Domande frequenti
1. Domande relative a demo, pagamento e acquisto
1.1. Come scaricare i risultati nella versione Demo?
Nella versione Demo i risultati del lavoro non sono disponibili per il download. Li forniamo su vostra richiesta. Inviate le vostre query e indicate quale scraper vi interessa, e noi vi invieremo i risultati (nell'ambito della demo il loro numero è limitato).
1.2. Devo pagare un supplemento per qualcosa dopo l'acquisto di A-Parser?
No. Più in dettaglio: licenze e componenti aggiuntivi, pagina di acquisto.
1.3. Dove e come posso pagare i proxy?
Al momento dell'acquisto di una licenza vi vengono forniti dei proxy bonus.
Lite - 20 thread per 2 settimane, Pro ed Enterprise - 50 thread per un mese.
Potete acquistare più thread o rinnovarli nell' Area membri nella scheda Negozio, sottosezione Proxy.
1.4. Potreste configurarmi un task a pagamento?
Il supporto tecnico per questioni legate al funzionamento di A-Parser è fornito gratuitamente. Per quanto riguarda l'assistenza a pagamento nella configurazione dei task, potete rivolgervi qui: Servizi a pagamento per la configurazione di task, aiuto con il setup e formazione sull'uso di A-Parser.
1.5. Posso effettuare il pagamento per lo scraper tramite la banca Privat24? Tramite KIWI?
L'elenco dei sistemi di pagamento con cui lavoriamo è indicato qui: acquista A-Parser.
1.6. Se devo sparseri solo il numero di pagine indicizzate su Yandex, quale scraper mi conviene comprare?
Per tali scopi è sufficiente la versione Lite, ma la Pro è più pratica e flessibile nel lavoro.
1.7. Dove posso vedere le informazioni sulla mia licenza?
1.8. È possibile utilizzare i proxy acquistati da più IP?
No.
2. Domande su installazione, avvio e aggiornamenti
2.1. Clicco sul pulsante Download - ma l'archivio non viene scaricato. Cosa fare?
Verificate se avete spazio libero sul disco rigido, disattivate l'antivirus. Seguite le istruzioni di installazione. Consultate anche Come iniziare a lavorare.
2.2. Ho comprato la versione Enterprise, ma si installa ancora la PRO. Cosa fare?
Eliminate la versione precedente. Nell'Area membri verificate se il vostro indirizzo IP è inserito correttamente. Prima del caricamento premete il pulsante Update (Aggiorna). Scaricate la versione più recente. Più in dettaglio nelle istruzioni di installazione.
2.3. Ho installato il programma, ma non si avvia, cosa fare?
Controllate le applicazioni in esecuzione, disattivate l'antivirus, verificate il volume disponibile di memoria RAM libera. Inoltre nell' Area membri verificate se il vostro indirizzo IP è inserito correttamente. Più in dettaglio: istruzioni di installazione.
2.4. Cosa fare se ho un indirizzo IP dinamico?
Niente di grave, A-Parser supporta il lavoro con indirizzi IP dinamici. Semplicemente ogni volta che cambia, è necessario inserirlo nell'Area membri. Per evitare queste manipolazioni, si raccomanda di utilizzare un indirizzo IP statico.
2.5. Quali sono i parametri ottimali del server, computer per l'installazione dello scraper?
Tutti i requisiti di sistema possono essere consultati qui: requisiti di sistema.
2.6. Ho avviato un task. Lo scraper è andato in crash e non si avvia più, cosa fare?
È necessario arrestare il server, verificare se il processo è ancora in memoria e provare a riavviarlo. Si può anche provare ad avviare A-Parser con l'arresto di tutti i task. Per fare ciò, è necessario avviarlo con il parametro -stoptasks. Dettagli sull'avvio con parametro.
2.7. Quale password inserire all'apertura dell'indirizzo 127.0.0.1:9091?
Se è il primo avvio, la password è vuota. Se non è il primo, quella che avete impostato. Se avete dimenticato la password - ripristino password.
2.8. Nell'Area membri inserisco il mio IP, ma non cambia nel campo Il tuo IP attuale. Perché?
Il campo Your current IP (Il tuo IP attuale) mostra l'IP che è attualmente valido per te, e non deve cambiare. È questo che devi inserire nel campo IP 1.
