常见问题解答
1. 关于演示、付款和购买的问题
1.1. 如何在 Demo 版本中下载结果?
在 Demo 版本中,抓取结果不可下载。我们根据您的要求提供结果。请发送您的查询并说明您感兴趣的爬虫工具,我们将向您发送结果(在演示范围内数量有限)。
1.3. 在哪里以及如何支付代理费用?
购买许可证时,会为您提供赠送代理。
Lite - 20 线程,有效期 2 周;Pro 和 Enterprise - 50 线程,有效期一个月。
您可以在 会员中心 的“商店”选项卡下的“代理”子栏目中购买更多线程或续费。
1.4. 你们能收费帮我配置任务吗?
有关 A-Parser 运行的技术支持是免费提供的。关于付费协助编写任务,可以联系这里:付费任务编写服务、设置协助和 A-Parser 使用培训。
1.5. 我可以通过 Privat24 银行或 KIWI 付款购买爬虫工具吗?
我们支持的支付系统列表请见此处:购买 A-Parser。
1.6. 如果我只想抓取百度索引页面的数量,买哪个爬虫工具比较好?
对于此类目的,Lite 版本就足够了,但 Pro 版本在工作中更实用且更灵活。
1.7. 在哪里查看我的许可证信息?
1.8. 购买的代理可以在多个 IP 上使用吗?
不可以。
2. 关于安装、启动和更新的问题
2.2. 购买了 Enterprise 版本,但安装的仍然是 PRO。该怎么办?
请卸载之前的版本。在 Members Area 检查您的 IP 地址是否填写正确。下载前请点击 Update (更新) 按钮。下载更新的版本。更多详情请见 安装说明。
2.4. 如果我是动态 IP 地址该怎么办?
没关系,A-Parser 支持动态 IP 地址。只需在每次 IP 变更时,在 Members Area 中重新填写即可。为了避免这些操作,建议使用静态 IP 地址。
2.5. 安装爬虫工具的服务器或电脑的最佳参数是什么?
所有系统要求都可以在这里查看:系统要求。
2.6. 启动了任务。爬虫工具崩溃且无法再次启动,该怎么办?
需要停止服务器,检查内存中是否仍有进程残留,然后尝试再次启动。也可以尝试在停止所有任务的情况下启动 A-Parser。为此,启动时需带上参数 -stoptasks。带参数启动的详情。
2.7. 打开地址 127.0.0.1:9091 时应输入什么密码?
如果是第一次启动,则密码为空。如果不是第一次,则是您设置的密码。如果忘记密码 - 重置密码。
2.8. 在会员中心输入我的 IP,但“您的当前 IP”字段没有变化。为什么?
Your current IP (您的当前 IP) 字段显示的是您目前生效的 IP,它不应该改变。您应该将其填入 IP 1 字段中。
2.10. 爬虫工具是否绑定硬件?
没有。使用您的 IP 来控制许可证。
2.11. 关于更新的问题 - 只更新 .exe 吗?config/config.db 和 files/Rank-CMS/apps.json - 这些文件是做什么用的?
除非另有说明,否则仅更新 .exe。第一个文件用于存储 A-Parser 配置,第二个文件是用于识别 CMS 的数据库,也是爬虫工具 ![]() Rank::CMS 运行所必需的。
Rank::CMS 运行所必需的。
2.12. 我使用的是 Win Server 2008 Web Edition - 爬虫工具无法启动...
A-Parser 无法在该版本的操作系统上运行。唯一的办法是更换操作系统。
2.13. 我有 4 核处理器。为什么 A-Parser 只使用一个核心?
A-Parser 使用 2 到 4 个核心,额外的核心仅在过滤、结果构造器、Parse custom result 时使用。
2.14. 我开始出现段错误 (segmentation failed, segmentation error)。该怎么办?
很可能是您的 IP 发生了变化。请在 会员中心 检查。
2.15. 我使用的是 Linux。A-Parser 已启动,但在浏览器中无法打开。如何解决?
请检查防火墙 - 很可能是它阻止了访问。
2.16. 我使用的是 Windows 7。A-Parser 已启动,但在浏览器中无法打开,且任务管理器中没有 Node.js 进程。如何解决?
