1.
2.9. Puis-je lancer deux copies simultanément ?
Lancer deux copies sur une même machine n'est possible que si un port différent est spécifié dans le fichier de configuration.
Lancer deux instances d'A-Parser sur des machines différentes simultanément n'est possible que si vous avez acheté une IP supplémentaire dans l' Espace Membres.
2.10. Le scraper est-il lié au matériel ?
Non. Votre IP est utilisée pour le contrôle des licences.
2.11. Question sur la mise à jour - faut-il mettre à jour uniquement le .exe ? config/config.db et files/Rank-CMS/apps.json - à quoi servent ces fichiers ?
Sauf indication contraire, ne mettre à jour que le .exe. Le premier fichier sert à stocker la configuration d'A-Parser, et le second est la base pour la détection des CMS et le fonctionnement même du scraper ![]() Rank::CMS.
Rank::CMS.
2.12. J'ai Win Server 2008 Web Edition - le scraper ne se lance pas...
A-Parser ne fonctionnera pas sur cette version de l'OS. La seule option est de changer d'OS.
2.13. J'ai un processeur 4 cœurs. Pourquoi A-Parser n'utilise-t-il qu'un seul cœur ?
A-Parser utilise de 2 à 4 cœurs, les cœurs supplémentaires ne sont utilisés que lors du filtrage, dans le Constructeur de résultats ou le Parse custom result.
2.14. Une erreur de segmentation a commencé à apparaître (segmentation failed, segmentation error). Que faire ?
Il est fort probable que votre IP ait changé. Vérifiez dans l' Espace Membres.
2.15. Je suis sous Linux. A-Parser s'est lancé mais ne s'ouvre pas dans le navigateur. Comment résoudre cela ?
Vérifiez le pare-feu - il bloque probablement l'accès.
2.16. Je suis sous Windows 7. A-Parser s'est lancé mais ne s'ouvre pas dans le navigateur et il n'y a pas de processus Node.js dans le gestionnaire de tâches. Comment résoudre cela ?
Vous devez vérifier les mises à jour Windows et installer les dernières disponibles. Plus précisément, vous avez besoin de la mise à jour Windows 7 SP1.
2.17. A-Parser ne se lance pas et une erreur FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20 s'affiche dans aparser.log.
Un problème survient probablement avec une tâche (dossier /config/tasks/), suite à une erreur de disque (par exemple si le PC a été éteint sans arrêt correct), plus de détails peuvent être obtenus en lançant A-Parser avec le flag -morelogs
Solution : lancez A-Parser avec le paramètre -stoptasks. Si cela ne suffit pas, videz tout le dossier /config/tasks/. Si le problème persiste, réinstallez le scraper dans un nouveau répertoire et récupérez la config de l'ancien (si elle n'est pas corrompue).
3. Questions sur la configuration d'A-Parser et autres réglages
3.1. Comment configurer le proxychecker ?
Les instructions détaillées se trouvent ici : configuration du proxy.
3.2. Il n'y a pas de proxys fonctionnels - pourquoi ?
Vérifiez votre connexion internet ainsi que la configuration du proxychecker. Si tout est correct, cela signifie que votre liste de proxys ne contient actuellement aucun serveur fonctionnel. Solution : utilisez d'autres proxys ou réessayez plus tard. Si vous utilisez nos proxys, vérifiez l'adresse IP dans l' Espace Membres dans la section Proxies (Proxy). Il est également possible que votre fournisseur bloque l'accès à d'autres DNS, essayez les étapes décrites ici : http://a-parser.com/threads/1240/#post-3582
3.3. Comment connecter Antigate ?
Les instructions détaillées pour la configuration d'Antigate sont ici.
3.4. J'ai modifié les paramètres dans les réglages du scraper, mais ils n'ont pas été appliqués. Pourquoi ?
Le préréglage par défaut (default) ne peut pas être modifié. Si des changements sont effectués, vous devez cliquer sur Save as New Preset (Enregistrer comme nouveau préréglage) et l'utiliser ensuite dans votre tâche.