2.9. Posso avviare contemporaneamente due copie?
È possibile avviare due copie sulla stessa macchina solo se hanno porte diverse configurate nel file di configurazione.
È possibile avviare due A-Parser su macchine diverse contemporaneamente solo se è stato acquistato un IP aggiuntivo nell' Area membri.
2.10. Lo scraper è legato all'hardware?
No. Per il controllo delle licenze viene utilizzato il vostro IP.
2.11. Domanda sull'aggiornamento - aggiornare solo .exe? config/config.db e files/Rank-CMS/apps.json - a cosa servono questi file?
Se non diversamente specificato, aggiornare solo .exe. Il primo file serve per memorizzare la configurazione di A-Parser, mentre il secondo è il database per identificare i CMS e per il funzionamento dello scraper ![]() Rank::CMS.
Rank::CMS.
2.12. Ho Win Server 2008 Web Edition - lo scraper non si avvia...
Su questa versione del sistema operativo A-Parser non funzionerà. L'unica opzione è cambiare il sistema operativo.
2.13. Ho un processore a 4 core. Perché A-Parser utilizza solo un core?
A-Parser utilizza da 2 a 4 core, i core aggiuntivi vengono utilizzati solo durante il filtraggio, il Costruttore di risultati, Parse custom result
2.14. Ha iniziato a comparire un errore di segmentazione (segmentation failed, segmentation error). Cosa fare?
Molto probabilmente il vostro IP è cambiato. Verificate nell' Area membri.
2.15. Ho Linux. A-Parser si è avviato, ma non si apre nel browser. Come risolvere?
Controllate il firewall - molto probabilmente sta bloccando l'accesso.
2.16. Ho Windows 7. A-Parser si è avviato, ma non si apre nel browser e nel task manager non c'è il processo Node.js. Come risolvere?
È necessario controllare gli aggiornamenti di Windows e installare gli ultimi disponibili. In particolare è necessario l' aggiornamento Windows 7 SP1.
2.17. A-Parser non si avvia e in aparser.log viene scritto l'errore FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Molto probabilmente sorge un problema con qualche task (cartella /config/tasks/), a causa di un errore del disco (ad esempio se l'alimentazione del PC è stata interrotta senza un arresto corretto), maggiori dettagli si possono ottenere avviando A-Parser con il flag -morelogs
Soluzione: avvio di A-Parser con il parametro -stoptasks. Se non aiuta, pulite l'intera cartella /config/tasks/. Se anche dopo questo il problema non è risolto, installate nuovamente lo scraper in una nuova directory e inserite il config del vecchio (se non è danneggiato).
3. Domande sulla configurazione di A-Parser e altre impostazioni
3.1. Come configurare il proxy checker?
Le istruzioni dettagliate si trovano qui: configurazione proxy.
3.2. Non ci sono proxy attivi - perché?
Verificate la vostra connessione internet e la correttezza della configurazione del proxy checker. Se tutto è stato fatto correttamente, significa che al momento la vostra lista proxy non contiene server funzionanti. Soluzione a questo problema: utilizzare altri proxy oppure riprovare più tardi. Se utilizzate i nostri proxy, verificate l'indirizzo IP nell' Area membri nella sezione Proxies (Proxy). È anche possibile che il vostro provider blocchi l'accesso ad altri DNS, provate a seguire i passaggi descritti qui: http://a-parser.com/threads/1240/#post-3582
3.3. Come collegare Antigate?
Istruzioni dettagliate sulla configurazione di Antigate qui.
3.4. Ho cambiato i parametri nelle impostazioni dello scraper, ma non sono stati applicati. Perché?
Il preset predefinito (default) non può essere modificato; se vengono apportate modifiche, è necessario cliccare su Save as New Preset (Salva come nuovo preset) e successivamente utilizzarlo nel proprio task.
3.5. È possibile modificare le impostazioni di un task in esecuzione?
Sì, ma non tutte. In un task in esecuzione è possibile premere pausa e nello stesso menu a discesa scegliere Edit (Modifica).
3.6. Come importare un preset?
Premere il pulsante accanto al campo di selezione del task nell' Editor dei task. Dettagli qui.
3.7. Come configurare lo scraper affinché non utilizzi i proxy?
Nelle impostazioni dello scraper desiderato, deselezionare la casella Use proxy.
