Gestione di Chrome (puppeteer)
A-Parser consente di utilizzare il browser Chrome (Chromium) come motore per il download e il rendering delle pagine, utilizzando la popolare libreria puppeteer.
I principali vantaggi dell'utilizzo di puppeteer insieme ad A-Parser:
- supporto per proxy separati per ogni scheda del browser
- gestione multithreading delle schede del browser
- intercettazione delle richieste
- tutte le funzionalità di A-Parser per la gestione della coda, la formazione delle query e l'elaborazione dei risultati
L'utilizzo del browser Chrome apre le seguenti possibilità:
- rendering di
DOMeJavaScript - possibilità di interazione interattiva con gli elementi dei siti:
- compilazione di moduli
- navigazione tramite link
- drag & drop
- caricamento di file
- emulazione del mouse
- e molto altro, è possibile automatizzare qualsiasi azione standard
- bypass più semplice di varie protezioni anti-scraping, poiché il browser Chromium è il più simile possibile a quello utilizzato dagli utenti
- possibilità di lavorare in modalità
Headless, ovvero senza l'interfaccia grafica del browser, il che consente di risparmiare risorse e di eseguire il browser su server senza ambiente grafico
È necessario tenere presente che il funzionamento del browser è molto più esigente in termini di risorse (CPU, Memoria) rispetto ai normali thread di A-Parser
A seconda della complessità del sito, si raccomanda di utilizzare un numero di thread (schede del browser) non superiore a 1-2 per ogni core del processore disponibile, ad esempio per processori a 8 core - da 8 a 16 schede
Esempio di utilizzo
Analizziamo l'esempio dello scraper Chrome::ScreenshotMaker2:
- lo scraper scatta screenshot dei siti della dimensione specificata e può anche rimpicciolire (scalare) l'immagine
- può opzionalmente utilizzare proxy
- crea una scheda del browser separata per ogni thread di A-Parser
import { BaseParser, PuppeteerTypes } from 'a-parser-types';
let browser: PuppeteerTypes.Browser;
let jimp;
class JS_Chrome_ScreenshotsMaker2 extends BaseParser {
static defaultConf: typeof BaseParser.defaultConf = {
version: '0.2.1',
results: {
flat: [
['screenshot', 'PNG screenshot'],
]
},
results_format: '$screenshot',
load_timeout: 30,
width: 1024,
height: 768,
log_screenshots: 0,
headless: 1,
};
static editableConf: typeof BaseParser.editableConf = [
['log_screenshots', ['checkbox', 'Log Screenshots']],
['width', ['textfield', 'Viewport Width']],
['height', ['textfield', 'Viewport Height']],
['resize_width', ['textfield', 'Resize Width']],
['resize_height', ['textfield', 'Resize Height']],
['headless', ['checkbox', 'Chrome Headless']],
];
async init() {
// inizializziamo il browser
browser = await this.puppeteer.launch({
headless: this.conf.headless,
logConnections: false,
defaultViewport: {
width: parseInt(this.conf.width),
height: parseInt(this.conf.height),
}
});
if (this.conf.resize_width) {
// colleghiamo il modulo jimp se è necessario fare il resize dello screenshot
jimp = require('jimp');
};
};
async destroy() {
// chiudiamo il browser al termine del lavoro dell'attività
if (browser)
await browser.close();
}
page: PuppeteerTypes.Page;
async threadInit() {
// creiamo una pagina del browser durante l'inizializzazione del thread
this.page = await browser.newPage();
// metodi standard di puppeteer
await this.page.setCacheEnabled(true);
await this.page.setDefaultNavigationTimeout(this.conf.timeout * 1000);
// indichiamo ad A-Parser di usare il proxy per questa pagina
await this.puppeteer.setPageUseProxy(this.page);
this.logger.put(`New page created for thread #${this.threadId}`);
}
async parse(set, results) {
const self = this;
const { conf, page } = self;
for (let attempt = 1; attempt <= conf.proxyretries; attempt++) {
try {
self.logger.put(`Attempt #${attempt}`);
// andiamo alla pagina specificata nella query
await page.goto(set.query);
// nascondiamo la barra di scorrimento per lo screenshot
await page.evaluate(() => { document.querySelector('html').style.overflow = 'hidden'; });
// otteniamo lo screenshot
results.screenshot = await page.screenshot();
if (parseInt(conf.resize_width)) {
// se necessario ridimensioniamo l'immagine
let image = await jimp.read(results.screenshot);
image.resize(parseInt(conf.resize_width), parseInt(conf.resize_height));
results.screenshot = await image.getBufferAsync('image/png');
}
self.logger.put(`Screenshot(${attempt}): OK, size: ${parseInt("" + (results.screenshot.length / 1024))}KB`);
if (conf.log_screenshots)
self.logger.putHTML("<img src='data:image/png;base64," + results.screenshot.toString('base64') + "'>");
results.success = 1;
// chiudiamo le connessioni correnti, poiché il browser usa keep-alive
await self.puppeteer.closeActiveConnections();
break;
}
catch (error) {
self.logger.put(`Fetch page error: ${error}`);
// chiudiamo le connessioni correnti, poiché il browser usa keep-alive
await self.puppeteer.closeActiveConnections();
// cambiamo il proxy per la scheda del browser
await self.proxy.next();
}
}
return results;
}
}
Questo esempio dimostra la semplicità di utilizzare diversi proxy per ogni scheda, così come il lavoro multithreading (1 thread = 1 scheda del browser)
Descrizione dei metodi
await this.puppeteer.launch(opts?)
