Veelgestelde vragen
1. Vragen over demo, betaling en aankoop
1.1. Hoe resultaten downloaden in de Demo-versie?
In de Demo-versie zijn de resultaten niet beschikbaar voor download. Wij verstrekken deze op aanvraag. Stuur ons uw zoekopdrachten en geef aan in welke scraper u geïnteresseerd bent, dan sturen wij u de resultaten toe (het aantal is beperkt binnen de demo).
1.2. Moet ik ergens extra voor betalen na aankoop van A-Parser?
Nee. Voor meer details: licenties en aanvullingen, aankooppagina.
1.3. Waar en hoe kan ik proxy's betalen?
Bij aankoop van een licentie krijgt u bonus-proxy's.
Lite - 20 threads voor 2 weken, Pro en Enterprise - 50 threads voor een maand.
U kunt meer threads kopen of verlengen in het Ledengebied op het tabblad Winkel, subsectie Proxy.
1.4. Kunt u voor mij een taak instellen tegen betaling?
Technische ondersteuning voor vragen over de werking van A-Parser is gratis. Voor betaalde hulp bij het opstellen van taken kunt u hier terecht: Betaalde diensten voor het opstellen van taken, hulp bij configuratie en training voor A-Parser.
1.5. Kan ik de scraper betalen via Privat24? Via KIWI?
De lijst met betalingssystemen waarmee wij werken, vindt u hier: koop A-Parser.
1.6. Als ik alleen het aantal geïndexeerde pagina's in Yandex wil scrapen, welke scraper kan ik dan het beste kopen?
Voor dergelijke doeleinden is de Lite-versie voldoende, maar Pro is praktischer en flexibeler in gebruik.
1.7. Waar kan ik informatie over mijn licentie inzien?
1.8. Is het mogelijk om gekochte proxy's vanaf meerdere IP's te gebruiken?
Nee.
2. Vragen over installatie, opstarten en updates
2.1. Ik klik op de knop Download - maar het archief downloadt niet. Wat te doen?
Controleer of u voldoende vrije ruimte op de harde schijf heeft en schakel uw antivirus uit. Volg de installatie-instructies. Bekijk ook Hoe te beginnen.
2.2. Ik heb de Enterprise-versie gekocht, maar er wordt nog steeds PRO geïnstalleerd. Wat te doen?
Verwijder de vorige versie. Controleer in de Members Area of uw IP-adres correct is ingevoerd. Klik op de knop Update (Bijwerken) voordat u gaat downloaden. Download de nieuwere versie. Meer details in de installatie-instructies.
2.3. Ik heb het programma geïnstalleerd, maar het start niet op, wat te doen?
Controleer actieve applicaties, schakel de antivirus uit en controleer de beschikbare hoeveelheid vrij RAM-geheugen. Controleer ook in het Ledengebied of uw IP-adres correct is ingevoerd. Meer details: installatie-instructies.
2.4. Wat moet ik doen als ik een dynamisch IP-adres heb?
Geen probleem, A-Parser ondersteunt het werken met dynamische IP-adressen. Telkens wanneer het verandert, moet u het invoeren in de Members Area. Om deze handelingen te vermijden, wordt aanbevolen een statisch IP-adres te gebruiken.
2.5. Wat zijn de optimale parameters voor een server of computer om de scraper te installeren?
Alle systeemvereisten zijn hier te vinden: systeemvereisten.
2.6. Ik heb een taak gestart. De scraper is gecrasht en start niet meer op, wat te doen?
U moet de server stoppen, controleren of het proces nog in het geheugen staat en proberen het opnieuw te starten. U kunt ook proberen A-Parser te starten met alle taken gestopt. Gebruik hiervoor de parameter -stoptasks. Details over starten met parameter.
2.7. Welk wachtwoord moet ik invoeren bij het openen van het adres 127.0.0.1:9091?
Als dit de eerste keer is, is het wachtwoord leeg. Als het niet de eerste keer is, gebruik dan het wachtwoord dat u heeft ingesteld. Als u het wachtwoord bent vergeten - wachtwoord resetten.
