设置
A-Parser 包含以下设置组:
- Global Settings - 程序的主要设置:语言、密码、更新参数、活动任务数量
- Config Presets - 任务的线程设置和结果去重方法
- Parser Presets - 可以配置每个单独的爬虫工具
- 代理检查器设置 - 代理检查器的线程数和所有设置
- Advanced Settings - 面向高级用户的可选设置
- Task presets - 保存任务以供后续使用
所有设置(常规设置和附加设置除外)都保存在所谓的预设中——即预先保存的一组设置,例如:
- 爬虫工具
 SE::Google 的不同设置预设 - 一个用于抓取链接,最大深度为 10 页;另一个用于评估查询竞争程度,抓取深度为 1 页
SE::Google 的不同设置预设 - 一个用于抓取链接,最大深度为 10 页;另一个用于评估查询竞争程度,抓取深度为 1 页 - 代理检查器的不同设置预设 - 分别用于 HTTP 和 SOCKS 代理
所有设置都存在一个默认预设 (default),该预设无法修改,所有更改都必须保存到具有新名称的预设中。
常规设置
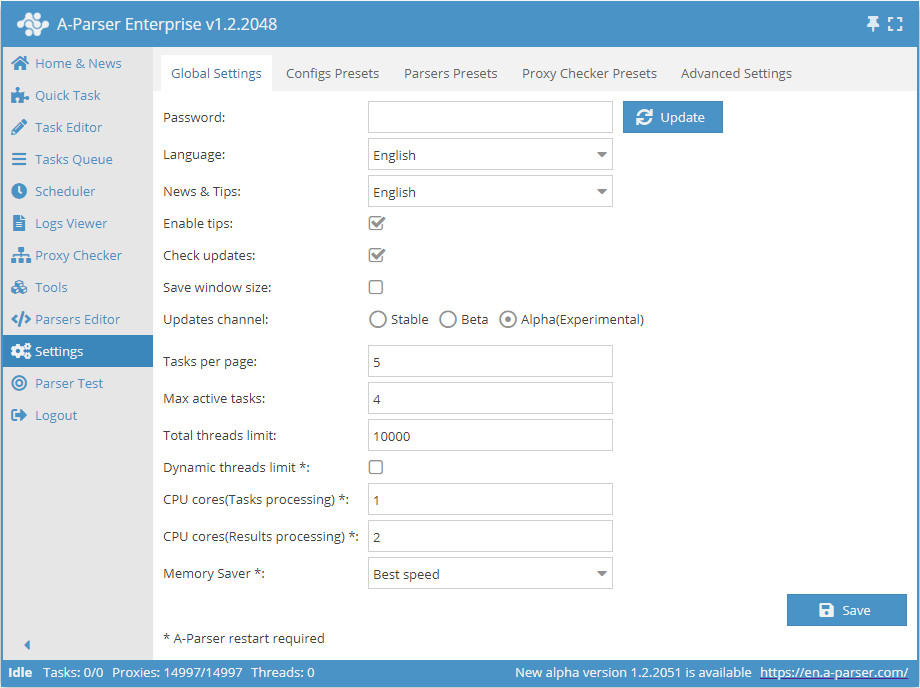
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Password | 无密码 | 设置登录 A-Parser 的密码 |
| Language | English | 界面语言 |
| News & Tips | English | 新闻和提示的语言 |
| Enable tips | ☑ | 确定是否显示提示 |
| Check updates | ☑ | 确定是否在 状态栏 中显示新版本可用信息 |
| Save window size | ☐ | 确定是否保存窗口大小 |
