Déduplication des résultats
Déduplication, suppression des doublons, suppression des répétitions - tout cela implique que nous n'avons pas besoin de résultats répétitifs. Dans A-Parser, il existe 2 méthodes de déduplication, examinons chacune d'elles en détail.
Déduplication des résultats par ligne
Cette méthode fonctionne après la génération du résultat, juste avant l'écriture du résultat dans le fichier, chaque ligne est vérifiée pour son unicité et seules les nouvelles lignes uniques sont enregistrées dans le fichier.
Voir aussi : Ordre de traitement des requêtes
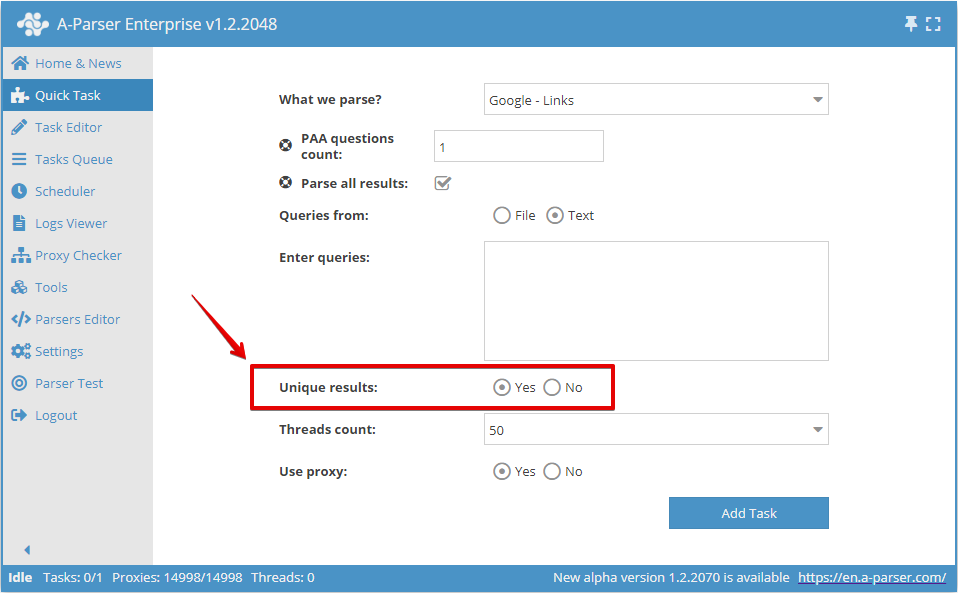
Vous pouvez activer l'unicité par ligne dans le Quick Task :
Ou dans l'Éditeur de tâches :
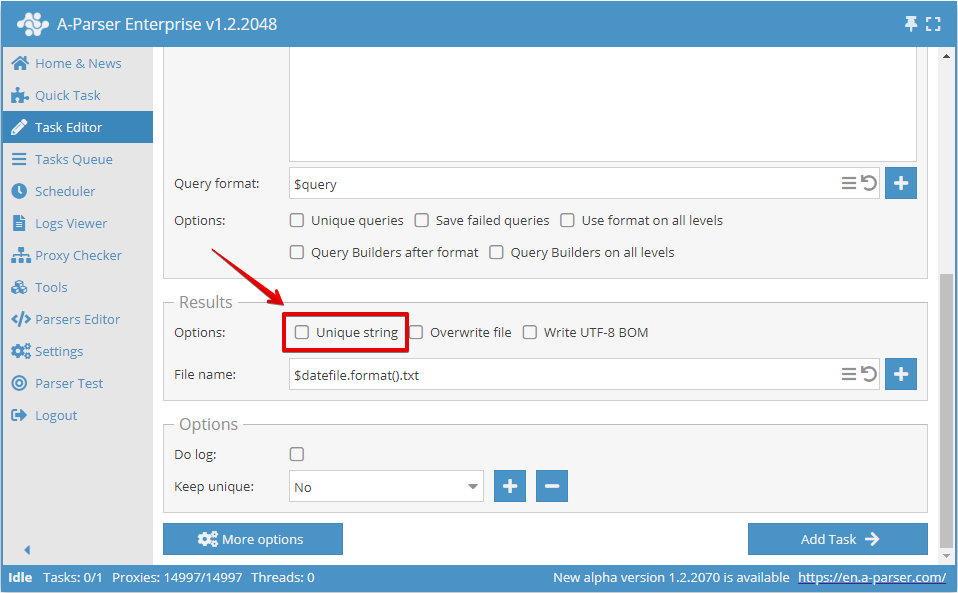
