Scraper in JavaScript: Panoramica delle funzionalità
Scraper JavaScript - offrono la possibilità di creare i propri scraper completi con una logica complessa a piacere, utilizzando il linguaggio JavaScript. Allo stesso tempo, negli scraper JS è possibile utilizzare anche tutte le funzionalità degli scraper standard.
Caratteristiche
Sfruttando tutta la potenza di A-Parser, ora è possibile scrivere il proprio scraper/reger/poster con una logica complessa a piacere. Per la scrittura del codice si utilizza JavaScript con le funzionalità di ES6 (motore v8).
Il codice degli scraper è estremamente sintetico, permettendo di concentrarsi sulla scrittura della logica; A-Parser si occupa della gestione del multithreading, della rete, dei proxy, dei risultati, dei log, ecc. Il codice può essere scritto direttamente nell'interfaccia dello scraper, aggiungendo un nuovo scraper nell'Editor degli scraper. Inoltre, per scrivere gli scraper è possibile utilizzare editor esterni, come ad esempio VSCode.
Viene utilizzato il versionamento automatico al salvataggio del codice dello scraper tramite l'editor integrato.
Il lavoro con gli scraper JavaScript è disponibile per le licenze Pro e Enterprise
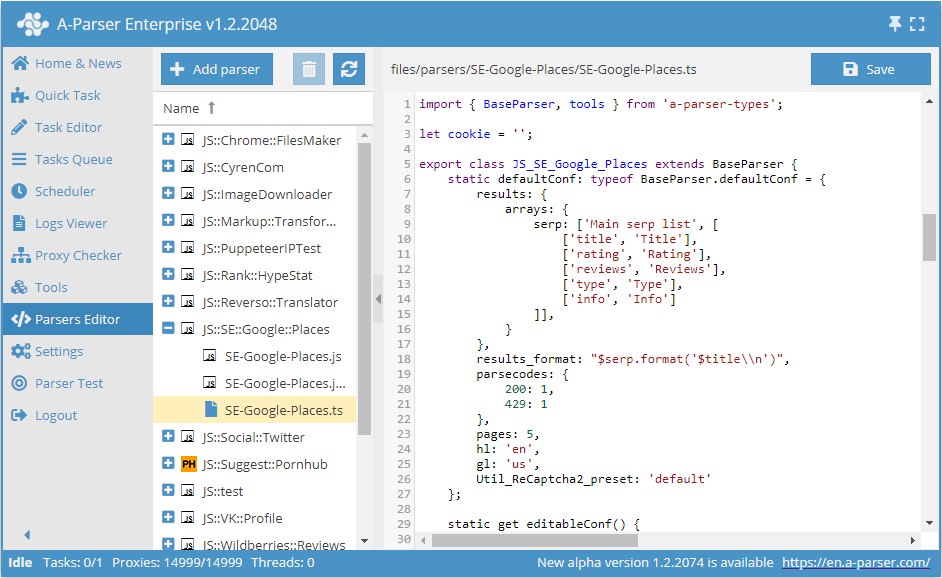
Accesso all'Editor degli scraper JS
Se A-Parser viene utilizzato da remoto, per motivi di sicurezza l'Editor degli scraper JS non è disponibile per impostazione predefinita. Per abilitare l'accesso, è necessario:
- Impostare una password nella scheda Settings -> Global Settings
- Aggiungere nel file config/config.txt la seguente riga:
allow_javascript_editor: 1 - Riavviare A-Parser
Istruzioni per l'uso
Nell'Editor degli scraper creiamo un nuovo scraper e assegniamo un nome allo scraper. Per impostazione predefinita verrà caricato un semplice esempio, sulla base del quale è possibile iniziare rapidamente a creare il proprio scraper.
Se per scrivere il codice si utilizza un editor esterno, è necessario aprire il file dello scraper in fase di modifica nella cartella /parsers/. Struttura dei file del programma installato.
Quando il codice è pronto, lo salviamo e lo utilizziamo come un normale scraper: nell'Editor delle attività selezioniamo lo scraper creato, se necessario è possibile impostare i parametri desiderati, la configurazione dei thread, il nome del file, ecc.
Lo scraper creato può essere modificato in qualsiasi momento. Tutte le modifiche riguardanti l'interfaccia appariranno dopo aver selezionato nuovamente lo scraper nell'elenco degli scraper o dopo il riavvio di A-Parser; le modifiche alla logica dello scraper vengono applicate al successivo avvio dell'attività con lo scraper.
Per ogni scraper creato viene visualizzata per impostazione predefinita un'icona standard, è possibile aggiungerne una propria in formato png o ico, posizionandola nella cartella dello scraper in /parsers/:

Principi generali di funzionamento
Per impostazione predefinita viene creato un esempio di un semplice scraper, pronto per ulteriori modifiche.