| Updates channel | Stable | 选择更新频道(稳定版、Beta、Alpha) |
| Tasks per page | 5 | 任务队列中每页显示的任务数量 |
| Max active tasks | 1 | 最大同时活动任务数量 |
| Total threads limit | 10000 | A-Parser 中的总线程限制。如果总线程限制小于任务中的线程数,任务将无法启动 |
| Dynamic thread limit | ☐ | 确定是否使用 动态线程限制 |
| CPU cores (task processing) | 2 | 支持在不同的 CPU 核心上处理任务(仅限 Enterprise 许可证)。详情见下文 |
| CPU cores (result processing) | 4 | 多核心仅用于过滤、结果构造器、解析自定义结果(所有许可证类型) |
| Memory Saver | Best speed | 允许定义爬虫工具可以使用多少内存(Best speed / Medium memory usage / Save max memory)。详情... |
CPU 核心(任务处理)
支持在不同的 CPU 核心上处理任务,此功能仅限 Enterprise 许可证可用
此选项可(成倍地)加速队列中多个任务的处理(Settings -> Max active tasks),但不会加速单个任务的执行
还实现了基于每个进程 CPU 负载的智能任务分配到工作核心 使用的 CPU 核心数量在设置中指定,默认为 2,最大为 32
与线程的情况一样,最好通过实验来选择核心数,对于 4 核处理器,合理的值为 2-3 个核心,对于 8 核处理器为 4-6 个等。需要考虑到,如果核心数量较多且负载较高,主管理进程 (aparser/aparser.exe) 可能会出现 100% 的负载,此时进一步增加任务处理进程只会导致整体变慢或运行不稳定。还需要考虑到,每个任务处理进程可能会产生高达 300% 的额外负载(即同时让 3 个核心各负载 100%),这一特性与 JavaScript v8 引擎中的多线程垃圾回收处理有关