需要检查 Windows 更新并安装最新的可用更新。具体需要 Windows 7 SP1 更新。
2.17. A-Parser 无法启动,aparser.log 中记录了错误 FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20。
很可能是某个任务(文件夹 /config/tasks/)出现了问题,原因是磁盘错误(例如电脑在未正常关机的情况下断电),更多详情可以通过带 -morelogs 标志启动 A-Parser 来了解。
解决方案:带参数 -stoptasks 启动 A-Parser。如果没有帮助,请清理整个 /config/tasks/。如果之后问题仍未解决,请将爬虫工具重新安装到新目录,并放入旧的配置文件(如果未损坏)。
3. 关于 A-Parser 设置及其他设置的问题
3.1. 如何设置代理检查器?
详细说明请见此处:代理设置。
3.2. 没有可用的代理 - 为什么?
请检查您的互联网连接以及代理检查器的设置是否正确。如果一切设置正确,则意味着目前您的代理列表中没有可用的服务器。解决此问题的方法:要么使用其他代理,要么稍后重试。 如果您使用的是我们的代理,请在 会员中心 的 Proxies (代理) 部分检查 IP 地址。此外,也有可能是您的运营商屏蔽了对其他 DNS 的访问,请尝试执行此处描述的步骤:http://a-parser.com/threads/1240/#post-3582
3.3. 如何连接打码平台?
3.4. 我更改了爬虫工具设置中的参数,但没有生效。为什么?
默认预设 (default) 无法修改,如果进行了任何更改,需要点击 Save as New Preset (另存为新预设),然后在您的任务中使用它。
3.5. 可以更改正在运行的任务的设置吗?
可以,但不是全部。在运行中的任务中,可以点击暂停,然后在下拉菜单中选择 Edit (编辑)。
3.6. 如何导入预设?
点击 任务编辑器 中任务选择字段旁的按钮。详情见此。
3.7. 如何设置爬虫工具使其不使用代理?
在所需爬虫工具的设置中取消勾选 Use proxy。
3.8. 我没有“添加重写 / Override option”按钮!
该选项可以直接在 任务编辑器 中添加。爬虫工具选项。
3.9. 如何覆盖保存到同一个结果文件?
在创建任务时设置 Overwrite file (覆盖文件) 选项。
3.10. 在哪里更改爬虫工具的密码?
3.11. 我放了 600 万个关键词进行抓取,并指定域名全部唯一。如何做到当我放入新的 600 万个关键词时,只记录与之前抓取不重复的唯一域名?
在创建第一个任务时需要使用 Keep unique (保存去重状态) 选项,并在第二个任务中指定保存的数据库。详情见任务编辑器附加选项。
3.12. 如何绕过谷歌 1000 条结果的限制?
请使用 抓取所有结果 / Parse all results 选项。
3.13. 如何绕过 Linux 上 1024 个线程的限制?
3.14. Windows 上的线程限制是多少?
最高支持 10000 线程。
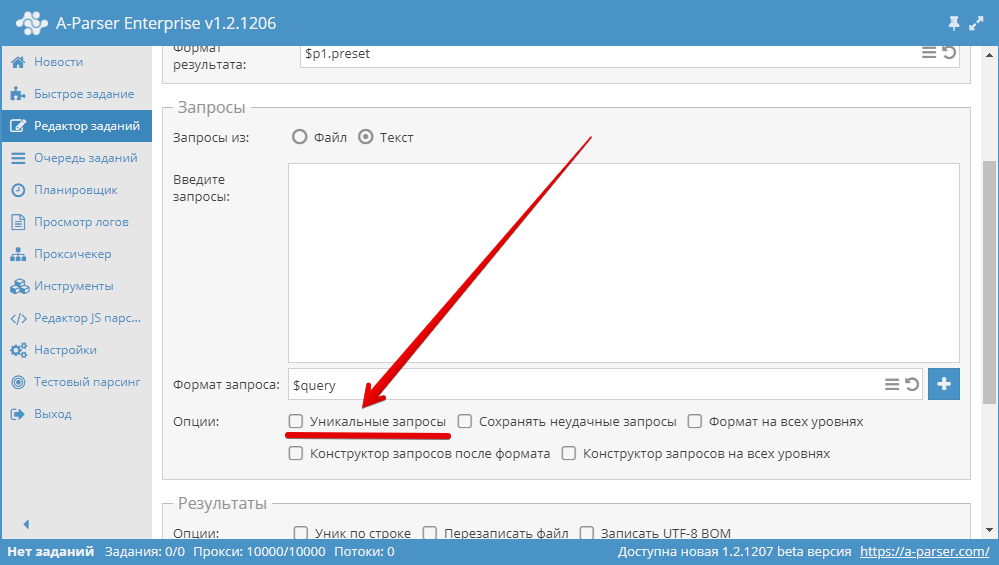
3.15. 如何使查询唯一?
