Requêtes HTTP (+gestion des cookies, proxy, sessions)
Méthodes de la classe de base
Pour collecter des données à partir d'une page Web, vous devez effectuer une requête HTTP. Dans l' JavaScript API v2 d'A-Parser, une méthode facile à
utiliser pour exécuter des requêtes HTTP est implémentée, laquelle renvoie en réponse un objet JSON en fonction des
arguments de la méthode spécifiés. Ci-après, vous apprendrez : comment une requête HTTP est effectuée, quels arguments et options possède la méthode, les résultats
des options spécifiées, comment spécifier la condition de succès d'une requête HTTP, et plus encore.
Sont également décrites les méthodes permettant de manipuler facilement les cookies, les proxys et la session dans le scraper créé. Après l'exécution réussie d'une requête HTTP, ou avant l'exécution, vous pouvez définir/modifier les données du proxy/cookie/session pour l'exécution des requêtes HTTP ou les enregistrer pour une exécution par un autre thread à l'aide du Gestionnaire de sessions.
Ces méthodes sont héritées de BaseParser et constituent la base pour la création de vos propres scrapers.
await this.request(method, url[, queryParams][, opts])
await this.request(method, url, queryParams, opts)
Obtention d'une réponse HTTP sur demande, les arguments suivants sont spécifiés :
method- méthode de requête (GET, POST...)url- lien pour la requêtequeryParams- hash avec les paramètres GET ou hash avec le corps de la requête POSTopts- hash avec les options de la requête
opts.check_content
check_content: [ condition1, condition2, ...] - tableau de conditions pour vérifier le contenu reçu, si la vérification
échoue, la requête sera répétée avec un autre proxy.
Possibilités :
- utilisation de chaînes de caractères comme conditions (recherche par occurrence de chaîne)
- utilisation d'expressions régulières comme conditions
- utilisation de vos propres fonctions de vérification, auxquelles sont transmises les données et les en-têtes de la réponse
- possibilité de définir plusieurs types de conditions à la fois
- pour une négation logique, placez la condition dans un tableau, c'est-à-dire que
check_content: ['xxxx', [/yyyy/]]signifie que la requête sera considérée comme réussie si les données reçues contiennent la sous-chaînexxxxet que, parallèlement, l'expression régulière/yyyy/ne trouve aucune correspondance sur la page
Pour une requête réussie, toutes les vérifications indiquées dans le tableau doivent passer
Exemple (les commentaires indiquent ce qui est nécessaire pour que la requête soit considérée comme réussie) :
let response = await this.request('GET', set.query, {}, {
check_content: [
/<\/html>|<\/body>/, // cette expression régulière doit correspondre sur la page reçue
['XXXX'], // cette sous-chaîne ne doit pas être présente sur la page reçue
'</html>', // cette sous-chaîne doit être présente sur la page reçue
(data, hdr) => {
return hdr.Status == 200 && data.length > 100;
} // cette fonction doit retourner true
]
});
opts.decode
decode: 'auto-html' - détection automatique de l'encodage et conversion en utf8
Valeurs possibles :
auto-html- basé sur les en-têtes, les balises meta et le contenu de la page (option recommandée optimale)utf8- indique que le document est en encodage utf8<encoding>- tout autre encodage
opts.headers
headers: { ... } - hash avec les en-têtes, le nom de l'en-tête est défini en minuscules, on peut y inclure notamment cookie.
Exemple :
headers: {
accept: 'image/avif,image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-encoding': 'gzip, deflate, br',
cookie: 'a=321; b=test',
'user-agent' 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
opts.headers_order
headers_order: ['cookie', 'user-agent', ...] - permet de redéfinir l'ordre de tri des en-têtes
opts.onlyheaders
onlyheaders: 0 - définit la lecture de data, si activé (1), récupère uniquement les en-têtes
opts.recurse
recurse: N - nombre maximum de redirections à suivre, par défaut 7, utilisez 0 pour désactiver le suivi des
redirections
opts.proxyretries
proxyretries: N - nombre de tentatives d'exécution de la requête, par défaut pris dans les paramètres du scraper
opts.parsecodes
parsecodes: { ... } - liste des codes de réponse HTTP que le scraper considérera comme réussis, par défaut pris dans les
paramètres du scraper. Si vous spécifiez '*': 1, toutes les réponses seront considérées comme réussies.
