模板引擎工具 (tools)
在 Template Toolkit 模板引擎中,可以使用全局变量 $tools,它包含了一组在任何模板以及 JS 爬虫工具内部均可使用的工具集。
此外,还存在变量 $tools.error,它包含了所有工具在运行过程中产生的错误描述。
添加查询 $tools.query.*
该工具允许在任务运行期间,根据已抓取的结果直接向现有查询中添加新查询。在未实现 Parse to level 功能的爬虫工具中,它可以作为该功能的替代方案。 共有 2 个方法:
[% tools.query.add(query, maxLevel) %]- 添加单个查询[% tools.query.addAll(array, item, maxLevel) %]- 添加查询数组
参数 maxLevel 指定添加查询的最高层级,该参数是可选的:如果省略,爬虫工具实际上会持续添加新查询,直到没有新查询为止。同时建议开启 Unique queries (唯一查询) 选项,以避免死循环和爬虫工具的过度工作。
可以为子查询设置自定义层级。这可用于逻辑分层,即每一层代表一个独立的功能。
示例:
[% tools.query.add({query => query, lvl => 1}) %]- 将查询添加到指定层级。
JS 示例:
this.query.add({
query: "some query",
lvl: 1,
})
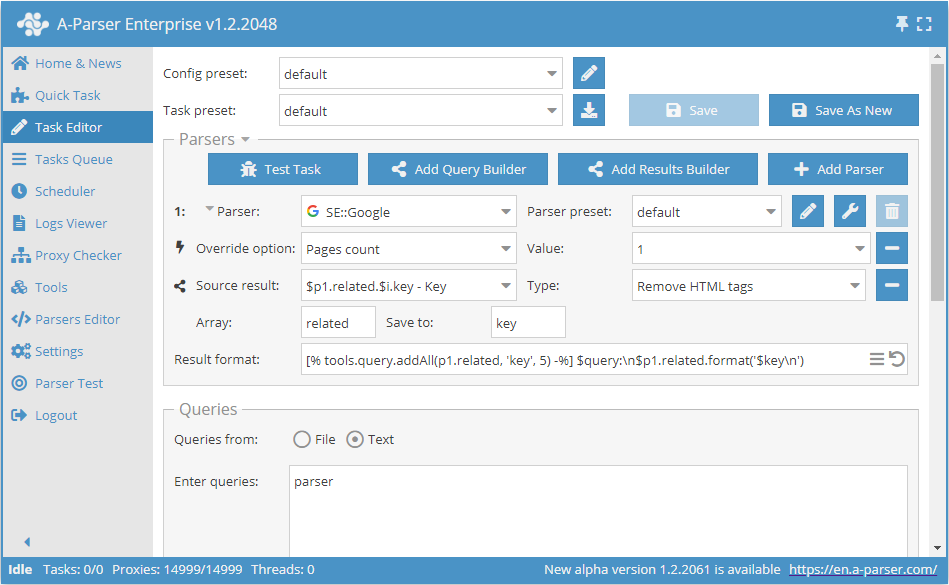
预设运行结果截图示例:
爬虫工具:
parser
what is parsing in programming
parsing in compiler
compiler and parser development
what is syntax analysis
difference between lexical analysis and syntax analysis
syntax analyzer
parser programming language
parser:
parser definition
xml parser
parser generator
parser swtor
parser c++
ffxiv parser
html parser
parser java
what is parsing in programming:
parse wikipedia
parser compiler
what is a parser
parsing programming languages
definition of parser
parsing c++
parser define
parsing java
html parser:
online html parser
html parser php
html parser java
...