在 Unique queries (任务编辑器) 的 Queries (查询) 模块中使用 查询去重 选项。
3.16. 如何关闭代理检查?
在 设置 - 代理检查器设置 中选择所需的代理检查器并勾选 No check proxies (不检查代理)。保存并选择保存的预设。
3.17. 什么是 Proxy ban time?我可以将其设置为 0 吗?
代理封禁时间(以秒为单位)。是的,您可以设置为 0。
3.18. 爬虫工具  SE::Google::Position 中的 Exact Domain 和 Top Level Domain 有什么区别?
SE::Google::Position 中的 Exact Domain 和 Top Level Domain 有什么区别?
Exact Domain 是严格匹配,即如果搜索结果是 www.domain.com,而我们搜索的是 domain.com,则不会匹配。Top Level Domain 校验整个顶级域名,即此处会匹配。
3.19. 如果运行测试抓取一切正常,但普通抓取时收到 Some error 错误。
很可能是 DNS 问题,请尝试执行此 DNS 设置说明。
3.20. 在哪里设置结果格式?
在 格式化结果 时使用 \n。示例:
3.21. 在  SE::Google 中没有荷兰语,尽管在谷歌设置中有。为什么?
SE::Google 中没有荷兰语,尽管在谷歌设置中有。为什么?
荷兰语即 Dutch,它在列表中。详情请参阅关于添加荷兰语的改进。
4. 关于数据抓取及抓取过程中错误的问题
4.1. 什么是线程?
所有现代处理器都可以多线程执行任务,这显著提高了执行速度。打个比方,普通巴士在单位时间内运送一定数量的人——这是普通的单线程处理;而双层巴士在相同时间内运送两倍的人——这就是多线程处理。A-Parser 最多可同时处理 10000 个线程。
4.2. 任务无法启动 - 显示 Some Error - 为什么?
请在会员中心检查 IP 地址。
4.3. 所有查询都进入失败状态,该怎么办?
很可能是任务设置不正确或使用了错误的查询格式。此外,请检查是否有可用的代理。还可以尝试增加 Request retries 选项(详情见:失败的请求)。
4.4. 使用  SE::Yandex::Wordstat 抓取 1,000,000 个关键词需要注册多少个账号?
SE::Yandex::Wordstat 抓取 1,000,000 个关键词需要注册多少个账号?
无法准确说出需要多少个账号,因为账号可能会在未知数量的请求后失效。但您始终可以使用爬虫工具  SE::Yandex::Register 注册新账号,或者直接将现有账号添加到文件 files/SE-Yandex/accounts.txt 中。
SE::Yandex::Register 注册新账号,或者直接将现有账号添加到文件 files/SE-Yandex/accounts.txt 中。
4.5. 任务无法启动,显示 Error: Lock 100 threads failed(20 of limit 100 used),该怎么办?
需要在爬虫工具设置中提高最大可用线程数,或者在任务设置中降低线程数。详情见设置。
4.6. 可以同时运行 2 个任务吗?
是的,A-Parser 支持同时执行多个任务。同时运行的任务数量在设置 - 常规设置:最大活动任务数中进行调节。
4.7. 结果文件在哪里?
在Tasks Queue (任务队列)选项卡中,每个任务结束后,您可以下载工作结果。物理文件位于 results 文件夹中。
4.8. 如果抓取未完成,可以下载结果文件吗?