线程设置
A-Parser 的工作基于 多线程数据处理 原理。爬虫工具在独立的线程中并行执行任务,线程数量可以根据服务器配置灵活调整。
线程工作原理说明
让我们通过实际案例来了解什么是线程。假设您需要编制一份三个月的报告。
方案 1
您可以先编制第 1 个月的报告,然后是第 2 个月,最后是第 3 个月。这是单线程工作的例子。任务按顺序解决。
方案 2
聘请三名会计师,每人负责编制一个月的报告。然后在收到三人的结果后,再制作总报告。这是多线程工作的例子。任务同时解决。
从这些例子可以看出,多线程工作可以更快地完成任务,但同时也需要更多资源(我们需要 3 名会计师而不是 1 名)。 多线程在 A-Parser 中的工作方式类似。假设您需要从多个链接抓取信息:
- 在单线程模式下,应用程序将依次抓取每个网站
- 在多线程模式下,每个线程将处理自己的链接,完成后将开始处理列表中下一个未处理的链接
因此,在第二种方案中,整个任务将显著加快完成,但同时需要更多的服务器资源,因此建议遵守 系统要求
线程设置
A-Parser 中的线程设置是针对每个任务单独配置的,具体取决于执行所需的参数。默认提供 2 种线程配置:20 和 100 线程,分别对应 default 和 100 Threads。
要进入所选配置的设置,需要点击铅笔图标 ![]() ,之后将打开其设置。
,之后将打开其设置。 
也可以通过菜单项进入线程设置:Settings -> Config Presets
在这里我们可以:
- 创建具有自己设置的新配置并以自己的名称保存(“添加新配置”按钮)
- 对现有配置进行更改,从下拉列表中选择它(“保存”按钮)