Déduplication par n'importe quel résultat
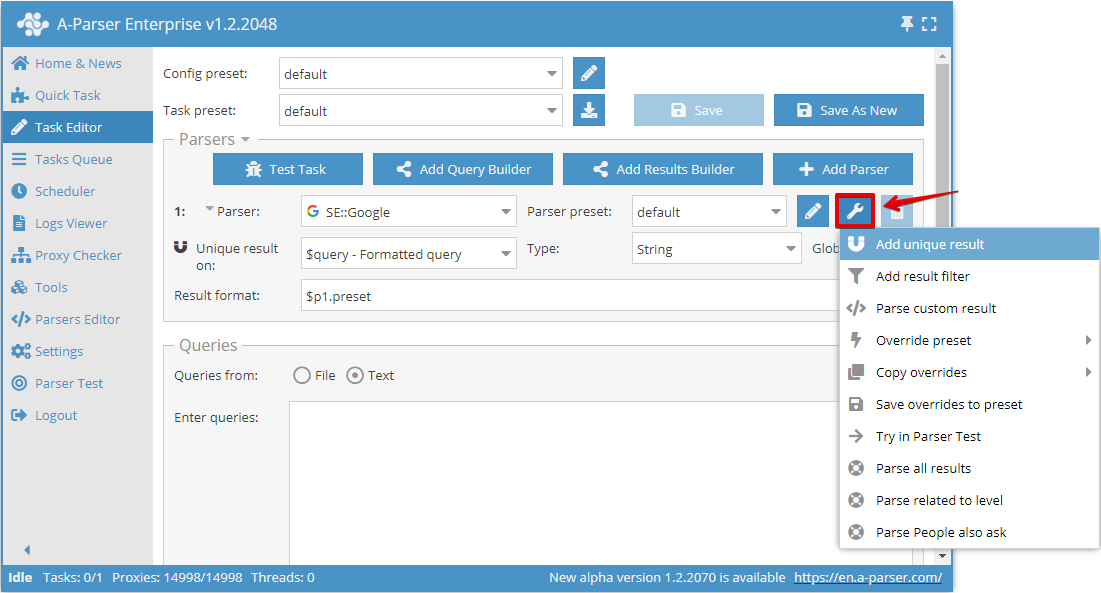
La déduplication par n'importe quel résultat permet d'effectuer la déduplication directement sur le résultat choisi d'un scraper spécifique. Vous pouvez ajouter ce type de déduplication dans l'Éditeur de tâches en cliquant sur l'icône d'outil à droite du scraper et en appuyant sur Add unique result (Ajouter la déduplication) :
Maintenant, vous pouvez choisir sur quel résultat effectuer la déduplication et le type de déduplication :
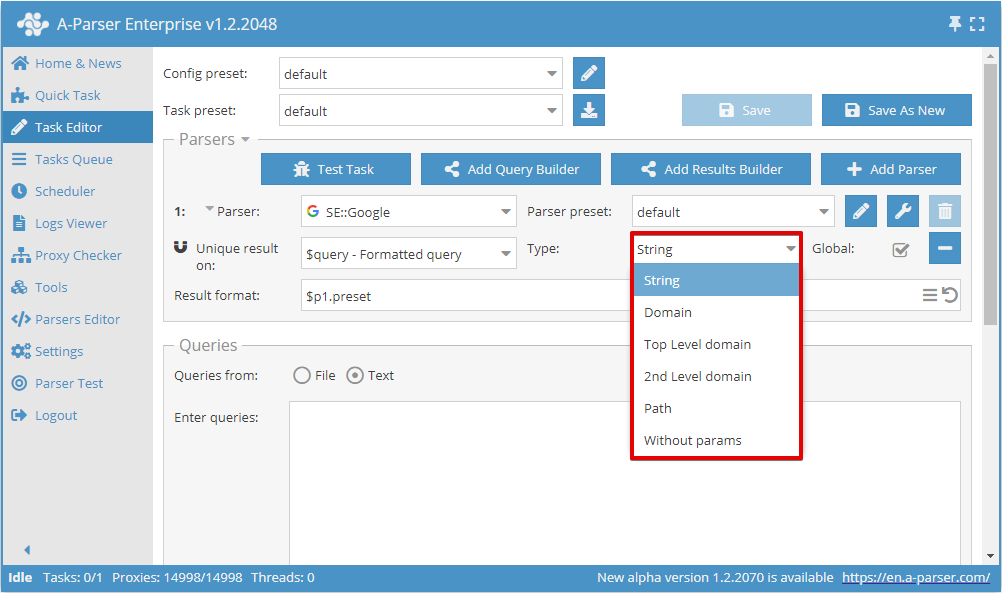
Le commutateur Global (Globalement) est utilisé lorsque 2 scrapers ou plus sont sélectionnés ; il détermine s'il faut effectuer une déduplication commune ou séparée pour chaque scraper.