2.8. In het Ledengebied voer ik mijn IP in, maar het verandert niet in het veld Uw huidige IP. Waarom?
Het veld Your current IP (Uw huidige IP) toont het IP-adres dat momenteel voor u geldig is, en dit hoort niet te veranderen. Dit is het adres dat u moet invullen in het veld IP 1.
2.9. Kan ik twee kopieën tegelijkertijd draaien?
Het draaien van twee kopieën op één machine is alleen mogelijk als ze verschillende poorten hebben ingesteld in het configuratiebestand.
Het gelijktijdig draaien van twee A-Parsers op verschillende machines is alleen mogelijk als u een extra IP heeft aangeschaft in het Ledengebied.
2.10. Is de scraper gekoppeld aan de hardware?
Nee. Voor licentiecontrole wordt uw IP-adres gebruikt.
2.11. Vraag over updaten - alleen .exe updaten? config/config.db en files/Rank-CMS/apps.json - waar zijn deze bestanden voor?
Tenzij anders aangegeven, alleen .exe bijwerken. Het eerste bestand is voor het opslaan van de A-Parser configuratie, en het tweede is de database voor het bepalen van CMS en de eigenlijke werking van de scraper ![]() Rank::CMS.
Rank::CMS.
2.12. Ik heb Win Server 2008 Web Edition - de scraper start niet...
A-Parser werkt niet op deze OS-versie. De enige optie is om van OS te veranderen.
2.13. Ik heb een 4-core processor. Waarom gebruikt A-Parser slechts één kern?
A-Parser gebruikt 2 tot 4 kernen; extra kernen worden alleen gebruikt bij filtering, de Resultatenbouwer en Parse custom result.
2.14. Ik krijg de foutmelding segmentatiefout (segmentation failed, segmentation error). Wat te doen?
Waarschijnlijk is uw IP gewijzigd. Controleer dit in het Ledengebied.
2.15. Ik heb Linux. A-Parser is gestart, maar opent niet in de browser. Hoe los ik dit op?
Controleer de firewall - waarschijnlijk blokkeert deze de toegang.
2.16. Ik heb Windows 7. A-Parser is gestart, maar opent niet in de browser en in taakbeheer staat geen Node.js proces. Hoe los ik dit op?
U moet de Windows-updates controleren en de laatst beschikbare installeren. Specifiek is de Windows 7 SP1 update vereist.
2.17. A-Parser start niet en in aparser.log staat de fout FATAL: padding_depad failed: Invalid argument provided. at ./Crypt/Mode/CBC.pm line 20.
Waarschijnlijk is er een probleem met een taak (map /config/tasks/) als gevolg van een schijffout (bijvoorbeeld als de pc is uitgeschakeld zonder correct af te sluiten). Meer details zijn te vinden door A-Parser te starten met de vlag -morelogs.
Oplossing: start A-Parser met de parameter -stoptasks. Als dat niet helpt, maak dan de hele map /config/tasks/ leeg. Als het probleem daarna nog steeds niet is opgelost, installeer de scraper dan opnieuw in een nieuwe map en zet de configuratie van de oude over (mits deze niet beschadigd is).
3. Vragen over de configuratie van A-Parser en andere instellingen
3.1. Hoe de proxychecker in te stellen?
Gedetailleerde instructies vindt u hier: proxy-instellingen.
3.2. Geen actieve proxy's - waarom?
Controleer uw internetverbinding en de instellingen van de proxychecker. Als alles correct is ingesteld, betekent dit dat uw proxylijst momenteel geen werkende servers bevat. Oplossing: gebruik andere proxy's of probeer het later opnieuw. Als u onze proxy's gebruikt, controleer dan het IP-adres in het Ledengebied onder de sectie Proxies (Proxy). Het is ook mogelijk dat uw provider de toegang tot andere DNS-servers blokkeert; probeer de stappen die hier beschreven staan: http://a-parser.com/threads/1240/#post-3582
3.3. Hoe Antigate te koppelen?
Gedetailleerde instructies voor de configuratie van Antigate vindt u hier.