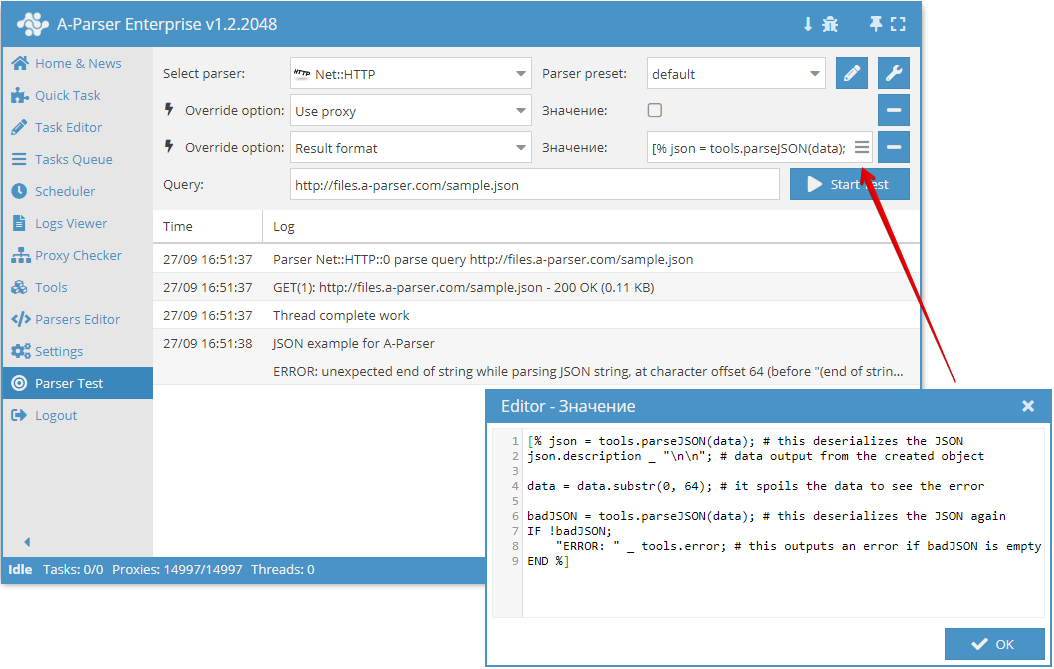
解析 JSON 结构 $tools.parseJSON()
该工具允许将 JSON 格式的数据反序列化为模板引擎中可用的变量(对象)。使用示例:
[% tools.parseJSON(data) %]
反序列化后,可以像访问普通变量和数组一样访问所得对象中的键。
如果传入的参数是无效的 JSON 字符串,爬虫工具会将错误记录在 $tools.error 中。
输出为 CSV $tools.CSVline
该工具会自动将值转换为 CSV 格式并添加换行符,因此在结果格式中只需列出所需的变量,输出即为有效的 CSV 文件,可直接导入 Google Docs / Excel 等软件。
使用示例:
[% tools.CSVline(query, p1.serp.0.link, p2.title) %]
使用 $tools.CSVline() 的视频:
使用 SQLite 数据库 $tools.sqlite.*
该工具可以轻松且完整地操作 SQLite 数据库。共有三个方法:
$tools.sqlite.get()- 该方法允许使用 SELECT 从数据库获取单条信息,例如:
[% res = tools.sqlite.get('results/test.sqlite', 'SELECT COUNT(*) AS count FROM test') %]
$tools.sqlite.run()- 该方法允许执行数据库操作(INSERT、DROP 等),例如:
[% res = tools.sqlite.run('results/test.sqlite', 'INSERT INTO test VALUES(?)', 'test') %]
$tools.sqlite.all()- 该方法允许输出表中的所有数据,例如:
[% res = tools.sqlite.get('results/test.sqlite', 'SELECT * FROM test') %]
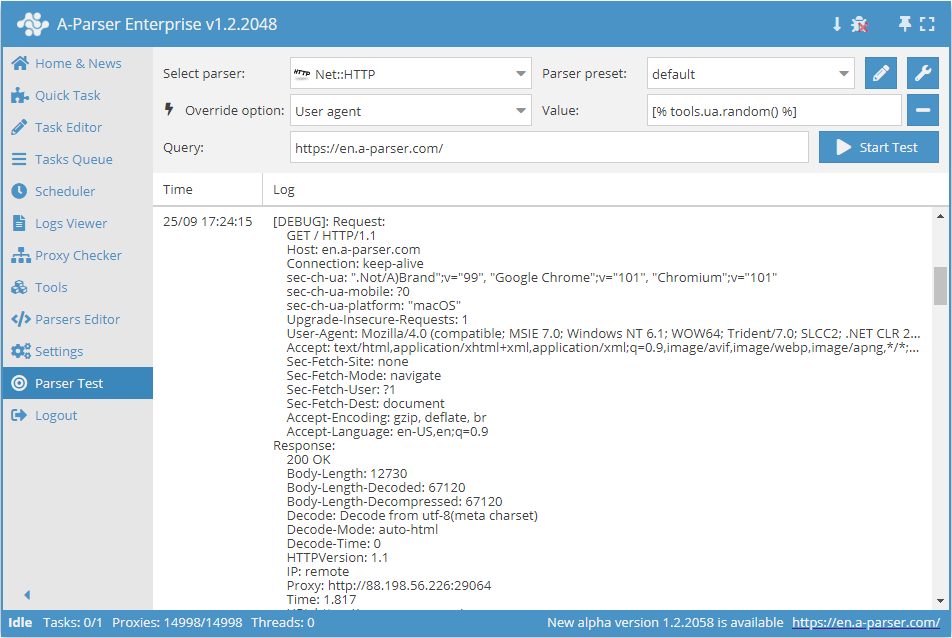
替换 user-agent $tools.ua.*
此工具旨在为使用 User-Agent 的爬虫工具(例如  Net::HTTP)提供 User-Agent 替换功能。共有两种方法:
Net::HTTP)提供 User-Agent 替换功能。共有两种方法:
$tools.ua.list()- 包含所有可用 User-Agent 的完整列表。$tools.ua.random()- 从可用 User-Agent 中随机输出一个。
使用示例:
所有 User-Agent 的列表存储在 files/tools/user-agents.txt 文件中,必要时可以进行编辑。
在爬虫工具中为 User agent 参数使用此工具时,必须明确指定:
[% tools.ua.random() %]