3.5. Peut-on modifier les paramètres d'une tâche en cours ?
Oui, mais pas tous. Dans une tâche en cours, vous pouvez cliquer sur pause et choisir Edit (Modifier) dans le menu déroulant.
3.6. Comment importer un préréglage ?
Cliquez sur le bouton à côté du champ de sélection de la tâche dans l' Éditeur de tâches. Détails ici.
3.7. Comment configurer le scraper pour qu'il n'utilise pas de proxy ?
Dans les paramètres du scraper concerné, décochez la case Use proxy.
3.8. Je n'ai pas le bouton Ajouter une redéfinition / Override option !
Cette option peut être ajoutée directement dans l' Éditeur de tâches. Options du scraper.
3.9. Comment réécrire dans le même fichier de résultats ?
Lors de la création de la tâche, activez l'option Overwrite file (Écraser le fichier).
3.10. Où changer le mot de passe du scraper ?
3.11. J'ai mis 6 millions de clés à collecter, et j'ai spécifié que les domaines devaient tous être uniques. Comment faire pour que, lorsque je mettrai 6 nouveaux millions de clés, seuls les domaines uniques ne croisant pas la collecte précédente soient enregistrés ?
Il est nécessaire d'utiliser l'option Keep unique (Conservation de l'état de déduplication) lors de la création de la première tâche, et d'indiquer la base sauvegardée dans la seconde. Détails dans Options supplémentaires de l'éditeur de tâches.
3.12. Comment contourner la limite de 1000 résultats pour Google ?
Utilisez l'option Parser tous les résultats / Parse all results.
3.13. Comment contourner la limite de 1024 threads sur Linux ?
3.14. Quelle est la limite de threads sur Windows ?
Jusqu'à 10 000 threads.
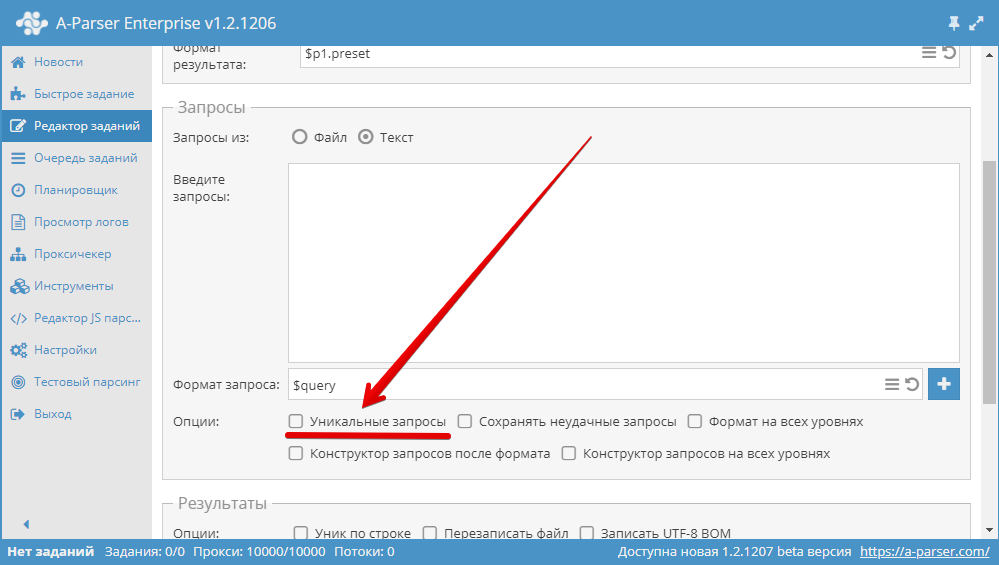
3.15. Comment rendre les requêtes uniques ?
Utilisez l'option Unique queries (Requêtes uniques) dans le bloc Queries (Requêtes) de l' Éditeur de tâches.