3.4. Ik heb parameters gewijzigd in de scraper-instellingen, maar ze zijn niet toegepast. Waarom?
De standaard preset (default) kan niet worden gewijzigd. Als er wijzigingen zijn aangebracht, moet u op Save as New Preset (Opslaan als nieuwe preset) klikken en deze vervolgens in uw taak gebruiken.
3.5. Kan ik de instellingen van een actieve taak wijzigen?
Dat kan, maar niet voor alle instellingen. In een actieve taak kunt u op pauze klikken en in het dropdownmenu kiezen voor Edit (Bewerken).
3.6. Hoe een preset importeren?
Klik op de knop naast het taakselectieveld in de Taakeditor. Details hier.
3.7. Hoe de scraper instellen zodat deze geen proxy gebruikt?
Vink in de instellingen van de betreffende scraper de optie Use proxy uit.
3.8. Ik heb geen knop Overschrijving toevoegen / Override option!
Deze optie kan direct in de Taakeditor worden toegevoegd. Scraper-opties.
3.9. Hoe overschrijf ik hetzelfde resultatenbestand?
Stel bij het aanmaken van de taak de optie Overwrite file (Bestand overschrijven) in.
3.10. Waar wijzig ik het wachtwoord voor de scraper?
3.11. Ik heb 6 miljoen zoekwoorden ingesteld voor scraping en aangegeven dat alle domeinen uniek moeten zijn. Hoe zorg ik ervoor dat als ik nieuwe 6 miljoen zoekwoorden instel, alleen unieke domeinen worden opgeslagen die niet overlappen met de vorige scraping?
U moet de optie Keep unique (Deduplicatie opslaan) gebruiken bij het opstellen van de eerste taak en de opgeslagen database opgeven in de tweede. Details in Extra opties van de taakeditor.
3.12. Hoe omzeil ik de limiet van 1000 resultaten voor Google?
Gebruik de optie Sparseer alle resultaten / Parse all results.
3.13. Hoe omzeil ik de limiet van 1024 threads op Linux?
3.14. Wat is de threadlimiet op Windows?
Tot 10.000 threads.
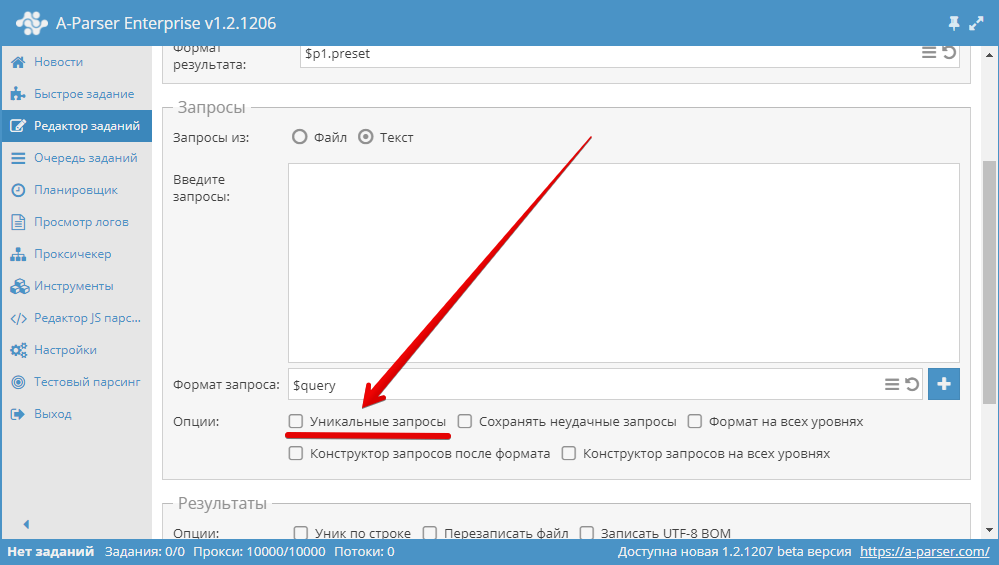
3.15. Hoe maak ik zoekopdrachten uniek?
Gebruik de optie Unique queries (Unieke zoekopdrachten) in het blok Queries (Zoekopdrachten) in de Taakeditor.