不,在数据抓取完成之前,无法下载结果。但在任务停止或暂停时,可以从 aparser/results 文件夹中复制结果。
4.9. 你们的爬虫工具可以针对一个查询抓取 1,000,000 个链接吗?
是的,可以使用 抓取所有结果 / Parse all results 选项。
4.10. 是否可以在不使用代理的情况下运行  Rank::CMS、
Rank::CMS、 Net::Whois?
Net::Whois?
Net::Whois - 不建议。4.11. 如何从谷歌抓取链接?
需要使用 SE::Google。
4.12. 爬虫工具可以访问链接吗?
是的,爬虫工具  HTML::LinkExtractor 在使用 抓取层级 / Parse to level 选项时可以实现此功能。
HTML::LinkExtractor 在使用 抓取层级 / Parse to level 选项时可以实现此功能。
4.13. 谷歌抓取速度非常慢,该怎么办?
首先需要查看任务日志,可能所有请求都失败了。如果是这样,需要找到请求失败的原因并修复。在使用 SE::Google 进行数据抓取时,日志中经常出现失败尝试,这通常与谷歌显示验证码有关,这是正常的。您可以连接 Antigate 来绕过验证码,以免爬虫工具不断重试。
此外,还有一篇文章描述了影响数据抓取速度的因素及其影响方式:爬虫工具的速度和工作原理。
4.14. 你们的爬虫工具可以抓取文本仅为日语的链接吗?
是的,为此需要在爬虫工具设置中设置所需的语言,并使用日语关键词。
4.15. 你们的爬虫工具可以只抓取 .de 或 .ru 域名后缀的链接吗?
是的。为此需要使用过滤器。
4.16. 如何使文件中的每个结果都从新行开始?
在格式化结果时使用 \n。示例:
$serp.format('$link\n')
4.17. 如何从谷歌抓取前 10 名网站?
这是预设:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. 我添加了任务,切换到“任务队列”选项卡 - 但它不在那里!为什么?
要么是创建任务时出错了,要么是任务已经执行完毕并转入Completed (已完成)。
4.19. 提示文件不是 utf-8,但我没改过它,它本来就是 utf-8,该怎么办?
请再次检查。此外,请尝试更改编码,例如使用 Notepad++。
4.20. 结果文件中所有内容都在一行,尽管我在任务中设置了换行 - 为什么?
在 A-Parser 附加设置 中需要使用换行符 CRLF (Windows)。
但如果您已经在没有此选项的情况下完成了抓取,请使用更高级的查看器(如 Notepad++)进行查看。
4.21. 检查 1,000 个查询在百度上的词频需要多少时间?
该指标很大程度上取决于任务参数、服务器配置、代理质量等,因此无法给出明确的答案。
4.22. 我该如何设置爬虫工具,使结果为“查询-链接”格式?
结果格式:
$p1.serp.format('$query: $link\n')
结果将是:
查询: 链接 1
查询: 链接 2
查询: 链接 3
4.23. 我该如何重新抓取失败的查询,它们存储在哪里?
为了保存失败的请求,应在Queries (任务编辑器)的查询区块中选择相应选项。失败的请求存储在 queries\failed 中。需要创建一个新任务,并将失败请求的文件指定为查询文件。
4.24. 抓取文本时如何去除 HTML 标签?
请使用结果构造器中的 Remove HTML tags 选项。
4.25. 如何做到只抓取域名?
请使用结果构造器中的 Extract Domain 选项。
4.26. 爬虫工具可以使用多大的查询文件?
查询文件和结果文件的大小不受限制,可以达到 TB 级别。
4.27. 为什么当我在查询字段输入文本时,爬虫工具提示 Queries length limited to 8192 characters?
这是因为查询长度限制为 8192 个字符。要使用更长的查询,请使用文件作为查询来源。
4.28. “等待线程 - 3”是什么意思?
这意味着代理不足。请减少线程数,或增加代理数量。
4.29. 测试抓取时提示 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) 且不抓取,为什么?
这表明代理不可用。
4.30. 谷歌爬虫工具中结果语言和搜索国家有什么区别?