3.8. Non ho il pulsante Aggiungi sovrascrittura / Override option!
Questa opzione può essere aggiunta direttamente nell' Editor dei task. Opzioni dello scraper.
3.9. Come sovrascrivere nello stesso file con i risultati?
Durante la creazione del task, impostare l'opzione Overwrite file (Sovrascrivi file).
3.10. Dove cambiare la password dello scraper?
3.11. Ho messo 6 milioni di chiavi per lo scraping, ho anche indicato che i domini siano tutti unici. Come fare in modo che quando metterò nuove 6 milioni di chiavi, vengano registrati solo domini unici che non si intersecano con lo scraping precedente?
È necessario utilizzare l'opzione Keep unique (Salva la deduplicazione) durante la creazione del primo task e indicare il database salvato nel secondo. Dettagli in Opzioni aggiuntive dell'editor dei task.
3.12. Come aggirare il limite di 1000 risultati per Google?
Utilizzate l'opzione Sparseri tutti i risultati / Parse all results.
3.13. Come aggirare il limite di 1024 thread su Linux?
3.14. Qual è il limite di thread su Windows?
Fino a 10000 thread.
3.15. Come rendere le query uniche?
Utilizzare l'opzione Unique queries (Query uniche) nel blocco Queries (Query) nell' Editor dei task.
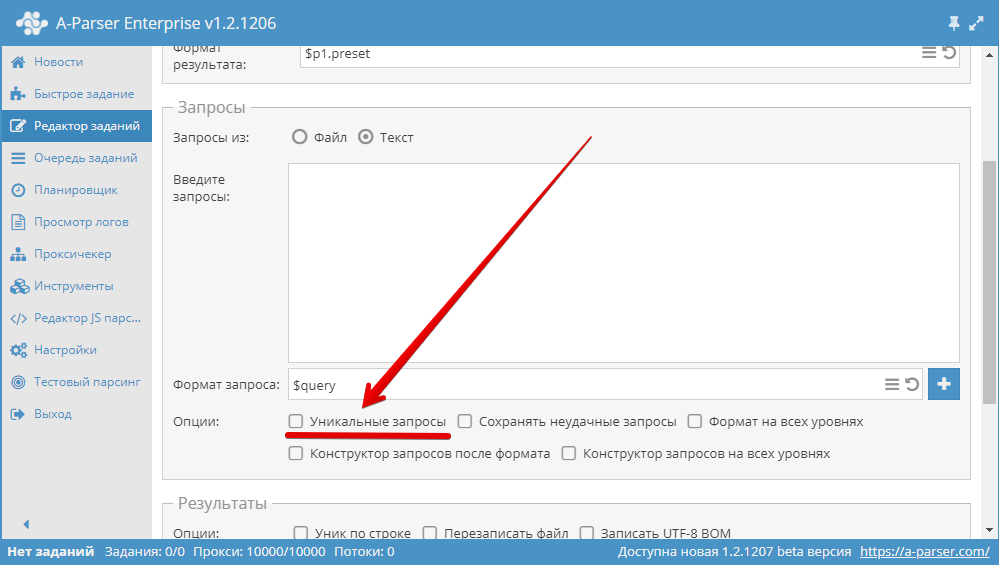
3.16. Come disattivare il controllo dei proxy?
In Impostazioni - Impostazioni proxy checker selezionare il proxy checker desiderato e aggiungere la spunta No check proxies (Non controllare i proxy). Salvare e selezionare il preset salvato.
3.17. Cos'è Proxy ban time? Posso impostarlo a 0?
Tempo di ban del proxy in secondi. Sì, è possibile.
3.18. Qual è la differenza tra Exact Domain e Top Level Domain nello scraper  SE::Google::Position
SE::Google::Position
Exact Domain è una corrispondenza rigorosa, cioè se nei risultati c'è www.domain.com e noi cerchiamo domain.com, non ci sarà corrispondenza. Top Level Domain confronta l'intero dominio di primo livello, quindi qui ci sarà corrispondenza.
3.19. Se avvio uno scraping di prova - tutto funziona, se uno normale - ricevo l'errore Some error.
Molto probabilmente il problema è nei DNS, provate a seguire questa istruzione sulla configurazione dei DNS.