- TypeScript
- JavaScript
import { BaseParser } from 'a-parser-types';
export class JS_v2_example extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'HTML title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: '$query: $title\\n',
};
static editableConf: typeof BaseParser.editableConf = [];
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
let response = await this.request('GET', set.query, {}, {
check_content: ['<\/html>'],
decode: 'auto-html',
});
if (response.success) {
let matches = response.data.match(/<title>(.*?)<\/title>/i);
if (matches)
results.title = matches[1];
}
results.success = response.success;
return results;
}
}
const { BaseParser } = require("a-parser-types");
class JS_v2_example_js extends BaseParser {
static defaultConf = {
version: '0.0.1',
results: {
flat: [
['title', 'HTML title'],
]
},
max_size: 2 * 1024 * 1024,
parsecodes: {
200: 1,
},
results_format: '$query: $title\\n',
};
static editableConf = [];
async parse(set, results) {
this.logger.put("Start scraping query: " + set.query);
let response = await this.request('GET', set.query, {}, {
check_content: ['<\/html>'],
decode: 'auto-html',
});
if (response.success) {
let matches = response.data.match(/<title>(.*?)<\/title>/i);
if (matches)
results.title = matches[1];
}
results.success = response.success;
return results;
}
}
Il costruttore viene chiamato una sola volta per ogni attività. È obbligatorio impostare this.defaultConf.results e this.defaultConf.results_format, gli altri campi sono facoltativi e assumeranno i valori predefiniti.
L'array this.editableConf definisce quali impostazioni possono essere modificate dall'utente dall'interfaccia di A-Parser. È possibile utilizzare i seguenti tipi di campi:
combobox- menu a discesa di selezione. È anche possibile creare un menu di selezione del preset di uno scraper standard, ad esempio:
['Util_AntiGate_preset', ['combobox', 'AntiGate preset']]
comboboxcon possibilità di selezione multipla. È necessario impostare ulteriormente il parametro{'multiSelect': 1}:
['proxyCheckers', ['combobox', 'Proxy Checkers', {'multiSelect': 1}, ['*', 'All']]]
checkbox- casella di controllo, per parametri che possono avere solo 2 valori (true/false)textfield- campo di testotextarea- campo di testo con inserimento su più righe
Il metodo parse è una funzione asincrona e per qualsiasi operazione bloccante deve restituire await (questa è la principale e unica differenza rispetto a una funzione normale). Il metodo viene chiamato per ogni query inviata in elaborazione. Vengono obbligatoriamente passati set (un hash con la query e i suoi parametri) e results (un modello vuoto per i risultati). È inoltre obbligatorio restituire results compilato, impostando preventivamente il flag success.
Versionamento automatico
La versione ha il formato Major.Minor.Revision
- TypeScript
- JavaScript
this.defaultConf: typeof BaseParser.defaultConf = {
version: '0.1.1',
...
}
this.defaultConf = {
version: '0.1.1',
...
}
Il valore Revision (l'ultima cifra) viene incrementato automaticamente ad ogni salvataggio. Gli altri valori (Major, Minor) possono essere modificati manualmente, così come è possibile resettare Revision a 0.
Se per qualche motivo è necessario modificare Revision solo manualmente, la versione deve essere racchiusa tra virgolette doppie ""
Elaborazione batch delle query
In alcuni casi potrebbe essere necessario prelevare più query contemporaneamente dalla coda ed elaborarle in una sola volta. Tale modalità negli scraper integrati viene utilizzata quando in un unico passaggio è necessario richiedere dati per più chiavi contemporaneamente (a pacchetti).
Per implementare la stessa funzionalità in uno scraper JS, è necessario impostare in this.defaultConf il valore bulkQueries: N, dove N è il numero richiesto di query nel pacchetto. In questo caso lo scraper preleverà le query a pacchetti di N unità e tutte le query dell'iterazione corrente saranno contenute nell'array set.bulkQueries (incluse tutte le variabili standard: query.first, query.orig, query.prev, ecc.). Di seguito un esempio di tale array:
[
{
"first": "test",
"prev": "",
"lvl": 0,
"num": 0,
"query": "test",
"queryUid": "6eb301",
"orig": "test"
},
{
"first": "test",
"prev": "",
"lvl": 0,
"num": 1,
"query": "test",
"queryUid": "774563",
"orig": "test"
},
{
"first": "third query",
"prev": "",
"lvl": 0,
"num": 2,
"query": "third query",
"queryUid": "2bc8ed",
"orig": "third query"
}
]
I risultati nell'elaborazione batch devono essere inseriti nell'array results.bulkResults, dove ogni elemento è un oggetto results. Gli elementi in results.bulkResults sono disposti nello stesso ordine presente in set.bulkQueries.
Link utili
📄️ Esempio bulkQueries
Esempio di utilizzo di bulkQueries con la chiamata di uno scraper integrato
🔗 Esempi e discussione
Discussione sul forum con esempi e discussione sulle funzionalità degli scraper JS
🔗 Catalogo degli scraper JS
Sezione nel catalogo delle risorse dedicata agli scraper JS
🔗 Panoramica delle funzionalità di base di ES6
Articolo su habrahabr dedicato alla panoramica delle funzionalità di base di ES6