3.16. Hoe schakel ik de proxycontrole uit?
Kies in Instellingen - Proxychecker instellingen de gewenste proxychecker en vink No check proxies (Proxy's niet controleren) aan. Sla dit op en kies de opgeslagen preset.
3.17. Wat is Proxy ban time? Kan ik dit op 0 zetten?
De tijd dat een proxy verbannen blijft in seconden. Ja, dat kan.
3.18. Wat is het verschil tussen Exact Domain en Top Level Domain in de scraper  SE::Google::Position
SE::Google::Position
Exact Domain is een strikte overeenkomst, d.w.z. als de resultaten www.domain.com tonen en we zoeken naar domain.com, dan is er geen overeenkomst. Top Level Domain vergelijkt het hele topdomein, dus hier zal wel een overeenkomst zijn.
3.19. Als ik een test-scraping start werkt alles, maar bij een normale krijg ik de fout Some error.
Waarschijnlijk is er een probleem met de DNS; probeer deze instructie voor DNS-configuratie te volgen.
3.20. Waar wordt het Resultaatformaat ingesteld?
Gebruik bij het formatteren van het resultaat \n. Voorbeeld:
3.21. In  SE::Google ontbreekt de Nederlandse taal, hoewel deze wel in de Google-instellingen staat. Waarom?
SE::Google ontbreekt de Nederlandse taal, hoewel deze wel in de Google-instellingen staat. Waarom?
De Nederlandse taal is Dutch, deze staat in de lijst. Details in de verbetering over het toevoegen van de Nederlandse taal.
4. Vragen over gegevensextractie en fouten tijdens het scrapen
4.1. Wat zijn threads?
Alle moderne processors kunnen taken in meerdere threads uitvoeren, wat de snelheid van de uitvoering aanzienlijk verhoogt. Ter vergelijking kun je een gewone bus nemen die per tijdseenheid een bepaald aantal mensen vervoert - dit zou een gewone, single-threaded verwerking zijn, en een dubbeldekkerbus die in dezelfde tijd twee keer zoveel mensen vervoert - dit zou multithreading verwerking zijn. A-Parser kan tot 10000 threads tegelijkertijd verwerken.
4.2. Taak start niet - melding Some Error - waarom?
Controleer het IP-adres in het Ledengebied.
4.3. Alle zoekopdrachten mislukken, wat te doen?
Waarschijnlijk is de taak onjuist samengesteld of wordt er een verkeerd query-formaat gebruikt. Controleer ook of er werkende proxy's zijn. Je kunt ook proberen de optie Request retries te verhogen (details hier: mislukte verzoeken).
4.4. Hoeveel accounts moeten er geregistreerd worden om 1.000.000 trefwoorden te scrapen met  SE::Yandex::Wordstat?
SE::Yandex::Wordstat?
Het is niet precies te zeggen hoeveel accounts er nodig zijn, omdat een account na een onbekend aantal verzoeken onbruikbaar kan worden. Maar je kunt altijd nieuwe accounts registreren met de scraper  SE::Yandex::Register of gewoon bestaande accounts toevoegen aan het bestand files/SE-Yandex/accounts.txt.
SE::Yandex::Register of gewoon bestaande accounts toevoegen aan het bestand files/SE-Yandex/accounts.txt.
4.5. Taak start niet, melding Error: Lock 100 threads failed(20 of limit 100 used) wat te doen?
Het is noodzakelijk om het maximaal beschikbare aantal threads in de scraper-instellingen te verhogen, of in de taakinstellingen te verlagen. Details in Instellingen.