3.16. Comment désactiver la vérification des proxys ?
Dans Paramètres - Paramètres du proxychecker, choisissez le proxychecker souhaité et cochez la case No check proxies (Ne pas vérifier les proxys). Enregistrez et sélectionnez le préréglage sauvegardé.
3.17. Qu'est-ce que le Proxy ban time ? Puis-je le mettre à 0 ?
C'est le temps de bannissement du proxy en secondes. Oui, vous pouvez mettre 0.
3.18. Quelle est la différence entre Exact Domain et Top Level Domain dans le scraper  SE::Google::Position
SE::Google::Position
Exact Domain est une correspondance stricte, c'est-à-dire que si le résultat est www.domain.com et que nous cherchons domain.com, il n'y aura pas de correspondance. Top Level Domain compare tout le domaine de premier niveau, donc il y aura une correspondance.
3.19. Si je lance une collecte de test, tout fonctionne, mais si c'est une collecte normale, j'obtiens une erreur Some error.
Le problème vient probablement des DNS, essayez de suivre ces instructions de configuration DNS.
3.20. Où se définit le Format du résultat ?
3.21. Dans  SE::Google, la langue néerlandaise est absente, bien qu'elle soit présente dans les paramètres de Google. Pourquoi ?
SE::Google, la langue néerlandaise est absente, bien qu'elle soit présente dans les paramètres de Google. Pourquoi ?
Le néerlandais est "Dutch", il figure dans la liste. Détails dans l' amélioration sur l'ajout de la langue néerlandaise.
4. Questions sur la collecte de données et les erreurs pendant le processus
4.1. Que sont les threads ?
Tous les processeurs modernes peuvent exécuter des tâches en plusieurs threads, ce qui augmente considérablement la vitesse d'exécution. Pour comparer, on peut citer un bus classique qui transporte un certain nombre de personnes par unité de temps - c'est un traitement monothread classique, et un bus à impériale qui transporte deux fois plus de personnes dans le même temps - c'est un traitement multithread. A-Parser peut traiter simultanément jusqu'à 10 000 threads.
4.2. La tâche ne se lance pas - affiche Some Error - pourquoi ?
Vérifiez l'adresse IP dans l' Espace Membres.
4.3. Toutes les requêtes échouent, que faire ?
La tâche est probablement mal configurée ou le format de requête est incorrect. Vérifiez également s'il y a des proxys fonctionnels. Vous pouvez aussi essayer d'augmenter l'option Request retries (plus de détails ici : requêtes échouées).
4.4. Combien de comptes faut-il enregistrer pour collecter 1 000 000 de mots-clés avec  SE::Yandex::Wordstat ?
SE::Yandex::Wordstat ?
Il est impossible de dire précisément combien de comptes sont nécessaires, car un compte peut cesser d'être valide après un nombre indéterminé de requêtes. Mais vous pouvez toujours enregistrer de nouveaux comptes en utilisant le scraper  SE::Yandex::Register ou simplement ajouter des comptes existants dans le fichier files/SE-Yandex/accounts.txt.
SE::Yandex::Register ou simplement ajouter des comptes existants dans le fichier files/SE-Yandex/accounts.txt.
4.5. La tâche ne se lance pas, affiche Error: Lock 100 threads failed(20 of limit 100 used) que faire ?
Il est nécessaire d'augmenter le nombre maximum de threads disponibles dans les paramètres du scraper, ou de le réduire dans les paramètres de la tâche. Détails dans Paramètres.
4.6. Peut-on lancer 2 tâches simultanément ?
Oui, A-Parser supporte l'exécution de plusieurs tâches simultanément. Le nombre de tâches actives simultanément se règle dans Paramètres - Paramètres généraux : Maximum de tâches actives.