3.20. Dove si imposta il Formato del risultato?
Durante la formattazione del risultato utilizzare \n. Esempio:
3.21. In  SE::Google manca la lingua olandese, anche se nelle impostazioni di Google è presente. Perché?
SE::Google manca la lingua olandese, anche se nelle impostazioni di Google è presente. Perché?
La lingua olandese è indicata come Dutch ed è presente nell'elenco. Dettagli nel miglioramento sull'aggiunta della lingua olandese.
4. Domande sullo scraping ed errori durante lo scraping
4.1. Cosa sono i thread?
Tutti i processori moderni possono eseguire attività in più thread, il che aumenta significativamente la velocità di esecuzione. Per fare un paragone, si può pensare a un normale autobus che trasporta un certo numero di persone in un'unità di tempo: questa sarebbe una normale elaborazione a thread singolo; un autobus a due piani che trasporta il doppio delle persone nello stesso tempo rappresenterebbe invece l'elaborazione multithreading. A-Parser può gestire contemporaneamente fino a 10000 thread.
4.2. Il task non si avvia - scrive Some Error - perché?
Verifica l'indirizzo IP nell'Area membri.
4.3. Tutte le query finiscono tra quelle fallite, cosa fare?
Molto probabilmente l'attività è stata configurata in modo errato o viene utilizzato un formato di query non valido. Verifica anche se ci sono Proxy attivi. Puoi anche provare ad aumentare l'opzione Request retries (maggiori dettagli qui: richieste non riuscite).
4.4. Quanti account è necessario registrare per eseguire lo scraping di 1.000.000 di parole chiave con  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
Non è possibile dire esattamente quanti account siano necessari, poiché un account può smettere di essere valido dopo un numero imprecisato di richieste. Tuttavia, è sempre possibile registrare nuovi account utilizzando lo scraper  SE::Yandex::Register o semplicemente aggiungere gli account esistenti nel file files/SE-Yandex/accounts.txt.
SE::Yandex::Register o semplicemente aggiungere gli account esistenti nel file files/SE-Yandex/accounts.txt.
4.5. Il task non si avvia, scrive Error: Lock 100 threads failed(20 of limit 100 used) cosa fare?
È necessario aumentare il numero massimo di thread disponibili nelle impostazioni dello scraper, oppure ridurlo nelle impostazioni dell'attività. Dettagli in Impostazioni.
4.6. È possibile avviare 2 task contemporaneamente?
Sì, A-Parser supporta l'esecuzione di più attività contemporaneamente. Il numero di attività attive simultaneamente si regola in Impostazioni - Impostazioni generali: Massimo attività attive.
4.7. Dove si trova il file con i risultati?
Nella scheda Tasks Queue (Coda attività), al termine di ogni attività, è possibile scaricare i risultati del lavoro. Fisicamente si trovano nella cartella results.
4.8. È possibile scaricare il file con i risultati se lo scraping non è terminato?
No, finché lo scraping non è terminato, non è possibile scaricare i risultati. Tuttavia, è possibile copiarli dalla cartella aparser/results quando l'attività è interrotta o in pausa.
4.9. È possibile con il vostro scraper sparseri 1.000.000 di link per una singola query?
Sì, utilizzando l'opzione Parse all results.
4.10. È possibile utilizzare  Rank::CMS,
Rank::CMS,  Net::Whois senza proxy?
Net::Whois senza proxy?
Net::Whois - non è consigliabile.4.11. Come sparseri i link da Google?
È necessario utilizzare SE::Google.
4.12. Lo scraper può seguire i link?
Sì, lo scraper  HTML::LinkExtractor è in grado di farlo utilizzando l'opzione Parse to level
HTML::LinkExtractor è in grado di farlo utilizzando l'opzione Parse to level
4.13. Google sparserisce molto lentamente, cosa fare?
Per prima cosa bisogna controllare i log dell'attività, forse tutte le richieste sono fallite. In tal caso, è necessario trovare il motivo per cui le richieste falliscono e correggerlo. Durante lo scraping con SE::Google, i tentativi falliti nei log sono spesso dovuti al fatto che Google mostra i captcha, il che è normale. È possibile collegare Antigate per bypassare i captcha, in modo che lo scraper non esaurisca i tentativi.
Inoltre, esiste un articolo che descrive i fattori che influenzano la velocità di scraping e come agiscono: velocità e principio di funzionamento degli scraper.
