Resultatenbouwer
Result Builders (Resultaat-constructor) - hiermee kunt u resultaten van elke scraper transformeren voordat ze worden geformatteerd en op schijf worden opgeslagen
Mogelijkheden
- Het resultaat in delen splitsen met behulp van een reguliere expressie of een willekeurig scheidingsteken
- Vervangen van een substring in het resultaat of vervanging door een reguliere expressie
- Het extraheren van het domein of hoofddomein uit een link
- Het resultaat omzetten naar hoofdletters\kleine letters
- Verwijderen van HTML-tags (
<b>text</b>->text) - Omzetten van HTML-entiteiten naar hun Unicode-equivalenten (
©->©) - Gegevens ophalen met behulp van XPath-query's
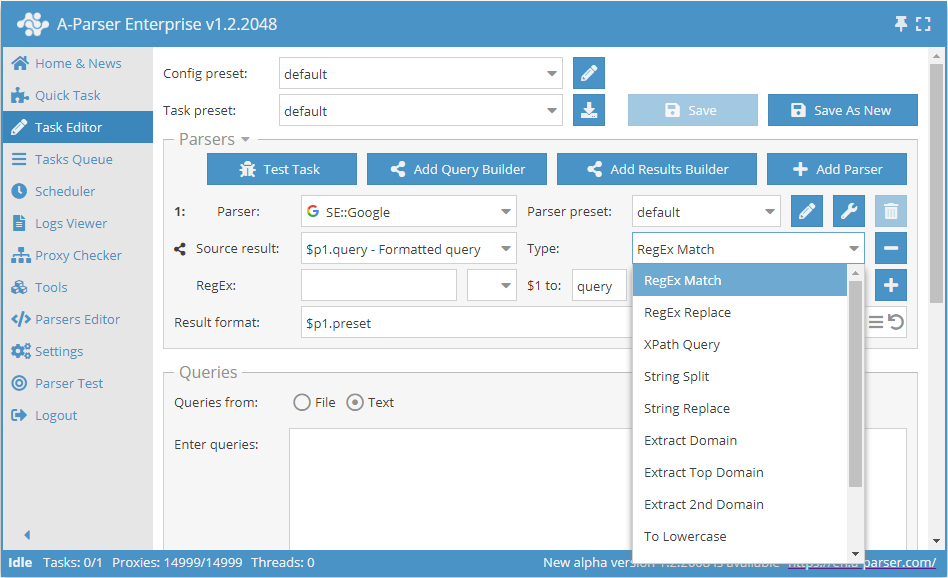
Voorbeelden
Domeinen scrapen
Alleen domeinen opslaan bij het scrapen van links uit zoekmachines:
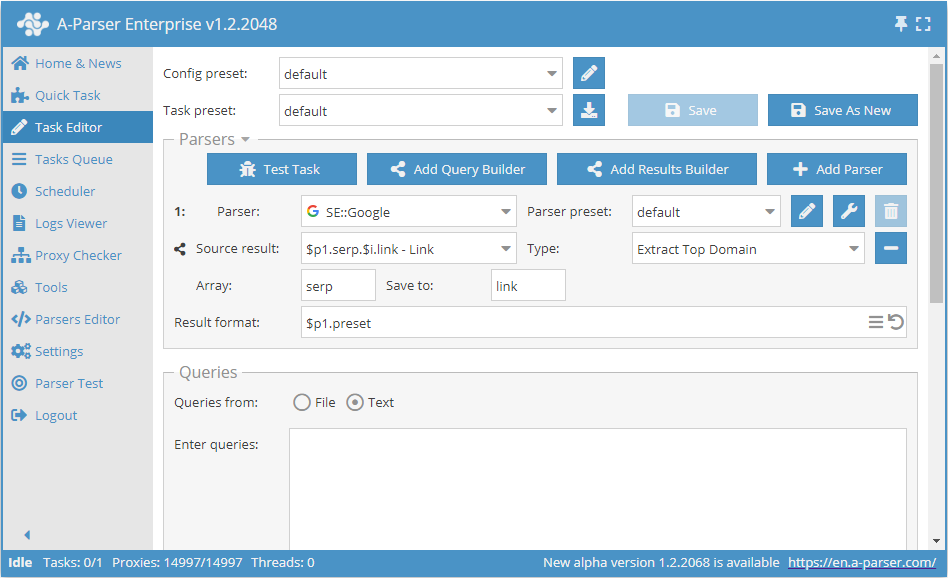
Als bron worden de link elementen uit de serp array van de eerste scraper gebruikt; op elk element wordt de functie voor het extraheren van het hoofddomein uit de link toegepast, het nieuwe resultaat wordt onder dezelfde naam opgeslagen (element link in de serp array) - daarom is het niet nodig om het resultaatformaat te wijzigen