4.7. Où se trouve le fichier de résultats ?
Dans l'onglet Tasks Queue (Tasks queue) (File des tâches), une fois chaque tâche terminée, vous pouvez télécharger les résultats. Physiquement, ils se trouvent dans le dossier results.
4.8. Peut-on télécharger le fichier de résultats si la collecte n'est pas terminée ?
Non, tant que la collecte de données n'est pas terminée, les résultats ne peuvent pas être téléchargés. Mais vous pouvez les copier depuis le dossier aparser/results lorsque la tâche est arrêtée ou en pause.
4.9. Votre scraper peut-il collecter 1 000 000 de liens pour une seule requête ?
Oui, en utilisant l'option Parser tous les résultats / Parse all results.
4.10. Peut-on utiliser  Rank::CMS,
Rank::CMS,  Net::Whois sans proxy ?
Net::Whois sans proxy ?
Net::Whois - ce n'est pas souhaitable.4.11. Comment collecter des liens depuis Google ?
Il est nécessaire d'utiliser SE::Google.
4.12. Le scraper peut-il suivre les liens ?
Oui, le scraper  HTML::LinkExtractor peut le faire en utilisant l'option Parser jusqu'au niveau / Parse to level
HTML::LinkExtractor peut le faire en utilisant l'option Parser jusqu'au niveau / Parse to level
4.13. La collecte sur Google est très lente, que faire ?
Tout d'abord, il faut consulter les journaux de la tâche, il est possible que toutes les requêtes aient échoué. Si c'est le cas, il faut trouver la raison de l'échec et la corriger. Lors de la collecte de données avec SE::Google, les tentatives échouées dans les journaux sont souvent liées au fait que Google affiche des captchas, ce qui est normal. Vous pouvez connecter Anti-Captcha pour contourner les captchas afin que le scraper ne multiplie pas les tentatives inutiles.
Il existe également un article décrivant les facteurs qui influencent la vitesse de collecte et comment ils agissent : vitesse et principe de fonctionnement des scrapers.
4.14. Votre scraper peut-il collecter des liens dont le texte est uniquement en japonais ?
Oui, pour cela il faut sélectionner la langue souhaitée dans les paramètres du scraper et utiliser des mots-clés japonais.
4.15. Votre scraper peut-il collecter des liens uniquement dans la zone de domaine .de ou .ru ?
Oui. Pour cela, il faut utiliser un filtre.
4.16. Comment obtenir chaque résultat dans le fichier sur une nouvelle ligne ?
Lors du formatage du résultat, utilisez \n. Exemple :
$serp.format('$link\n')
4.17. Comment collecter le top 10 des sites de Google ?
Voici le préréglage :
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. J'ajoute une tâche, je vais dans l'onglet File des tâches - mais elle n'y est pas ! Pourquoi ?
Soit une erreur a été commise lors de la création de la tâche, soit elle est déjà terminée et est passée dans les Completed (Terminées).
4.19. Il est écrit que le fichier n'est pas en utf-8, mais je ne l'ai pas modifié et il est déjà en utf-8, que faire ?
Vérifiez à nouveau. Essayez tout de même de changer l'encodage, par exemple avec Notepad++.
4.20. Dans le fichier de résultats, tout est sur une seule ligne, bien que j'aie mis un saut de ligne dans la tâche - pourquoi ?
Dans les paramètres supplémentaires d'A-Parser, il faut utiliser le saut de ligne CRLF (Windows).
Mais si vous avez déjà collecté les données sans cette option, utilisez un visionneur plus avancé pour consulter le fichier, comme Notepad++.
4.21. Combien de temps faut-il pour vérifier la fréquence de 1 000 requêtes sur Yandex ?
Cet indicateur dépend fortement des paramètres de la tâche, des caractéristiques du serveur, de la qualité des proxys, etc., il est donc impossible de donner une réponse unique.