4.14. È possibile con il vostro scraper sparseri link in cui il testo è solo in lingua giapponese?
Sì, per farlo è necessario impostare la lingua desiderata nelle impostazioni dello scraper e utilizzare parole chiave in giapponese.
4.15. È possibile con il vostro scraper sparseri link solo nella zona di dominio .de o .ru
Sì. Per farlo è necessario utilizzare un filtro.
4.16. Come ottenere ogni risultato nel file su una nuova riga?
Durante la formattazione del risultato utilizzare \n. Esempio:
$serp.format('$link\n')
4.17. Come sparseri i primi 10 siti da Google?
Ecco il preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Aggiungo un task, vado nella scheda Coda dei task - ma non c'è! Perché?
O è stato commesso un errore nella creazione dell'attività, oppure è già stata completata ed è passata in Completed (Completate).
4.19. Scrive che il file non è in utf-8, ma non l'ho cambiato ed è già utf-8, cosa fare?
Controlla di nuovo. Prova anche a cambiare la codifica, ad esempio utilizzando Notepad++.
4.20. Nel file con i risultati è tutto su una riga, anche se nel task ho impostato l'andata a capo - perché?
Nelle impostazioni aggiuntive di A-Parser è necessario utilizzare l'interruzione di riga CRLF (Windows).
Ma se hai già eseguito lo scraping senza questa opzione, utilizza un visualizzatore più avanzato per visualizzare il file, come Notepad++.
4.21. Quanto tempo ci vuole per controllare la frequenza delle query su Yandex per 1.000 query?
Questo indicatore dipende molto dai parametri dell'attività, dalle caratteristiche del server, dalla qualità dei proxy, ecc., quindi non è possibile fornire una risposta univoca.
4.22. Come posso configurare lo scraper affinché nel risultato ci sia query-link?
Formato del risultato:
$p1.serp.format('$query: $link\n')
Il risultato sarà:
query: link 1
query: link 2
query: link 3
4.23. Come posso risparseri le query fallite e dove sono memorizzate?
Affinché le richieste fallite vengano salvate, è necessario selezionare l'opzione corrispondente nel blocco Queries (Query) nell'Editor attività. Le richieste fallite sono memorizzate in queries\failed. È necessario creare una nuova attività e indicare come file delle query il file con le richieste fallite.
4.24. Come sbarazzarsi dei tag HTML durante lo scraping del testo?
Utilizza l'opzione Remove HTML tags nel Costruttore risultati.
4.25. Come fare in modo che vengano sparseriti solo i domini?
Utilizza l'opzione Extract Domain nel Costruttore risultati.
4.26. Qual è la dimensione massima del file con le query che si può utilizzare nello scraper?
Le dimensioni dei file delle query e dei risultati non sono limitate e possono raggiungere valori nell'ordine dei terabyte.
4.27. Perché, quando inserisco il testo nel campo delle query, lo scraper restituisce Queries length limited to 8192 characters?
Questo accade perché la lunghezza della query è limitata a 8192 caratteri. Per utilizzare query più lunghe, utilizza i file come sorgente delle query.
4.28. Cosa significa Thread in attesa - 3?
Questo significa che i proxy non sono sufficienti. Riduci il numero di thread o aumenta il numero di proxy.
4.29. Nello scraping di prova scrive 596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB) e non sparserisce, perché?
Questo indica che i proxy non sono funzionanti.
4.30. Qual è la differenza tra la lingua dei risultati e il paese di ricerca nello scraper di Google?
La differenza è la seguente: il paese di ricerca è il collegamento dei risultati a un paese specifico. Ad esempio, se cerchi acquistare finestre con un collegamento a un paese specifico, avranno la priorità i siti che offrono di acquistare finestre proprio in quel paese. La lingua dei risultati, invece, è quella in cui devono essere restituiti i risultati.
4.31. Non riesco a sparseri un determinato sito. Cosa può essere?
Spesso il problema è dovuto a un blocco causato da uno user agent obsoleto lato server. Si risolve con un nuovo user agent o con il seguente codice nel parametro User agent:
[% tools.ua.random() %]
4.32. Lo scraper si blocca, si chiude improvvisamente. Nel log compare la riga syswrite: No space left on device
A-Parser non ha abbastanza spazio sul disco rigido. Libera più spazio.