区别如下:搜索国家是将结果绑定到特定国家。例如,如果你在特定国家范围内搜索购买窗户,那么优先显示的会是那些在该国家提供购买窗户服务的网站。而结果语言则是结果应以哪种语言显示。
4.31. 我无法抓取某个特定网站。可能是什么原因?
问题通常在于服务器端因 User-Agent 过旧而导致封锁。 可以通过使用新的 User-Agent 或在 User agent 参数中使用以下代码来解决:
[% tools.ua.random() %]
4.32. 爬虫工具卡死、退出。日志中出现 syswrite: No space left on device
A-Parser 硬盘空间不足。请释放更多空间。
4.34. 经常弹出显示 Failed fetch news 的窗口
4.35. 如何输出搜索结果的前 n 个结果?
4.36. 如何追踪重定向链?
4.37. 如何检查链接在来源页是否被索引?
为此目的,有一个专门的爬虫工具: Check::BackLink。
详情见讨论。
Check::BackLink。
详情见讨论。
4.38. 爬虫工具在 Linux 上退出。日志中有此类记录:EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
很可能需要调整线程数,如文档:为更多线程优化 Linux中所述。
4.39. 在哪里可以查看所有可通过 API 使用的参数?
此外,还可以生成 JSON 格式的完整任务配置。为此需要获取任务代码并对其进行 base64 解码。
4.40. 我使用  Net::HTTP 下载图片,但它们不知为何都是损坏的。该怎么办?
Net::HTTP 下载图片,但它们不知为何都是损坏的。该怎么办?
1) 检查 Max body size 参数 - 可能需要增大它。 2) 在 A-Parser 设置中检查换行符格式:附加设置 - 换行符。
为了确保图片不损坏,必须使用 UNIX 格式。
4.41. 如何从 WHOIS 获取管理员联系方式?
此类任务可以通过 Parse custom result 功能和正则表达式轻松解决。详情见讨论。
4.42. 抓取电话号码的正则表达式
4.43. 识别没有移动版的网站
4.44. 如何获取 NS 服务器名称?
4.45. 如何抓取百度快照链接?
4.46. 如何抓取网站所有页面的链接?
4.47. 如何从页面抓取 title?
4.48. 如何抓取指定域名后缀下的所有网站?
4.49. 如何收集所有带参数的 URL?
4.50. 如何按多个特征过滤结果并在报告中按其分类?
4.51. 如何简化过滤器结构?
4.52. 如何根据结果进行文件分类?
4.53. 每 X 个文件创建一个新的结果目录
4.54. WordStat 使用初步
4.55. 收集 >1000 字符的文本块
4.56. 从页面输出指定数量的文本
这也可以通过 Template Toolkit 解决。详情见讨论。
4.57. 在谷歌中检查竞争度和标题包含情况
4.58. 按查询在锚点和描述中的出现次数进行过滤
4.59. 如何将文章内容提取为一行?
4.60. 如何比较两个字符串日期?
4.61. 如何抓取描述中的高亮词汇?
4.62. 使用多个爬虫工具的任务示例
4.63. 如何打乱结果行顺序以及如何输出随机数量的结果?
4.64. 如何使用 MD5 对结果进行签名?
4.65. 如何将 Unix 时间戳转换为字符串表示形式?