4.22. Comment configurer le scraper pour avoir requête-lien en résultat ?
Format du résultat :
$p1.serp.format('$query: $link\n')
Le résultat sera :
requête: lien 1
requête: lien 2
requête: lien 3
4.23. Comment recolleter les requêtes échouées et où sont-elles stockées ?
Pour que les requêtes échouées soient sauvegardées, vous devez sélectionner l'option correspondante dans le bloc Queries (Requêtes) de l' Éditeur de tâches. Les requêtes échouées sont stockées dans queries\failed. Vous devez créer une nouvelle tâche et indiquer le fichier des requêtes échouées comme fichier source.
4.24. Comment se débarrasser des balises HTML lors de la collecte de texte ?
Utilisez l'option Remove HTML tags dans le Constructeur de résultats.
4.25. Comment faire pour ne collecter que les domaines ?
Utilisez l'option Extract Domain dans le Constructeur de résultats.
4.26. Quelle est la taille maximale du fichier de requêtes utilisable dans le scraper ?
La taille des fichiers de requêtes et de résultats n'est pas limitée et peut atteindre des valeurs en téraoctets.
4.27. Pourquoi, quand je saisis du texte dans le champ des requêtes, le scraper affiche Queries length limited to 8192 characters ?
Cela se produit car la longueur d'une requête est limitée à 8192 caractères. Pour utiliser des requêtes plus longues, utilisez des fichiers comme source de requêtes.
4.28. Que signifie Threads en attente - 3 ?
Cela signifie qu'il manque des proxys. Réduisez le nombre de threads ou augmentez le nombre de proxys.
4.29. Dans la collecte de test, il s'affiche 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) et ça ne collecte pas, pourquoi ?
Cela indique que les proxys ne sont pas fonctionnels.
4.30. Quelle est la différence entre la langue des résultats et le pays de recherche dans le scraper Google ?
La différence est la suivante : le pays de recherche lie les résultats à un pays spécifique. Par exemple, si vous cherchez acheter fenêtres avec un pays spécifique, la priorité sera donnée aux sites proposant d'acheter des fenêtres dans ce pays. La langue des résultats définit la langue dans laquelle les résultats doivent être affichés.
4.31. Un site spécifique ne se laisse pas scraper. Que se passe-t-il ?
Souvent, le problème vient d'un blocage dû à un ancien user-agent côté serveur. Cela se résout avec un nouvel user-agent ou le code suivant dans le paramètre User agent :
[% tools.ua.random() %]
4.32. Le scraper se fige, plante. Dans le log, on trouve la ligne syswrite: No space left on device
A-Parser manque d'espace sur le disque dur. Libérez de l'espace.
4.33. Mon scraper a commencé à donner none dans les résultats (ou un résultat manifestement faux)
4.34. Une fenêtre avec le message Failed fetch news apparaît constamment
4.35. Comment afficher les n premiers résultats de recherche ?
4.36. Comment suivre la chaîne de redirections ?
4.37. Comment vérifier l'indexation d'un lien sur un site donneur ?
Pour de tels objectifs, il existe un scraper distinct :  Check::BackLink.
Plus de détails dans la discussion.
Check::BackLink.
Plus de détails dans la discussion.
4.38. Le scraper plante sur Linux. Le log contient cette entrée : EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Il est probablement nécessaire d'optimiser le nombre de threads, comme indiqué dans la Documentation : Optimisation de Linux pour un plus grand nombre de threads.
4.39. Où peut-on voir tous les paramètres possibles pour une utilisation via API ?
Obtention d'une requête API dans l'interface.
Il est également possible de générer une config complète de tâche en JSON. Pour cela, prenez le code de la tâche et décodez-le du base64.
4.40. Je télécharge des images à l'aide de  Net::HTTP, mais elles sont toutes corrompues pour une raison quelconque. Que faire ?
Net::HTTP, mais elles sont toutes corrompues pour une raison quelconque. Que faire ?