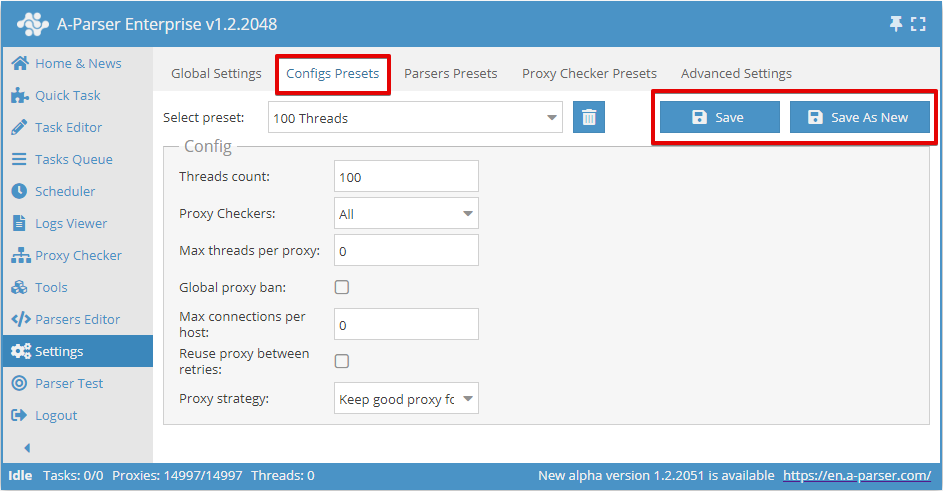
线程数 (Threads count)
此参数设置使用该配置启动的任务将运行的线程数量。线程数可以是任意的,但需要考虑服务器的能力以及代理套餐的限制(如果有此类限制)。例如,对于我们的代理,指定的数量不能超过所选套餐的限制。
同样重要的是要记住,爬虫工具中的总线程数等于正在运行的任务与启用了代理检查的代理检查器线程数之和。例如,如果启动了一个 20 线程的任务和两个各 100 线程的任务,同时运行一个启用了 15 线程代理检查的代理检查器,那么爬虫工具总共将使用 20+100+100+15=235 个线程。此时,如果代理套餐限制为 200 个线程,则会出现大量失败请求。为了避免这种情况,需要降低使用的线程数。例如,关闭代理检查(如果不需要,这将节省 15 个线程)并将其中一个任务的线程数再降低 20 个。因此,对于其中一个运行中的任务,需要创建一个 80 线程的配置,其他保持不变
代理检查器 (Proxy Checkers)
此参数允许选择具有特定设置的代理检查器。在这里可以选择 All 参数,这意味着使用所有运行中的代理检查器,或者仅选择任务中需要使用的代理检查器(支持多选)
此设置允许仅使用所需的代理检查器运行任务。代理检查器的设置过程在这里进行了讨论
每个代理的最大线程数 (Max threads per proxy)
这里设置同时使用同一个代理的最大线程数。允许设置不同的参数,例如 1 线程 = 1 代理的工作模式。
默认情况下,此参数为 0,即禁用此功能。在大多数情况下这已足够。但如果需要限制每个代理的负载,则有必要更改该值
全局代理封禁 (Global proxy ban)
所有使用此选项启动的任务共享一个代理封禁数据库。此参数的特点是,每个爬虫工具的被封禁代理列表对所有运行中的任务都是通用的。