4.66. Parse to level,如何进行带限制的抓取?
4.67. 爬虫工具在 Linux 上启动任务时崩溃。日志中有此类行:Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
需要在控制台中执行命令:
apt-get --reinstall --purge install netbase
4.68. 错误 Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
需要以非 root 用户身份运行 A-Parser。具体操作:由 root 用户创建一个没有 root 权限的新用户(如果已有则直接使用),然后允许该用户操作 A-Parser 目录,接着以新用户身份登录并运行。
在 root 用户下创建用户,可以参考此指南。
为了允许创建的用户操作 A-Parser 目录,需要赋予该用户权限。为此,以 root 用户身份进入并使用命令赋予权限:
chown -R user:user aparser
4.69. 错误 Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
在 root 用户下执行命令:
sysctl -w kernel.unprivileged_userns_clone=1
不需要重启 A-Parser。
对于 CentOS 7,解决方案见此主题。
在 root 用户下执行命令:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
然后使用命令重启 sysctl:
sysctl -p
4.70. 错误 JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
错误是由于操作系统中缺少 Chrome 运行所需的库引起的。
Chrome 运行所需的库列表可以在 Chrome headless doesn't launch on UNIX 中找到。
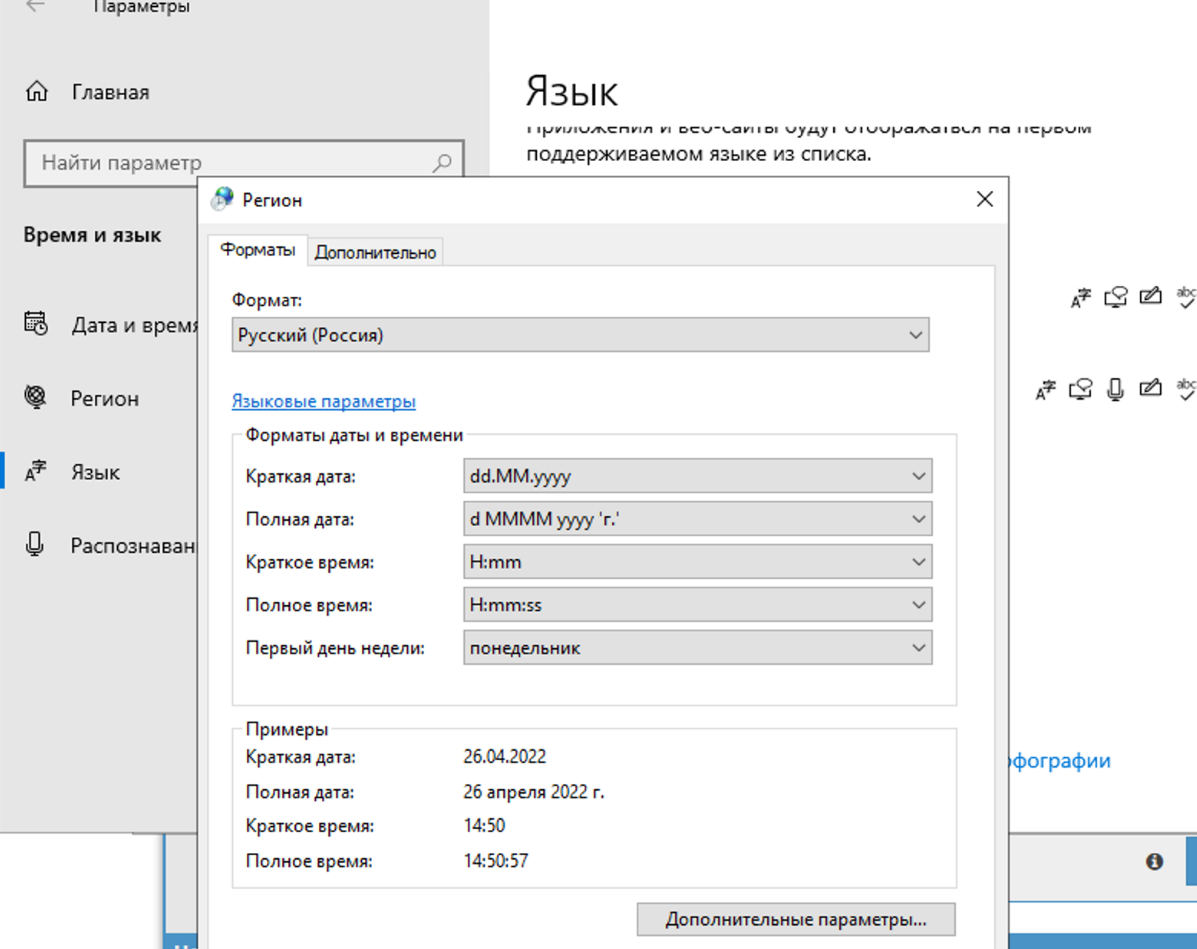
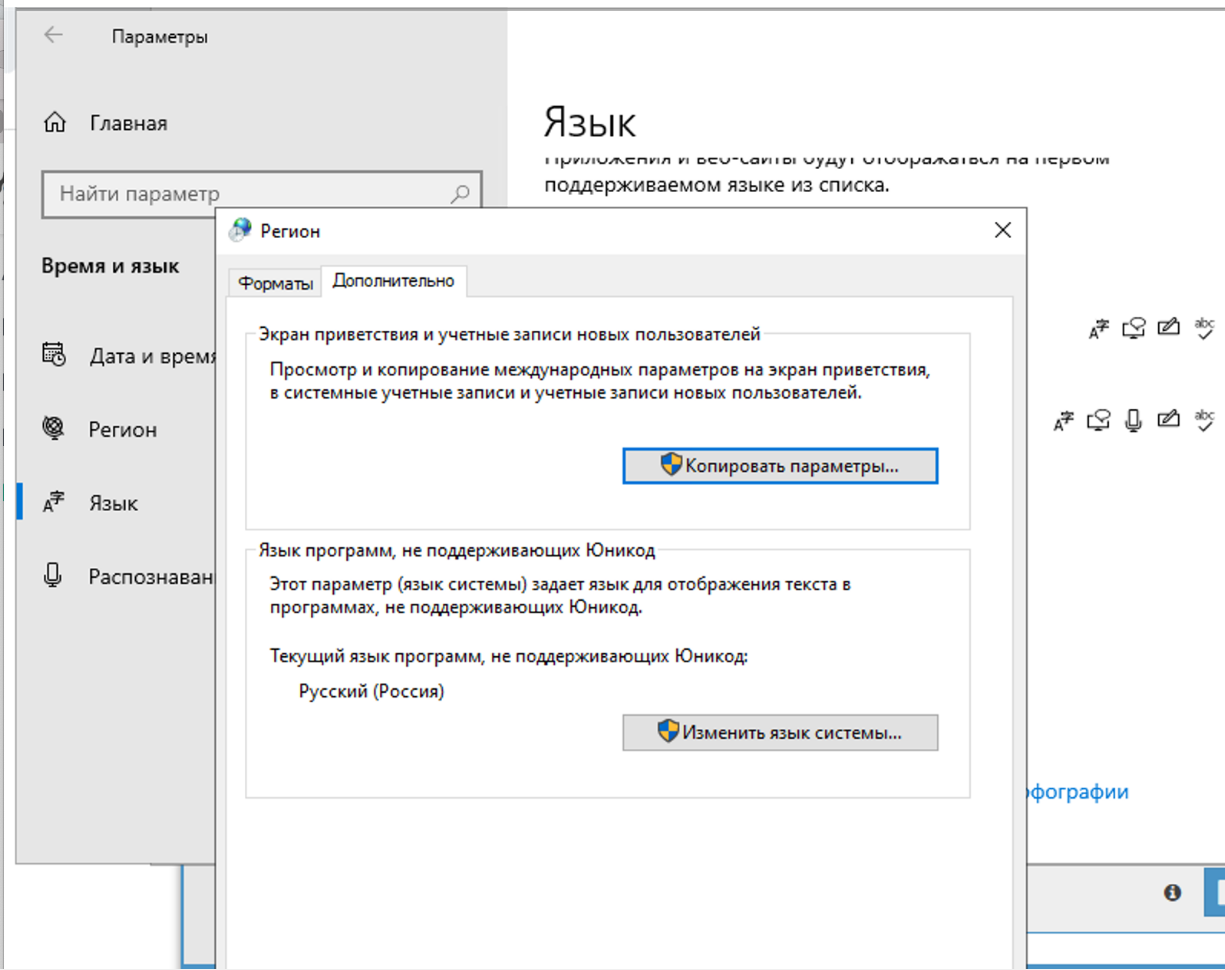
4.71. 为什么验证码无法识别?日志显示 A-Parser 从 Xevil 收到的是问号而不是验证码答案
在区域设置中需要更改为俄语。
只需在“高级”选项卡中更改。这不影响验证码识别,但如果两处都改了,Xumer 本身会出现编码问题。