1) Vérifiez le paramètre Max body size - il faut peut-être l'augmenter. 2) Vérifiez dans les paramètres d'A-Parser le format du saut de ligne : Paramètres supplémentaires - Saut de ligne.
Pour que l'image ne soit pas corrompue, le format UNIX doit être utilisé.
4.41. Comment obtenir l'admin contact depuis le WHOIS ?
Cette tâche se résout facilement à l'aide de la fonction Parse custom result et d'une expression régulière. Détails dans la discussion.
4.42. Expression régulière pour la collecte de numéros de téléphone
4.43. Détermination des sites sans version mobile
4.44. Comment connaître le nom du serveur NS ?
4.45. Comment collecter les liens vers le cache Yandex ?
4.46. Comment collecter les liens de toutes les pages d'un site ?
4.47. Comment collecter le title d'une page ?
4.48. Comment collecter tous les sites d'une zone de domaine donnée ?
4.49. Comment collecter toutes les URL avec paramètres ?
4.50. Comment filtrer les résultats selon plusieurs critères et les répartir dans le rapport ?
4.51. Comment simplifier la structure d'un filtre ?
4.52. Comment trier par fichiers en fonction du résultat ?
4.53. Create new result directory every X number of files (English)
4.54. Premiers pas avec WordStat
4.55. Collecte de blocs de texte > 1000 caractères
4.56. Affichage d'une quantité déterminée de texte d'une page
Cela se résout également à l'aide de Template Toolkit. Plus de détails dans la discussion.
4.57. Vérification de la concurrence et de la présence dans le titre sur Google
4.58. Filtrage par nombre d'occurrences de la requête dans l'ancre et le snippet
4.59. Comment obtenir le contenu d'un article sur une seule ligne ?
4.60. Comment comparer deux dates sous forme de chaînes ?
4.61. Comment collecter les mots mis en évidence dans le snippet ?
4.62. Exemple de tâche utilisant plusieurs scrapers
4.63. Comment mélanger les lignes dans le résultat et comment afficher un nombre aléatoire de résultats ?
4.64. Comment signer le résultat avec MD5 ?
4.65. Comment convertir une date d'un timestamp Unix en représentation textuelle ?
4.66. Parse to level, comment collecter avec limitation ?
4.67. Le scraper plante sur Linux au lancement d'une tâche. Le log contient ces lignes : Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
Il est nécessaire d'exécuter la commande suivante dans la console :
apt-get --reinstall --purge install netbase
4.68. Erreur Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
Vous devez lancer A-Parser sans les droits root. Plus précisément : depuis l'utilisateur root, créez un nouvel utilisateur sans droits root (si vous en avez déjà un, utilisez-le simplement) puis autorisez cet utilisateur à interagir avec le répertoire d'A-Parser. Ensuite, connectez-vous avec le nouvel utilisateur et lancez-le depuis celui-ci.
Sous l'utilisateur root, créez un utilisateur en suivant ce guide.
Pour autoriser l'utilisateur créé à interagir avec le répertoire d'A-Parser, vous devez lui donner les droits. Pour cela, connectez-vous sous root et donnez les droits avec la commande :
chown -R user:user aparser
4.69. Erreur Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Sous l'utilisateur root, exécutez la commande :
sysctl -w kernel.unprivileged_userns_clone=1
Le redémarrage d'A-Parser n'est pas requis.
Pour CentOS 7, la solution est dans ce sujet.
Sous l'utilisateur root, exécutez la commande :
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Ensuite, redémarrez sysctl avec la commande :
sysctl -p
4.70. Erreur JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
L'erreur survient en raison de l'absence de bibliothèques dans l'OS nécessaires au fonctionnement de Chrome.
La liste des bibliothèques requises pour Chrome se trouve dans Chrome headless doesn't launch on UNIX.