Exemple :
parsecodes: {
200: 1,
403: 1,
500: 1
}
opts.timeout
timeout: N - délai d'attente de la réponse en secondes, par défaut pris dans les paramètres du scraper
opts.do_gzip
do_gzip: 1 - définit s'il faut utiliser la compression (gzip/deflate/br), activé par défaut (1), pour désactiver
il faut définir la valeur à 0
opts.max_size
max_size: N - taille maximale de la réponse en octets, par défaut pris dans les paramètres du scraper
opts.cookie_jar
cookie_jar: { ... } - hash avec les cookies. Exemple de hash :
"cookie_jar": {
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
opts.attempt
attempt: N - indique le numéro de la tentative actuelle, lors de l'utilisation de ce paramètre, le gestionnaire de tentatives intégré pour
cette requête est ignoré
opts.browser
browser: 1 - émulation automatique des en-têtes de navigateur (1 - activé, 0 - désactivé)
opts.use_proxy
use_proxy: 1 - redéfinit l'utilisation du proxy pour une requête individuelle à l'intérieur du scraper JS par-dessus le
paramètre global Use proxy (1 - activé, 0 - désactivé)
opts.noextraquery
noextraquery: 0 - désactive l'ajout de Extra query string à l'URL de la requête (1 - activé, 0 - désactivé)
opts.save_to_file
save_to_file: file - permet de télécharger un fichier directement sur le disque, sans passer par l'écriture en mémoire. À la place de file, indiquez le nom et
le chemin sous lequel enregistrer le fichier. Lors de l'utilisation de cette option, tout ce qui concerne data est ignoré (la vérification du contenu
dans opts.check_content ne sera pas effectuée, response.data sera vide, etc.)
opts.bypass_cloudflare
bypass_cloudflare: 0 - contournement automatique de la protection JavaScript de CloudFlare en utilisant le navigateur Chrome (1 - activé, 0 -
désactivé)
Le contrôle de Chrome Headless dans ce cas est effectué par les paramètres du scraper bypassCloudFlareChromeMaxPages
et bypassCloudFlareChromeHeadless, qui doivent être spécifiés dans static defaultConf et static editableConf :
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'Title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: "$title\n",
bypass_cloudflare: 1,
bypassCloudFlareChromeMaxPages: 20,
bypassCloudFlareChromeHeadless: 0
};
static editableConf: typeof BaseParser.editableConf = [
['bypass_cloudflare', ['textfield', 'bypass_cloudflare']],