4.33. Lo scraper ha iniziato a restituire none nei risultati (o un risultato chiaramente errato)
4.34. Compare costantemente una finestra con la scritta Failed fetch news
4.35. Come visualizzare i primi n risultati della ricerca?
4.36. Come tracciare la catena dei redirect?
4.37. Come controllare l'indicizzazione di un link sul donatore?
Per tali scopi esiste uno scraper separato:  Check::BackLink.
Dettagli nella discussione.
Check::BackLink.
Dettagli nella discussione.
4.38. Lo scraper si chiude improvvisamente su Linux. Nel log è presente questa voce: EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...
Molto probabilmente è necessario ottimizzare il numero di thread, come descritto nella Documentazione: Ottimizzazione di Linux per un numero maggiore di thread.
4.39. Dove si possono vedere tutti i parametri possibili per il loro utilizzo tramite API?
Ottenere una richiesta API nell'interfaccia.
Inoltre, è possibile generare la configurazione completa dell'attività in JSON. Per farlo, è necessario prendere il codice dell'attività e decodificarlo da base64.
4.40. Sto scaricando immagini con  Net::HTTP, ma per qualche motivo sono tutte corrotte. Cosa fare?
Net::HTTP, ma per qualche motivo sono tutte corrotte. Cosa fare?
1) Controlla il parametro Max body size - potrebbe essere necessario aumentarlo. 2) Controlla nelle impostazioni di A-Parser il formato dell'interruzione di riga: Impostazioni aggiuntive - Interruzione di riga.
Affinché l'immagine non sia corrotta, deve essere utilizzato il formato UNIX.
4.41. Come ottenere admin contact da WHOIS?
Tale compito si risolve facilmente con la funzione Parse custom result e un'espressione regolare. Dettagli nella discussione.
4.42. Espressione regolare per lo scraping di numeri di telefono
4.43. Identificazione di siti senza versione mobile
4.44. Come scoprire il nome del server NS?
4.45. Come sparseri i link alla cache di Yandex?
4.46. Come sparseri i link a tutte le pagine del sito?
4.47. Come sparseri il title dalla pagina?
4.48. Come sparseri tutti i siti in una determinata zona di dominio?
4.49. Come raccogliere tutti gli URL con parametri?
4.50. Come filtrare i risultati per più criteri e suddividerli nel report?
4.51. Come semplificare la struttura del filtro?
4.52. Come ordinare per file a seconda del risultato?
4.53. Create new result directory every X number of files (English)
4.54. Primi passi nel lavoro con WordStat
4.55. Raccolta di blocchi di testo >1000 caratteri
4.56. Output di una determinata quantità di testo dalla pagina
Anche questo si risolve con Template Toolkit. Dettagli nella discussione.
4.57. Controllo della concorrenza e dell'occorrenza nel titolo in Google
4.58. Filtraggio per numero di occorrenze della query nell'anchor e nello snippet
4.59. Come ottenere il contenuto dell'articolo in una sola riga?
4.60. Come confrontare due date in formato stringa?
4.61. Come sparseri le parole evidenziate dallo snippet?
4.62. Esempio di task con l'utilizzo di più scraper
4.63. Come mescolare le righe nel risultato e come visualizzare un numero casuale di risultati?
4.64. Come firmare il risultato con MD5?
4.65. Come convertire la data da Unix timestamp a rappresentazione stringa?
4.66. Parse to level, come sparseri con limitazione?
4.67. Lo scraper va in crash su Linux all'avvio del task. Nel log ci sono queste righe: Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...
È necessario eseguire il comando nella console:
apt-get --reinstall --purge install netbase
4.68. Errore Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
È necessario avviare A-Parser non come root. Nello specifico: dall'utente root bisogna creare un nuovo utente senza privilegi di root (se ne esiste già uno, basta usarlo) e poi autorizzare questo utente a interagire con la directory di A-Parser, quindi effettuare il login con il nuovo utente e avviarlo da lì.
Sotto l'utente root creare un utente, è possibile seguire questa guida.
Per consentire all'utente creato di interagire con la directory di A-Parser, è necessario assegnargli i permessi. Per farlo, entriamo come utente root e diamo i permessi con il comando:
chown -R user:user aparser
4.69. Errore Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Sotto l'utente root eseguire il comando:
sysctl -w kernel.unprivileged_userns_clone=1
Il riavvio di A-Parser non è richiesto.