tools 中的 JS 支持 $tools.js.*
该工具允许添加自定义 JS 函数并直接在模板引擎中使用。同时支持使用 Node.js 模块。 函数需在 Tools -> JavaScript Editor 中添加。
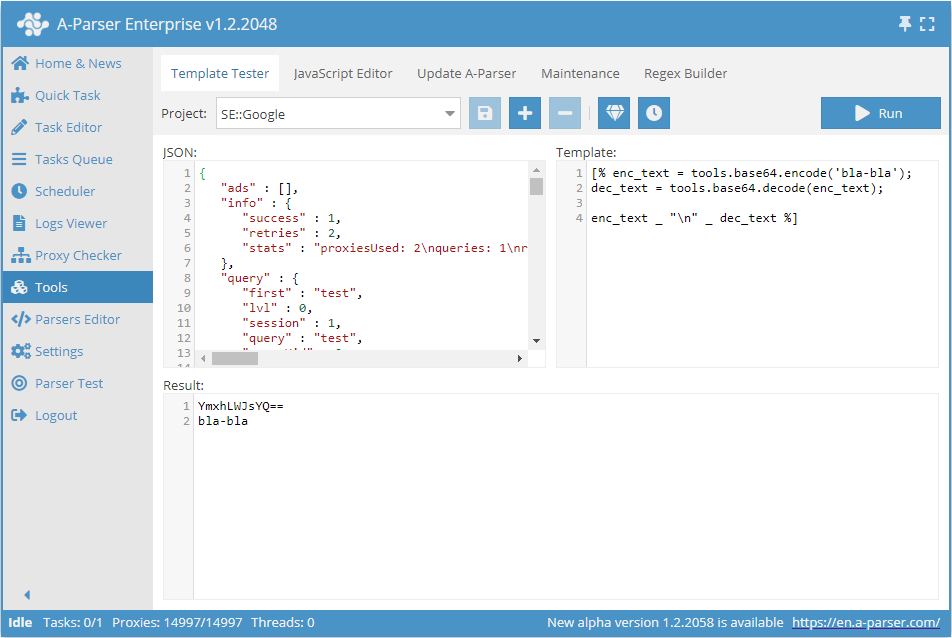
base64 处理 $tools.base64.*
该工具允许在爬虫工具中直接进行 base64 操作。该工具包含 2 个方法:
$tools.base64.encode()- 将文本编码为 base64$tools.base64.decode()- 将 base64 字符串解码为文本
使用示例:
数据参考手册 $tools.data.*
该工具本质上是一个包含大量预设信息的对象,如语言、地区、搜索引擎域名等。完整元素列表(未来可能会有变动):
"YandexWordStatRegions", "TopDomains", "CountryCodes", "YahooLocalDomains", "GoogleDomains", "BingTranslatorLangs", "Top1000Words", "GoogleLangs", "GoogleInterfaceLangs", "EnglishMonths", "GoogleTrendsCountries"
每个元素都是一个数据数组或哈希,可以通过输出数据(例如输出为 JSON)来查看内容:
[% tools.data.GoogleDomains.json() %]
内存数据存储 $tools.memory.*
内存中的简单键/值(key/value)存储,由所有任务、API 请求等共享,在 A-Parser 重启时清空。共有三个方法:
[% tools.memory.set(key, value) %]- 为键key设置值value[% tools.memory.get(key) %]- 返回键key对应的值[% tools.memory.delete(key) %]- 从内存中删除键key对应的记录
获取 A-Parser 版本信息 $tools.aparser.version()
该工具允许获取 A-Parser 的版本信息并将其输出到结果中。
使用示例:
[% tools.aparser.version() %]
获取任务 ID 和线程数 $tools.task.*
该工具允许获取任务 ID 信息并显示线程数。 共有两个方法:
[% tools.task.id %]- 返回任务 ID[% tools.task.threadsCount %]- 返回任务中使用的线程数量
停止任务 $tools.task.stop()
该工具允许随时停止任务的执行。它接受一个字符串作为参数,该字符串应包含停止任务的原因。
使用示例:
[% IF query.num == 3;
tools.task.stop('Stop after 3 queries');
END %]