例如,在任务 1 中被 SE::Google 封禁的代理,在任务 2 中也将被 SE::Google 封禁,但它在两个任务中仍可以正常用于  SE::Yandex
SE::Yandex
每个主机的最大连接数 (Max connections per host)
此参数指定每个主机的最大连接数,旨在减少抓取信息时对网站的负载。实际上,指定此参数可以控制每个特定域名在同一时刻的请求数量。启用此参数适用于任务,如果同时启动多个使用相同线程配置的任务,则限制将计入所有任务。
默认情况下,此参数的值为 0,即禁用。
重试间重复使用代理 (Reuse proxy between retries)
此设置禁用了每次重试时对代理唯一性的检查,同时代理封禁也将不起作用。这反过来意味着可以为所有重试使用 1 个代理。
建议在例如计划使用 1 个代理且每次连接时出口 IP 都会发生变化的情况下启用此参数。
代理使用策略 (Proxy strategy)
允许在使用会话时管理代理选择策略:为下一个请求保留成功请求中的代理,或始终使用随机代理。
建议
本文介绍了所有允许管理线程的设置。值得注意的是,在配置线程设置时,不一定要设置文中提到的所有参数,只需设置那些能确保获得正确结果的参数即可。通常只需更改 Threads count,其他设置可以保持默认。
爬虫工具设置
每个爬虫工具都有许多设置,并允许将不同的设置集保存到预设中。预设系统允许根据情况使用具有不同设置的同一个爬虫工具,以 SE::Google 爬虫工具为例:
预设 1:“抓取最大数量的链接”
- 页数 (Pages count):
10
这样,爬虫工具将通过浏览所有搜索结果页面来收集最大数量的链接
预设 2:“按查询抓取竞争程度”
- 页数 (Pages count):
1 - 结果格式 (Results format):
$query: $totalcount\n
在这种情况下,我们获取查询的搜索结果数量(查询竞争程度),为了获得更快的速度,我们只需抓取第一页即可