Snippets scrapen met opschoning
Snippets uit zoekmachines opslaan met verwijdering van HTML-tags en omzetting van HTML-entiteiten
Standaard worden ankers en snippets gescraped met alle geneste tags, wat het mogelijk maakt om dezelfde opmaak te behouden als bij het bekijken van de zoekresultaten in de zoekmachine. Als alleen de schone tekst nodig is, kunt u gebruikmaken van de mogelijkheden van de Resultaat-constructor:
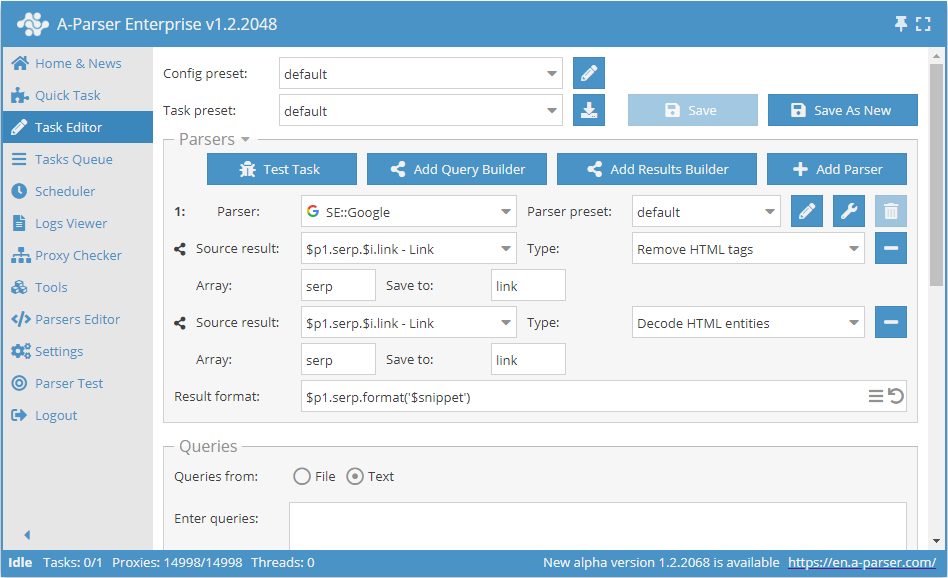
In dit voorbeeld zijn achtereenvolgens twee Resultaat-constructors op de snippets toegepast: het verwijderen van HTML-tags en het omzetten van HTML-entiteiten
Scrapen met behulp van XPath
Links uit zoekresultaten scrapen met behulp van XPath:
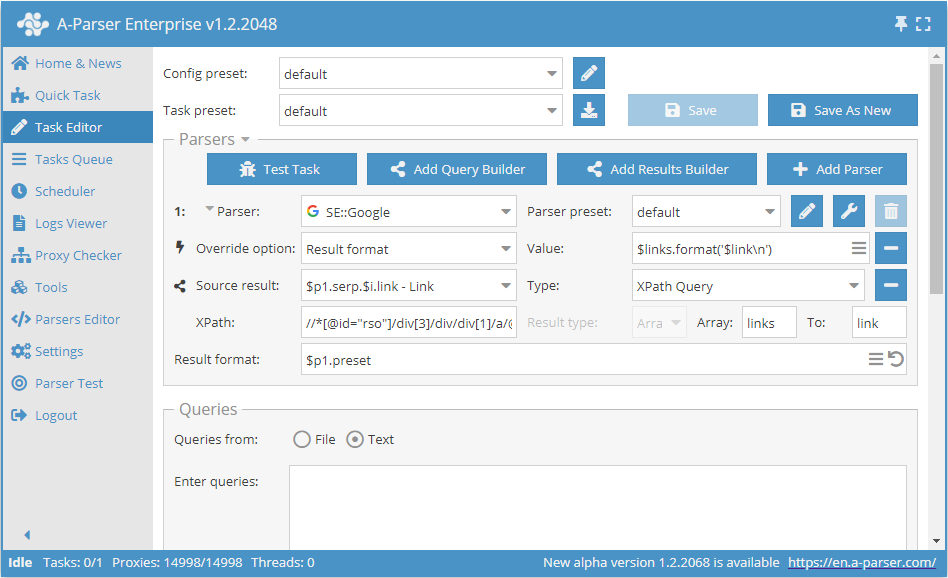
In dit voorbeeld wordt het scrapen van links uit de zoekmachine Google getoond. Er wordt een XPath-query gebruikt:
//*[@id="rso"]/div[3]/div/div[1]/a/@href