4.71. Pourquoi le captcha n'est-il pas résolu ? Dans le log, on voit qu'A-Parser a reçu des points d'interrogation de Xevil au lieu de la réponse au captcha
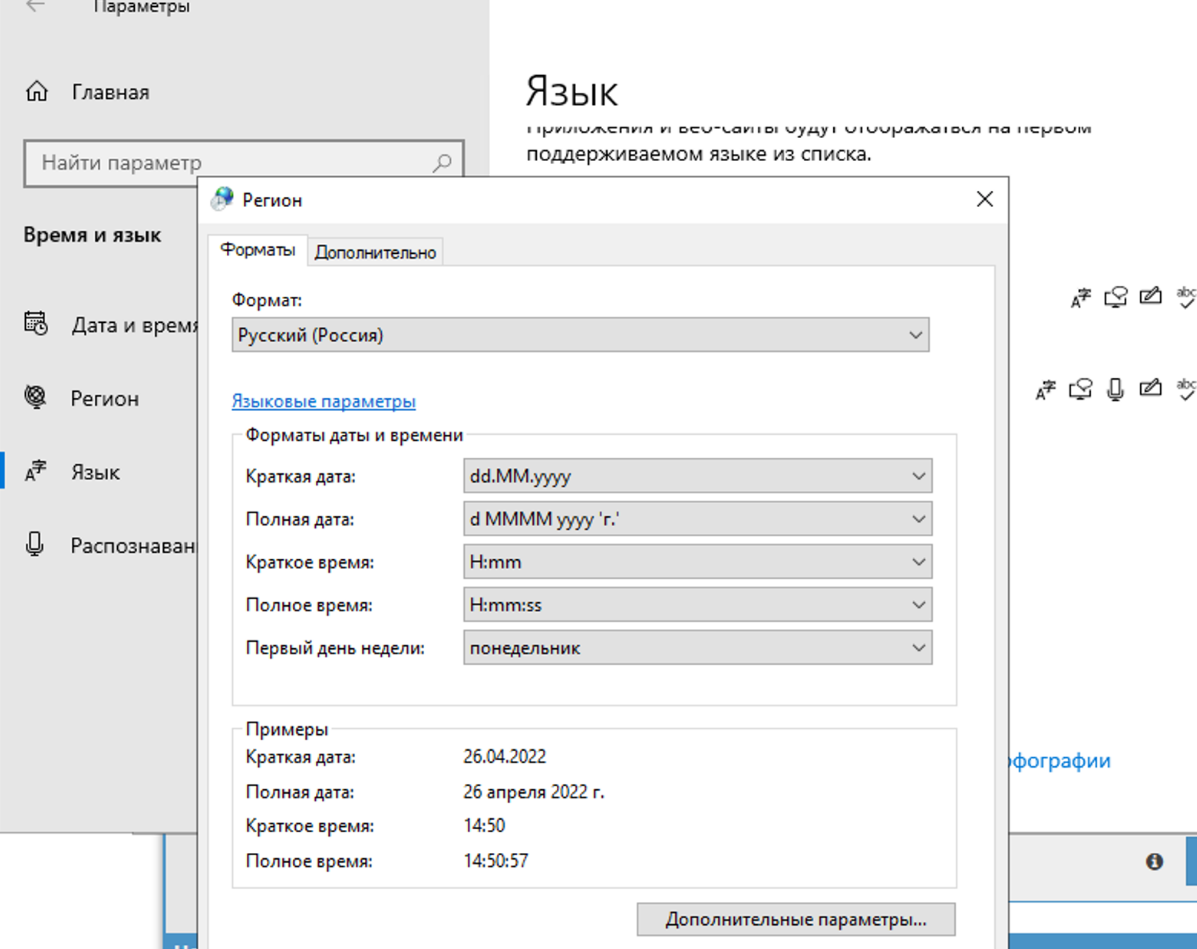
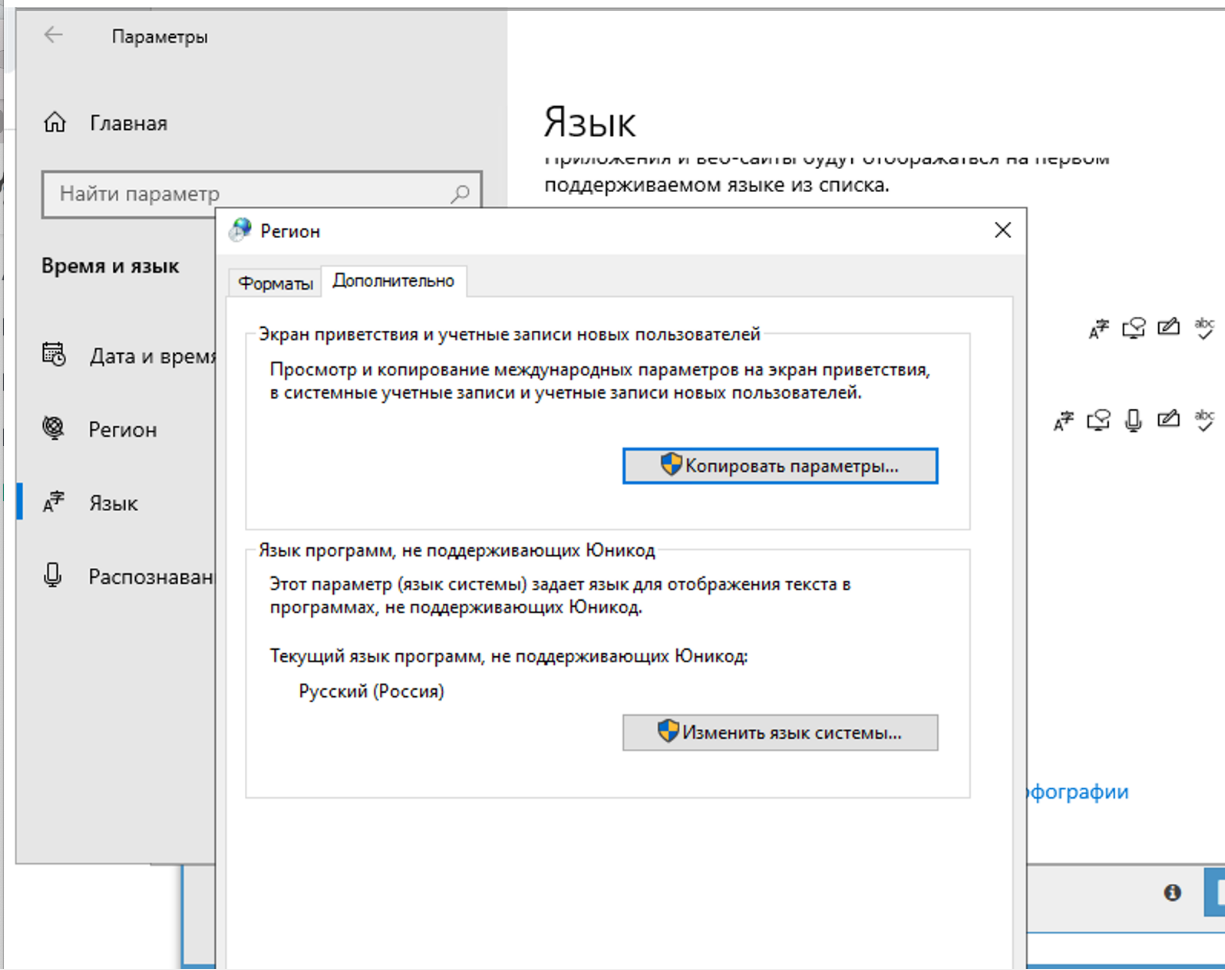
Dans les paramètres de région, il faut passer en russe.
Il faut changer cela uniquement dans l'onglet avancé. Cela n'affecte pas la résolution des captchas, mais il y aura un problème d'encodage dans Xumer lui-même si vous changez aux deux endroits.