创建预设
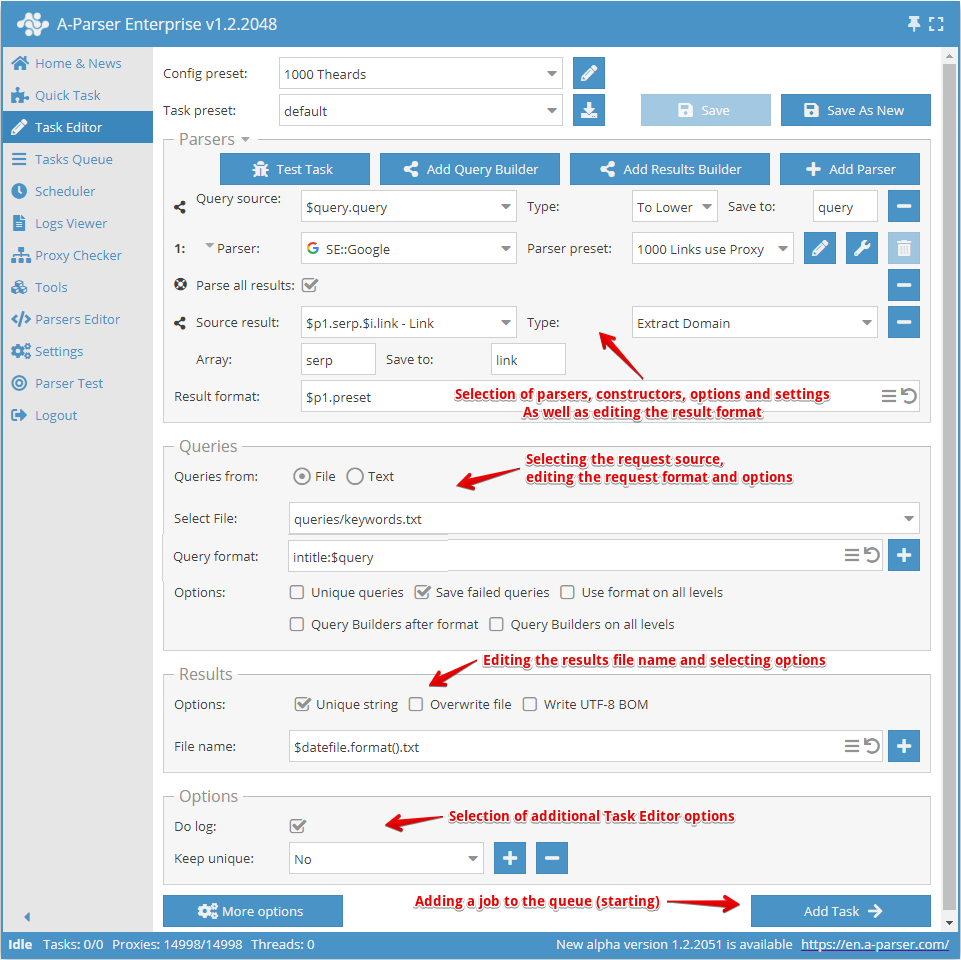
创建预设从选择爬虫工具并确定需要获得的结果开始。
接下来需要了解所选爬虫工具的输入数据是什么,在上面的截图中选择了 SE::Google 爬虫工具,它的输入数据是任何字符串,就像您在浏览器中搜索某些内容一样。可以选择查询文件或在文本框中输入查询。
现在需要重新定义爬虫工具的设置(选择选项),添加去重。如果需要处理查询,可以使用 查询构造器。或者如果需要以某种方式处理结果,可以使用 结果构造器。
接下来需要注意编辑结果文件名,如果需要,可以根据自己的判断进行更改。
最后一步是选择 额外选项,特别是 Do log (记录日志) 选项。如果您想了解数据抓取错误的原因,这非常有用。
完成所有这些后,需要保存预设并添加到任务队列中。
覆盖设置
Override preset - 快速覆盖爬虫工具的设置,此选项可以直接在 任务编辑器 中添加。一键即可添加多个参数。在设置列表中指出了默认值,如果选项以粗体显示,则表示它已在预设中被覆盖
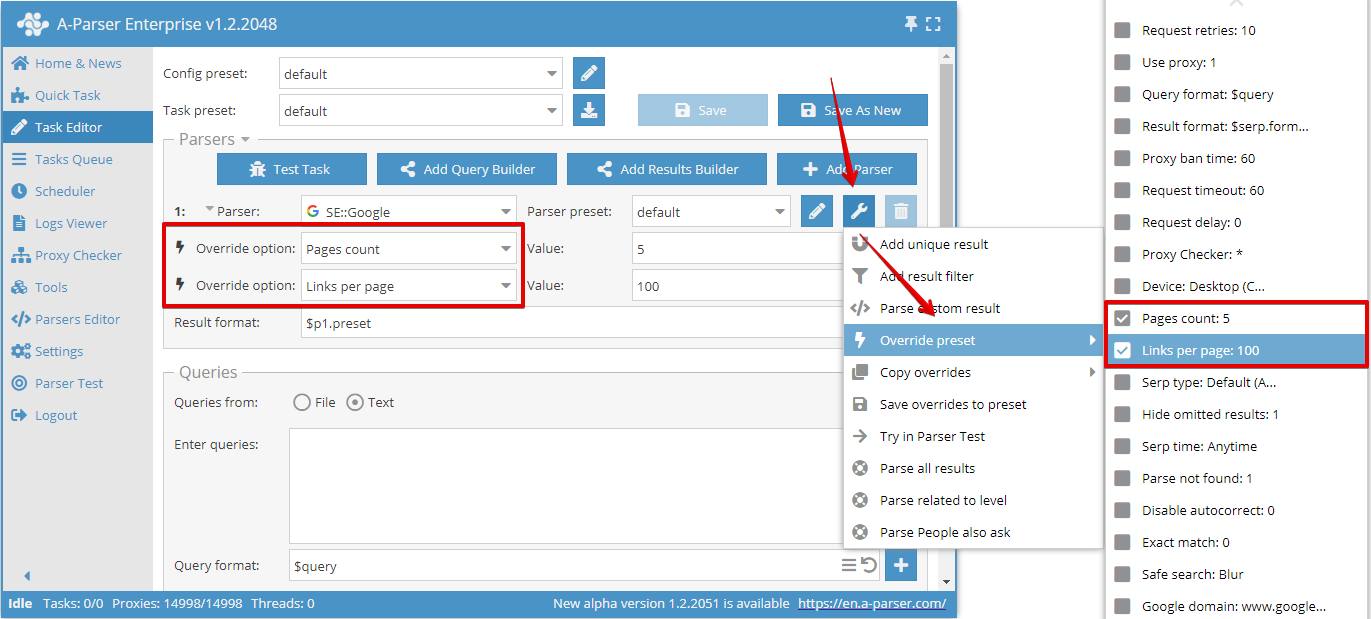
在此示例中,覆盖了 Pages count(页面数量)选项,并将其设为 5。
在任务中可以使用无限数量的 Override preset 选项,但如果更改较多,创建一个新预设并在其中保存所有更改会更方便。
也可以使用 Save overrides to preset (保存覆盖) 功能轻松保存覆盖设置。它们将作为所选爬虫工具的独立预设保存。
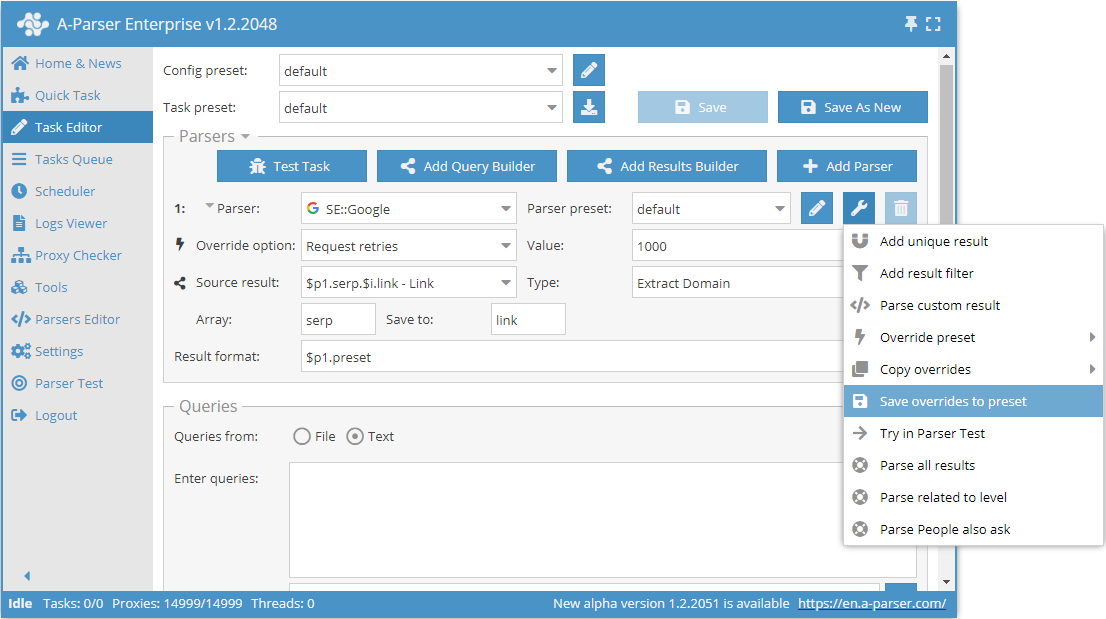
之后,将来只需从列表中选择此保存的预设并使用即可。
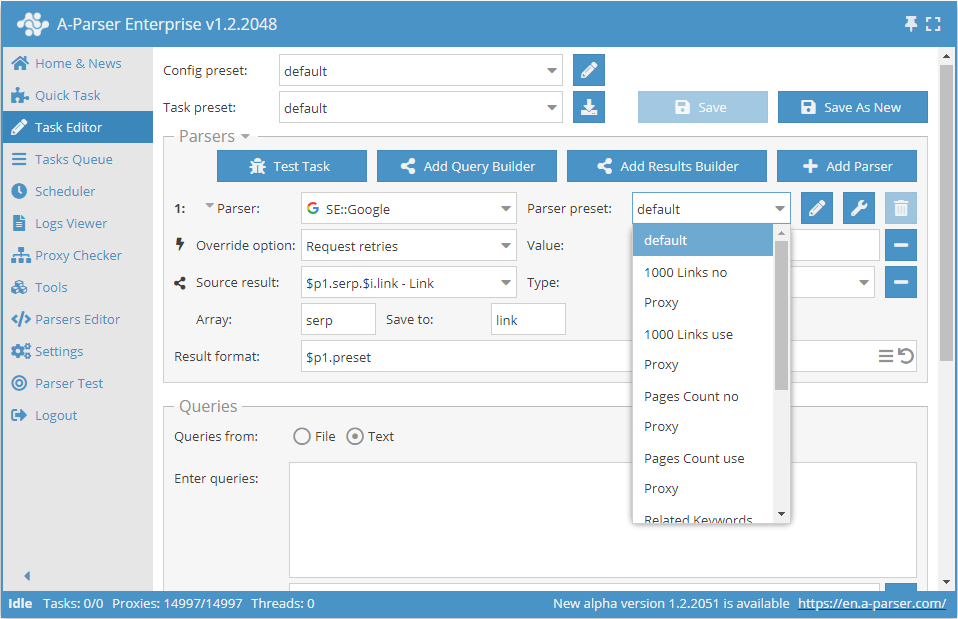
所有爬虫工具的通用设置
每个爬虫工具都有自己的一套设置,您可以在 相应章节 中找到每个爬虫工具的设置信息