Questo metodo è analogo al metodo .launch della libreria puppeteer, avvia il browser Chromium con le opzioni opts necessarie. La differenza principale consiste nell'integrazione con A-Parser e nel supporto dei proxy per ogni scheda, oltre alla presenza di opzioni aggiuntive:
logConnections?: boolean
Abilita il logging di tutte le connessioni (indipendentemente dall'uso del proxy o meno), l'output del log viene effettuato separatamente per thread
stealth?: boolean
Utilizza il plugin puppeteer-extra per mascherare Chromium come un vero Chrome
stealthOpts?: any
Opzioni aggiuntive per il plugin puppeteer-extra
extraPlugins?: array
Utilizzo di plugin aggiuntivi, come ad esempio puppeteer-extra/packages
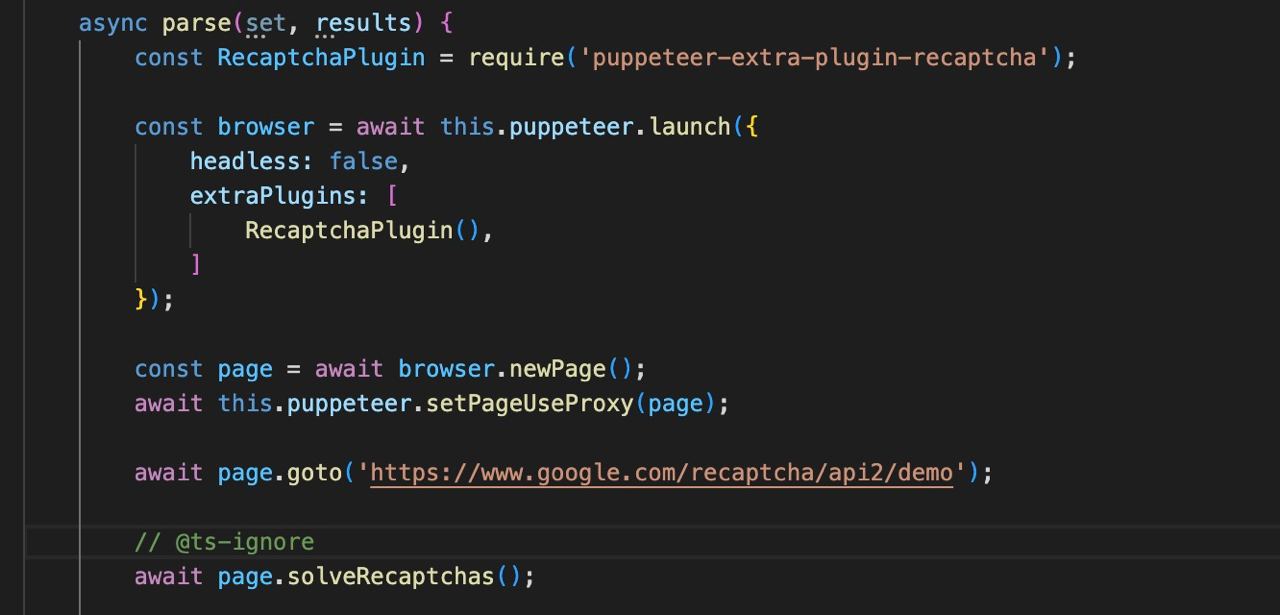
Altre opzioni
Tutte le altre opzioni di avvio possono essere consultate nella documentazione originale di puppeteer
await this.puppeteer.setPageUseProxy(page)
Questo metodo collega la pagina del browser con il thread di A-Parser per il corretto funzionamento del proxy, deve essere chiamato subito dopo la creazione della pagina:
const page = await browser.newPage();
await this.puppeteer.setPageUseProxy(page);
await this.puppeteer.closeActiveConnections(page?)
Questo metodo deve essere chiamato dopo il completamento dell'elaborazione della query o prima di cambiare il proxy per elaborare il tentativo successivo
Il browser Chrome lascia per impostazione predefinita aperte le connessioni con i siti a cui si collega, questo metodo consente di controllare il numero di risorse utilizzate e riduce il carico sui proxy
L'argomento page è opzionale; se chiamato senza argomento, A-Parser chiuderà le connessioni per la scheda associata al thread corrente
await this.puppeteer.logScreenshot()
Il metodo registra lo screenshot della pagina corrente