['bypassCloudFlareChromeMaxPages', ['textfield', 'bypassCloudFlareChromeMaxPages']],
['bypassCloudFlareChromeHeadless', ['textfield', 'bypassCloudFlareChromeHeadless']],
];
async parse(set, results) {
const {success, data, headers} = await this.request('GET', set.query, {}, {
bypass_cloudflare: this.conf.bypass_cloudflare
});
return results;
}
opts.follow_meta_refresh
follow_meta_refresh: 0 - permet de suivre les redirections déclarées via la balise meta HTML :
<meta http-equiv="refresh" content="time; url=..."/>
opts.redirect_filter
redirect_filter: (hdr) => 1 | 0 - permet de définir une fonction de filtrage pour le suivi des redirections, si la fonction
renvoie 1, le scraper suivra la redirection (en tenant compte du paramètre opts.recurse), si elle renvoie 0, le suivi des
redirections s'arrêtera :
redirect_filter: (hdr) => {
if (hdr.location.match(/login/))
return 1;
return 0;
}
opts.follow_common_rediects
opts.follow_common_rediects: 0 - définit s'il faut suivre les redirections standard (par exemple http -> https
et/ou www.domain.com -> domain.com), si vous spécifiez 1, le scraper suivra les redirections standard sans tenir compte du
paramètre opts.recurse
opts.http2
opts.http2: 0 - définit s'il faut utiliser le protocole HTTP/2 lors de l'exécution des requêtes, par défaut
HTTP/1.1 est utilisé
opts.randomize_tls_fingerprint
opts.randomize_tls_fingerprint: 0 - cette option permet de contourner le bannissement des sites par empreinte TLS (1 - activé, 0 -
désactivé)
opts.tlsOpts
tlsOpts: { ... } – permet de
transmettre des paramètres pour
les connexions https
await this.cookies.*
Gestion des cookies pour la requête actuelle
.getAll()
Obtention d'un tableau de cookies
await this.cookies.getAll();
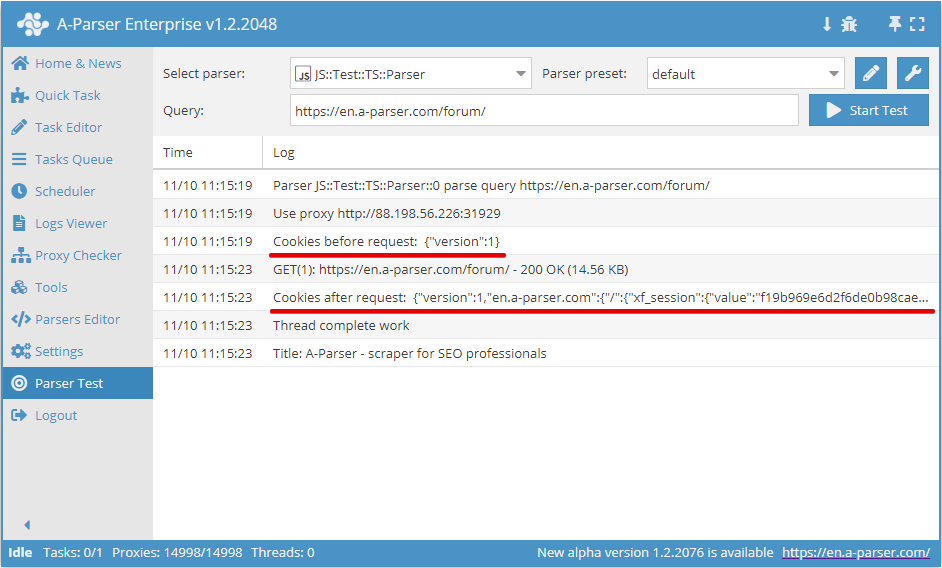
.setAll(cookie_jar)
Définition des cookies, un hash avec les cookies doit être passé en argument
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.setAll({
"version": 1,
".google.com": {
"/": {
"login": {
"value": "true"
},
"lang": {
"value": "ru-RU"
}
}
},
".test.google.com": {
"/": {
"id": {
"value": 155643
}
}
}
});
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
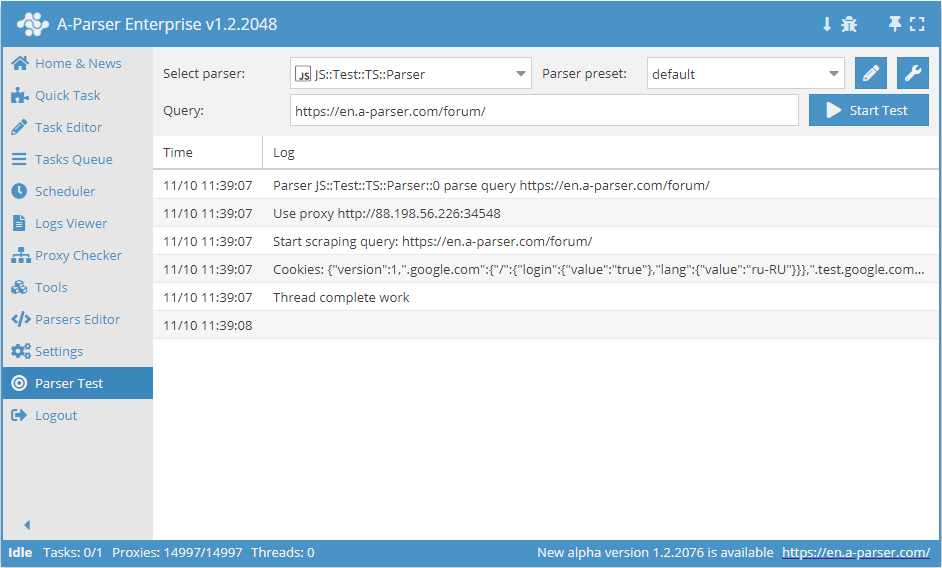
.set(host, path, name, value)
await this.cookies.set(host, path, name, value) - définition d'un cookie individuel.