在此表格中,我们展示了所有爬虫工具的通用设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Request retries | 10 | 每个请求的重试次数,如果请求在指定的重试次数内未能成功执行,则视为失败并跳过 |
| Use proxy | ☑ | 确定是否使用代理 |
| Query format | $query | 查询格式 |
| Result format | 每个爬虫工具都有自己的值 | 结果输出格式 |
| Proxy ban time | 每个爬虫工具都有自己的值 | 代理封禁时间(秒) |
| Request timeout | 60 | 最大请求等待时间(秒) |
| Request delay | 0 | 请求之间的延迟(秒),可以设置范围内的随机值,例如 10,30 - 延迟 10 到 30 秒 |
| Proxy Checker | All | 应使用哪些检查器的代理(在所有检查器之间选择或列出特定检查器) |
基于 HTTP 协议工作的所有爬虫工具的通用设置
| 参数名称 | 默认值 | 描述 |
|---|---|---|
| Max body size | 每个爬虫工具都有自己的值 | 结果页面的最大字节数 |
| Use gzip | ☑ | 确定是否对传输流量使用压缩 |
| Extra query string | 允许在查询字符串中指定额外参数 |
每个爬虫工具的默认设置可能不同。它们存储在每个爬虫工具设置的 default 预设中。
代理检查器设置
额外设置
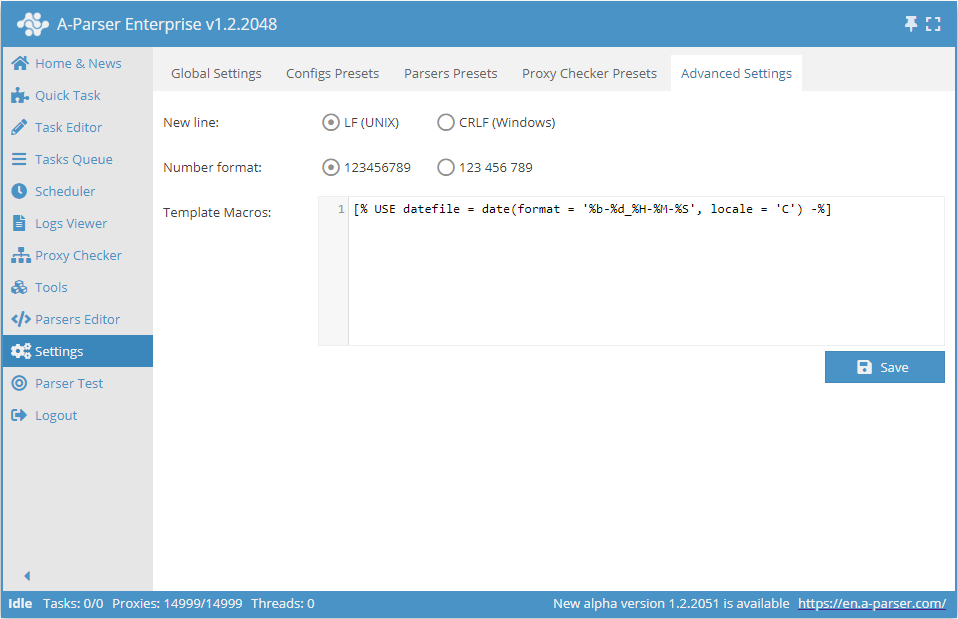
- 换行符允许在将结果保存到文件时选择 Unix 或 Windows 版本的行尾
- 数字格式 - 设置在 A-Parser 界面中如何显示数字
- 模板宏