4.6. Kunnen er 2 taken tegelijkertijd worden uitgevoerd?
Ja, A-Parser ondersteunt het gelijktijdig uitvoeren van meerdere taken. Het aantal gelijktijdig werkende taken wordt geregeld in Instellingen - Algemene instellingen: Maximum actieve taken.
4.7. Waar staat het bestand met resultaten?
Op het tabblad Tasks Queue (Taakwachtrij) kunt u na afloop van elke taak de resultaten downloaden. Fysiek bevinden deze zich in de map results.
4.8. Kan ik het resultatenbestand downloaden als het scrapen nog niet klaar is?
Nee, zolang de gegevensextractie niet is voltooid, kunnen de resultaten niet worden gedownload. Maar het kan wel worden gekopieerd uit de map aparser/results wanneer de taak is gestopt of gepauzeerd.
4.9. Kan ik met uw scraper 1.000.000 links scrapen voor één zoekopdracht?
Ja, door de optie Sparseer alle resultaten / Parse all results te gebruiken.
4.10. Is het mogelijk om  Rank::CMS,
Rank::CMS,  Net::Whois te scrapen zonder proxy?
Net::Whois te scrapen zonder proxy?
Net::Whois - niet wenselijk.4.11. Hoe links van Google scrapen?
Het is noodzakelijk om SE::Google te gebruiken.
4.12. Kan de scraper links volgen?
Ja, de scraper  HTML::LinkExtractor kan dit doen bij gebruik van de optie Sparseer tot niveau / Parse to level
HTML::LinkExtractor kan dit doen bij gebruik van de optie Sparseer tot niveau / Parse to level
4.13. Google scrapen gaat erg traag, wat te doen?
Allereerst moet u de taaklogs bekijken, mogelijk zijn alle verzoeken mislukt. Als dat zo is, moet u de reden vinden waarom de verzoeken mislukken en dit herstellen. Bij gegevensextractie met SE::Google zijn mislukte pogingen in de taaklogs vaak gerelateerd aan het feit dat Google captcha's toont, dit is normaal. U kunt Antigate koppelen om captcha's te omzeilen, zodat de scraper niet blijft proberen.
Er is ook een artikel waarin factoren worden beschreven die de snelheid van gegevensextractie beïnvloeden en hoe ze dat doen: snelheid en werkingsprincipe van scrapers.
4.14. Kan ik met uw scraper links scrapen waarvan de tekst alleen in het Japans is?
Ja, hiervoor moet u in de scraper-instellingen de gewenste taal instellen en ook Japanse trefwoorden gebruiken.
4.15. Kan ik met uw scraper alleen links scrapen in de domeinzone .de of .ru?
Ja. Hiervoor moet u een filter gebruiken.
4.16. Hoe krijg ik elk resultaat in het bestand op een nieuwe regel?
Gebruik bij de resultaat-formattering \n. Voorbeeld:
$serp.format('$link\n')