La portée de visibilité du cookie dépend directement du format du domaine spécifié, c'est pourquoi dans host la présence d'un point devant l'hôte est prise en compte :
- si un point est spécifié (
this.cookies.set('.domain.com', ...)), le cookie sera utilisé pour tous les sous-domaines (par exemple a.domain.com, b.a.domain.com) - si l'hôte est spécifié sans point devant (
this.cookies.set('site.com', ...)), le cookie sera utilisé strictement pour l'hôte spécifié (host-only cookie) et n'est pas transmis aux sous-domaines
Cette différence est cruciale, car l'existence simultanée de cookies avec et sans point peut entraîner leur duplication et un comportement imprévisible du site. Pour une émulation correcte, vérifiez toujours comment le site cible définit les cookies (avec l'attribut Domain ou sans) et utilisez le format correspondant.
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-1', 1);
await this.cookies.set('.a-parser.com', '/', 'Test-cookie-2', 'test-value');
let cookies = await this.cookies.getAll();
this.logger.put("Cookies: " + JSON.stringify(cookies));
results.SKIP = 1;
return results;
}
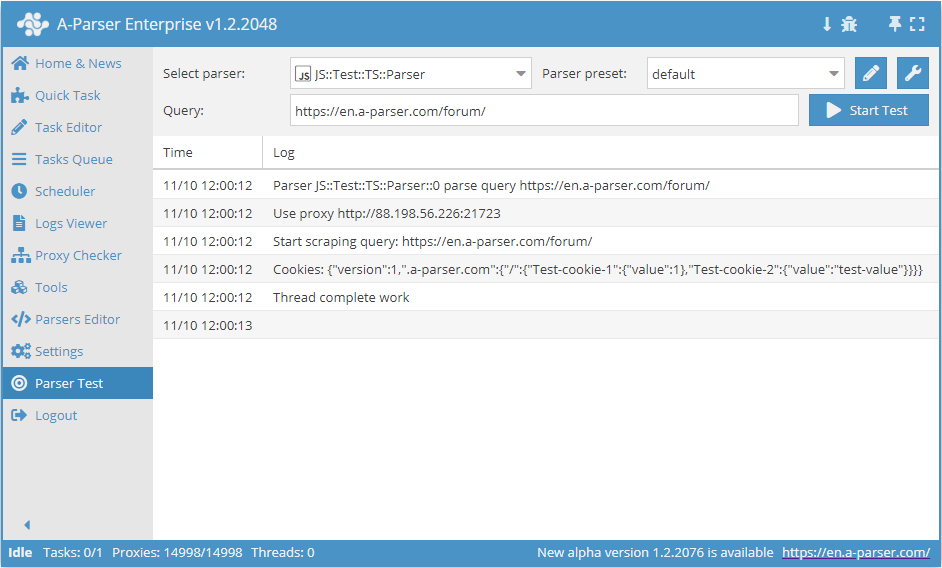
await this.proxy.*
Gestion du proxy
.next()
Changer de proxy pour le suivant, l'ancien proxy ne sera plus utilisé pour la requête actuelle
.ban()
Changer et bannir le proxy (nécessaire lorsque le service bloque le travail par IP), le proxy sera banni pour la durée
indiquée dans les paramètres du scraper (proxybannedcleanup)
.get()
Obtenir le proxy actuel (le dernier proxy avec lequel la requête a été faite)
.set(proxy, noChange?)
await this.proxy.set('http://127.0.0.1:8080', true) - définir le proxy pour la prochaine requête. Le paramètre noChange est facultatif, s'il est défini sur true, le proxy ne changera pas entre les tentatives. Par défaut noChange = false
await this.sessionManager.*
Méthodes pour travailler avec les sessions. Chaque session stocke obligatoirement le proxy et les cookies utilisés. Il est également possible de sauvegarder des données arbitraires supplémentaires.
Pour utiliser les sessions dans un scraper JS, vous devez d'abord obligatoirement initialiser le Gestionnaire de sessions. Cela se fait à l'aide de la méthode await this.sessionManagerinit() dans init()
.init(opts?)
Initialisation du Gestionnaire de sessions. Un objet (opts) avec des paramètres supplémentaires peut être passé en argument (tous les paramètres sont facultatifs) :
name- permet de redéfinir le nom du scraper auquel appartiennent les sessions, par défaut égal au nom du scraper dans lequel l'initialisation a lieuwaitForSession- indique au scraper d'attendre une session jusqu'à ce qu'elle apparaisse (ceci est pertinent uniquement lorsque plusieurs tâches s'exécutent, par exemple l'une génère des sessions, l'autre les utilise), c'est-à-dire que.get()et.reset()attendront toujours une sessiondomain- indique de chercher des sessions parmi toutes celles enregistrées pour ce scraper (si aucune valeur n'est définie), ou seulement pour un domaine spécifique (il est nécessaire de spécifier le domaine avec un point devant, par exemple.site.com)sessionsKey- permet de définir manuellement le nom du stockage des sessions, s'il n'est pas défini, le nom est formé automatiquement sur la base dename(ou du nom du scraper sinamen'est pas défini), du domaine et du proxycheckerexpire- définit la durée de vie de la session en minutes, par défaut illimitée
Exemple d'utilisation :
async init() {
await this.sessionManager.init({
name: 'JS::test',
expire: 15 * 60
});
}
.get(opts?)