Per CentOS 7 la soluzione è in questo thread.
Sotto l'utente root eseguire il comando:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Quindi riavviare sysctl con il comando:
sysctl -p
4.70. Errore JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
L'errore si verifica a causa della mancanza di librerie nel sistema operativo per il funzionamento di Chrome.
L'elenco delle librerie necessarie per il funzionamento di Chrome si trova in Chrome headless doesn't launch on UNIX.
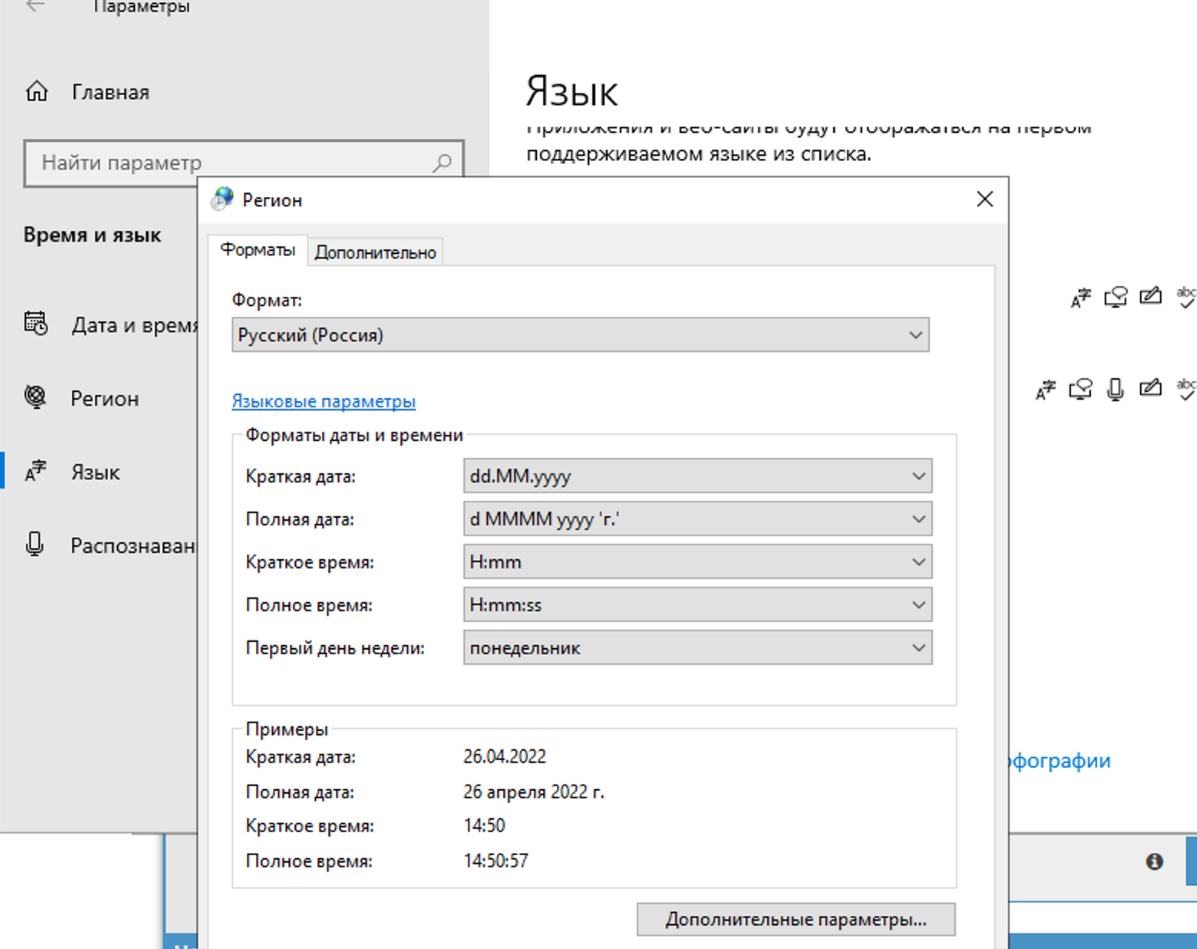
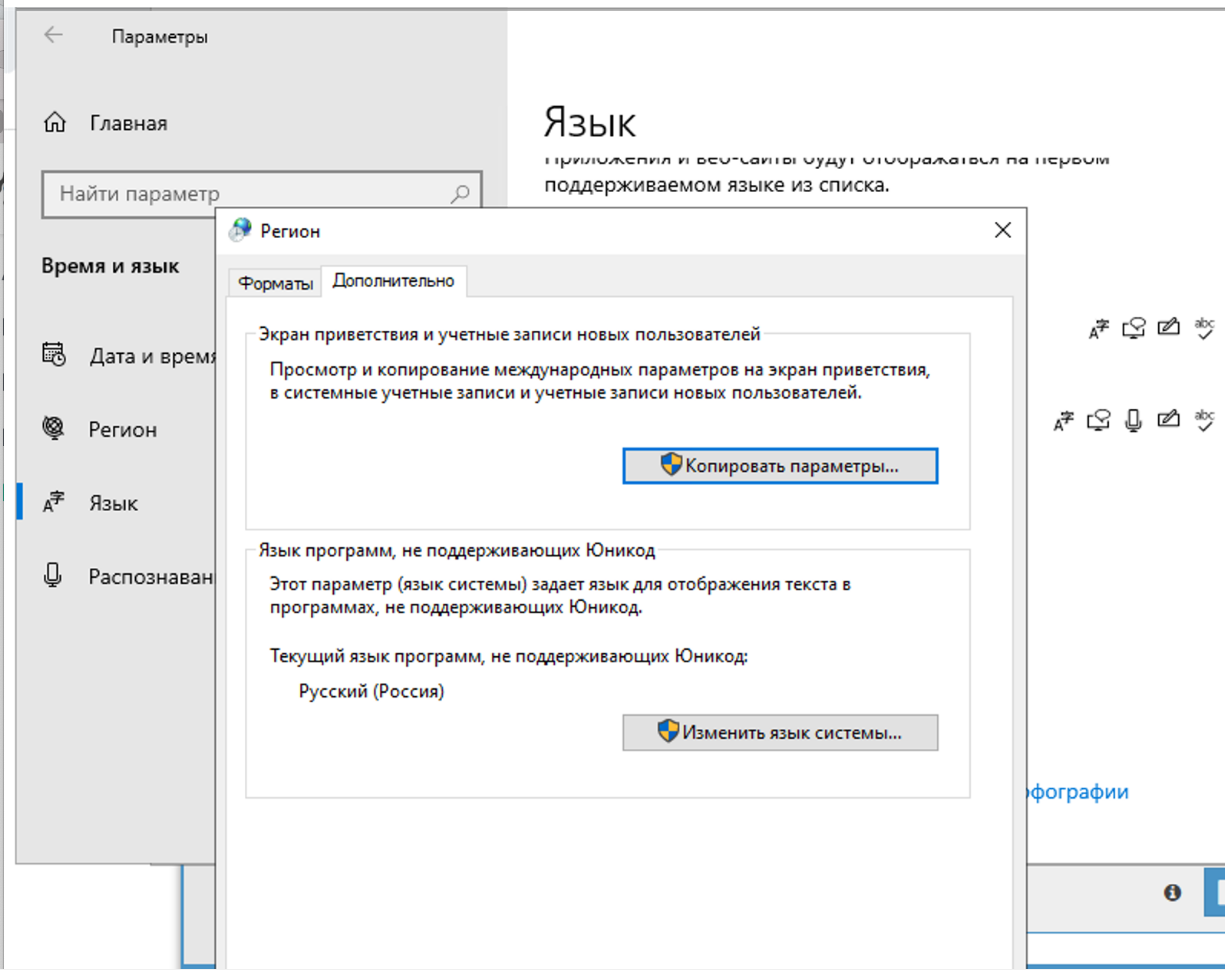
4.71. Perché il captcha non viene risolto? Nel log si vede che da Xevil A-Parser ha ricevuto punti interrogativi invece della risposta al captcha
Nelle impostazioni della regione è necessario impostare il russo.
Bisogna cambiare solo nella scheda avanzate. Questo non influisce sulla risoluzione dei captcha, ma in Xumer stesso ci sarà un problema con la codifica se si cambia in entrambi i posti.