Type de déduplication
| Paramètre | Description |
|---|---|
| String | Déduplication par ligne (toute la ligne de résultat est comparée intégralement) |
| Domain | Déduplication par domaine (le domaine est comparé intégralement, par exemple www.domain.com et domain.com sont des domaines différents) |
| Top Level domain | Déduplication par domaine principal en tenant compte des domaines régionaux, commerciaux, éducatifs et autres (par exemple domain.co.uk et domain2.co.uk sont des domaines différents, tandis que sub1.domain.com et sub2.domain.com sont identiques) |
| Domaine de 2ème niveau | Déduplication par domaine de 2ème niveau (les domaines de deuxième niveau sont comparés, par exemple www.domain.com, domain.com et user.subdomain.domain.com sont tous un seul et même domaine) |
| Path | Déduplication par chemin (les parties du lien jusqu'au fichier sont comparées, par exemple http://domain.com/path1/file.php et http://domain.com/path1/file2.php sont des parties de lien identiques jusqu'au fichier) |
| Without params | Déduplication par lien sans paramètres (les liens sans paramètres sont comparés, par exemple http://domain.com/file.php?page=1 et http://domain.com/file.php?page=2 sont des liens identiques) |
Déduplication des requêtes
La déduplication des requêtes envoie directement à la collecte de données uniquement les requêtes uniques qui n'ont pas été traitées précédemment dans la tâche actuelle. Principaux cas d'utilisation :
- Si les requêtes initiales contiennent des doublons et qu'il est préférable de ne pas les collecter (double travail)
- Lors de l'utilisation de l'option Parse to level (Parser jusqu'au niveau), il est nécessaire d'utiliser uniquement des requêtes uniques afin d'empêcher l'expansion et le bouclage des requêtes (par exemple lors de l'utilisation du scraper
 HTML::LinkExtractor)
HTML::LinkExtractor)
Dans tous les autres cas, l'utilisation inutile de la déduplication des requêtes ne fera que ralentir le travail global du scraper
Conservation de l'état de déduplication entre les tâches
Il est possible de sauvegarder la base de déduplication pour une utilisation dans de futures tâches, ce qui permet de ne conserver que les nouveaux résultats uniques dans les nouvelles tâches (par exemple les liens lors de la collecte de données de la SERP dans  SE::Google)
SE::Google)
Pour sauvegarder la base de déduplication, il est nécessaire de créer un nouveau nom de base lors de l'ajout de la première tâche :
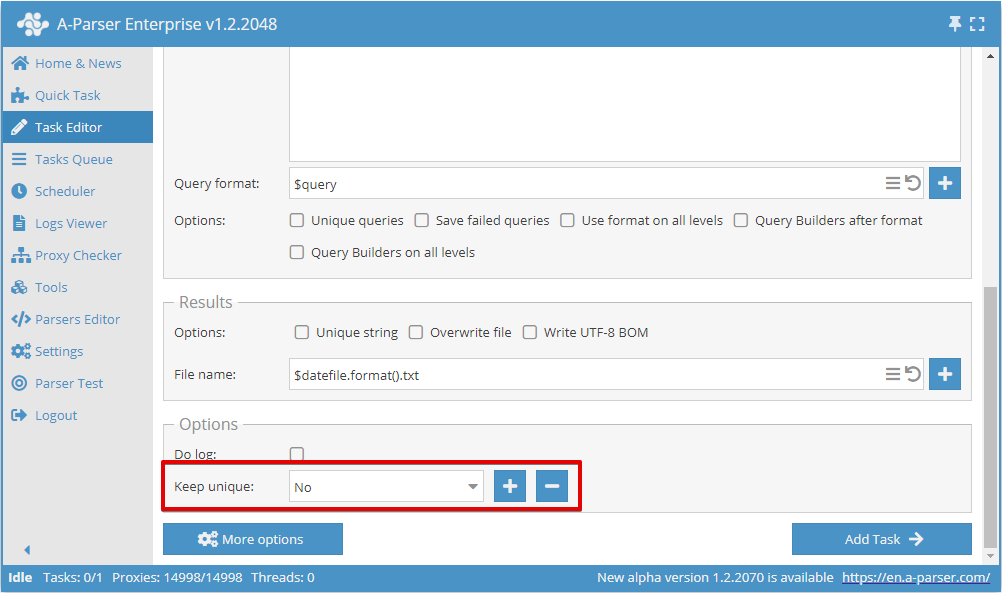
Pour toutes les tâches suivantes, il est nécessaire de sélectionner le nom de la base créé précédemment, ainsi seuls les nouveaux résultats uniques seront conservés, que l'enregistrement des résultats se fasse dans le même fichier que la première tâche ou dans un nouveau fichier.