Obtention d'une nouvelle session, doit être appelée avant d'effectuer la requête (avant la première tentative). Renvoie un objet avec des données arbitraires enregistrées dans la session. Un objet (opts) avec des paramètres supplémentaires peut être passé en argument (tous les paramètres sont facultatifs) :
waitTimeout- possibilité d'indiquer combien de minutes attendre l'apparition d'une session, fonctionne indépendamment du paramètrewaitForSessiondans.init()(l'ignore), à l'expiration une session vide sera utiliséetag- obtention d'une session avec un tag donné, peut être utilisé par exemple avec le nom de domaine pour l'association des sessions aux domaines d'où elles ont été obtenues
Exemple d'utilisation :
await this.sessionManager.get({
waitTimeout: 10,
tag: 'test session'
})
.reset(opts?)
Nettoyage des cookies et obtention d'une nouvelle session. Doit être utilisé si la requête n'a pas réussi avec la session actuelle. Renvoie un objet avec des données arbitraires enregistrées dans la session. Un objet (opts) avec des paramètres supplémentaires peut être passé en argument (tous les paramètres sont facultatifs) :
waitTimeout- possibilité d'indiquer combien de minutes attendre l'apparition d'une session, fonctionne indépendamment du paramètrewaitForSessiondans.init()(l'ignore), à l'expiration une session vide sera utiliséetag- obtention d'une session avec un tag donné, peut être utilisé par exemple avec le nom de domaine pour l'association des sessions aux domaines d'où elles ont été obtenues
Exemple d'utilisation :
await this.sessionManager.reset({
waitTimeout: 5,
tag: 'test session'
})
.save(sessionOpts?, saveOpts?)
Enregistrement d'une session réussie avec la possibilité de sauvegarder des données arbitraires dans la session. Supporte 2 arguments facultatifs :
sessionOpts- données arbitraires à stocker dans la session, peut être un nombre, une chaîne, un tableau ou un objetsaveOpts- objet avec les paramètres d'enregistrement de la session :multiply- paramètre facultatif, permet de multiplier la session, une valeur numérique doit être indiquéetag- paramètre facultatif, définit un tag pour la session enregistrée, peut être utilisé par exemple avec le nom de domaine pour l'association des sessions aux domaines d'où elles ont été obtenues
Exemple d'utilisation :
await this.sessionManager.save('some data here', {
multiply: 3,
tag: 'test session'
})
.count()
Renvoie le nombre de sessions pour le Gestionnaire de sessions actuel
Exemple d'utilisation :
let sesCount = await this.sessionManager.count();
.removeById(sessionId)
Supprime toutes les sessions avec un id donné. Renvoie le nombre de sessions supprimées. L'id de la session actuelle est contenu dans la variable this.sessionId
Exemple d'utilisation :
const removedCount = await this.sessionManager.removeById(this.sessionId);
Exemple complet d'utilisation du Gestionnaire de sessions
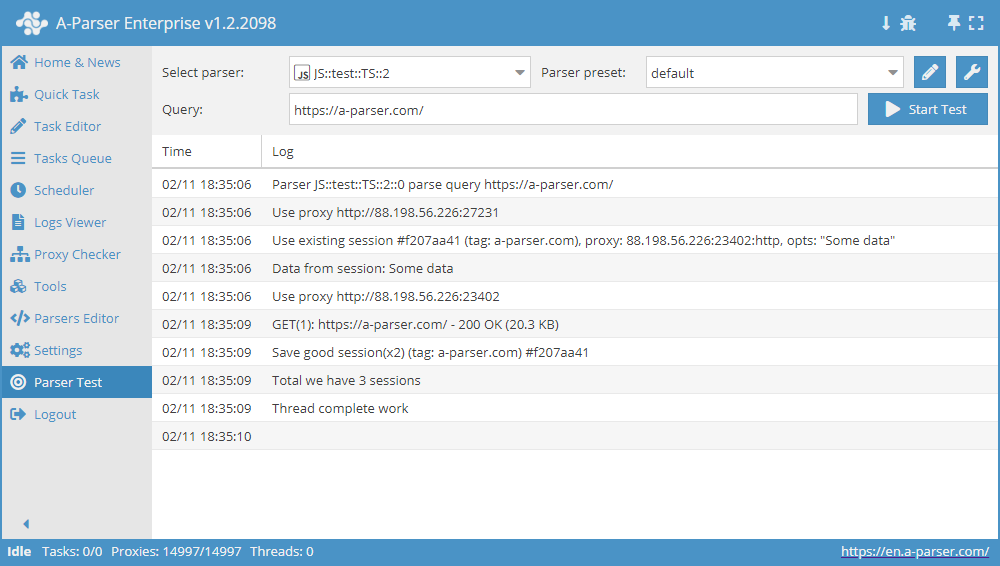
async init() {
await this.sessionManager.init({
expire: 15 * 60
});
}
async parse(set, results) {
let ses = await this.sessionManager.get();
for(let attempt = 1; attempt <= this.conf.proxyretries; attempt++) {
if(ses)
this.logger.put('Data from session:', ses);
const { success, data } = await this.request('GET', set.query, {}, { attempt });
if(success) {
// process data here
results.success = 1;
break;
} else if(attempt < this.conf.proxyretries) {
const removedCount = await this.sessionManager.removeById(this.sessionId);
this.logger.put(`Removed ${removedCount} bad sessions with id #${this.sessionId}`);
ses = await this.sessionManager.reset();
}
}
if(results.success) {
await this.sessionManager.save('Some data', { multiply: 2 });
this.logger.put(`Total we have ${await this.sessionManager.count()} sessions`);
}
return results;
}
Méthodes de requêtes await this.request
Méthode GET
Il est possible de transmettre les paramètres de la requête directement dans la chaîne de requête https://a-parser.com/users/?type=staff :
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/?type=staff');
Ou comme un objet dans queryParams, où key: value est égal à param=value :
const { success, data, headers } = await this.request('GET', 'https://a-parser.com/users/', {
type: 'staff'
});
Méthode POST
Si la méthode POST est utilisée, le corps de la requête peut être transmis de deux manières :
Énumérer les noms des variables et leurs valeurs dans
queryParams, par exemple :{
"key": set.query,
"id": 1234,
"type": "text"
}Les énumérer dans
opts.body, par exemple :body: 'key=' + set.query + '&id=1234&type=text'
Si le corps de la requête est transmis sous forme d'objet, il est automatiquement converti au format form-urlencoded ; de même, si body est spécifié et que
l'en-tête content-type n'est pas spécifié, alors content-type: application/x-www-form-urlencoded sera automatiquement attribué :
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {
title: 'foo,',
body: 'bar',
userId: 1
});
Si le corps de la requête POST est une chaîne de caractères ou un buffer, il est transmis tel quel :
// requête avec une chaîne
const string = 'title=foo&body=bar&userId=1';
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: string
});
// requête avec un buffer
const string = 'title=foo&body=bar&userId=1';
const buf = Buffer.from(string, 'utf8');
const { success, data, headers } = await this.request('POST', 'https://jsonplaceholder.typicode.com/posts', {}, {
body: buf
});
Chargement de fichiers
Envoi d'un fichier par requête POST en utilisant le module form-data :
const file = fs.readFileSync('pathToFile');
const FormData = require('form-data');
const format = new FormData();
format.append('file', file, 'fileName.ext');
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: format.getHeaders(),
body: format.getBuffer()
});
Exemple d'envoi de fichier dans une requête POST avec le type de contenu multipart/form-data :
const EOL = '\r\n';
const file = fs.readFileSync('pathToFile');
const boundary = '----WebKitFormBoundary' + String(Math.random()).slice(2);
const requestHeaders = {
'content-type': 'multipart/form-data; boundary=' + boundary
};
const body = '--'
+ boundary
+ EOL
+ 'Content-Disposition: form-data; name="file"; filename="fileName.ext"'
+ EOL
+ 'Content-Type: text/html'
+ EOL
+ EOL
+ file
+ EOL
+ '--'
+ boundary
+ '--';
const { success, data, headers } = await this.request('POST', 'https://file.io', {}, {
headers: requestHeaders,
body
});