4.17. Hoe de top 10 sites van Google scrapen?
Hier is de preset:
eyJwcmVzZXQiOiJUT1AxMCIsInZhbHVlIjp7InByZXNldCI6IlRPUDEwIiwicGFy
c2VycyI6W1siU0U6Okdvb2dsZSIsImRlZmF1bHQiLHsidHlwZSI6Im92ZXJyaWRl
IiwiaWQiOiJwYWdlY291bnQiLCJ2YWx1ZSI6MX0seyJ0eXBlIjoib3ZlcnJpZGUi
LCJpZCI6ImxpbmtzcGVycGFnZSIsInZhbHVlIjoxMH0seyJ0eXBlIjoib3ZlcnJp
ZGUiLCJpZCI6InVzZXByb3h5IiwidmFsdWUiOmZhbHNlfV1dLCJyZXN1bHRzRm9y
bWF0IjoiJHAxLnByZXNldCIsInJlc3VsdHNTYXZlVG8iOiJmaWxlIiwicmVzdWx0
c0ZpbGVOYW1lIjoiJGRhdGVmaWxlLmZvcm1hdCgpLnR4dCIsImFkZGl0aW9uYWxG
b3JtYXRzIjpbXSwicmVzdWx0c1VuaXF1ZSI6Im5vIiwicXVlcnlGb3JtYXQiOlsi
JHF1ZXJ5Il0sInVuaXF1ZVF1ZXJpZXMiOmZhbHNlLCJzYXZlRmFpbGVkUXVlcmll
cyI6ZmFsc2UsIml0ZXJhdG9yT3B0aW9ucyI6eyJvbkFsbExldmVscyI6ZmFsc2Us
InF1ZXJ5QnVpbGRlcnNBZnRlckl0ZXJhdG9yIjpmYWxzZX0sInJlc3VsdHNPcHRp
b25zIjp7Im92ZXJ3cml0ZSI6ZmFsc2V9LCJkb0xvZyI6Im5vIiwia2VlcFVuaXF1
ZSI6Ik5vIiwibW9yZU9wdGlvbnMiOmZhbHNlLCJyZXN1bHRzUHJlcGVuZCI6IiIs
InJlc3VsdHNBcHBlbmQiOiIiLCJxdWVyeUJ1aWxkZXJzIjpbXSwicmVzdWx0c0J1
aWxkZXJzIjpbXSwiY29uZmlnT3ZlcnJpZGVzIjpbXX19
4.18. Ik voeg een taak toe, ga naar het tabblad Taakwachtrij - maar hij staat er niet! Waarom?
Of er is een fout gemaakt bij het opstellen van de taak, of deze is al voltooid en verplaatst naar Completed (Voltooid).
4.19. Er staat dat het bestand niet in utf-8 is, maar ik heb het niet gewijzigd en het is al utf-8, wat te doen?
Controleer het nogmaals. Probeer ook de codering te wijzigen, bijvoorbeeld met Notepad++.
4.20. In het resultatenbestand staat alles op één regel, hoewel ik in de taak een regeleinde had ingesteld - waarom?
In de aanvullende instellingen van A-Parser moet de regeleinde CRLF (Windows) worden gebruikt.
Maar als u al heeft gescraped zonder deze optie, gebruik dan een geavanceerdere viewer om te bekijken, bijvoorbeeld Notepad++.
4.21. Hoeveel tijd kost het om de zoekfrequentie bij Yandex te controleren voor 1.000 zoekopdrachten?
Deze indicator is erg afhankelijk van de taakparameters, serverkenmerken, kwaliteit van de proxy's, enz., dus een eenduidig antwoord is niet te geven.
4.22. Hoe stel ik de scraper in zodat het resultaat 'zoekopdracht-link' is?
Resultaat-formaat:
$p1.serp.format('$query: $link\n')
Het resultaat zal zijn:
zoekopdracht: link 1
zoekopdracht: link 2
zoekopdracht: link 3
4.23. Hoe kan ik mislukte zoekopdrachten opnieuw scrapen en waar worden ze bewaard?
Om mislukte verzoeken op te slaan, moet u de bijbehorende optie selecteren in het blok Queries (Verzoeken) in de Taakeditor. Mislukte verzoeken worden opgeslagen in queries\failed. U moet een nieuwe taak maken en als verzoekenbestand het bestand met mislukte verzoeken opgeven.
4.24. Hoe verwijder ik HTML-tags bij het scrapen van tekst?
Gebruik de optie Remove HTML tags in de Resultatenbouwer.
4.25. Hoe zorg ik ervoor dat alleen domeinen worden gescraped?
Gebruik de optie Extract Domain in de Resultatenbouwer.
4.26. Wat is de maximale bestandsgrootte voor zoekopdrachten die in de scraper kan worden gebruikt?
De bestandsgrootte van verzoeken en resultaten is onbeperkt en kan terabytes bereiken.
4.27. Waarom geeft de scraper 'Queries length limited to 8192 characters' als ik tekst invoer in het zoekveld?
Dit gebeurt omdat de lengte van een verzoek beperkt is tot 8192 tekens. Om langere verzoeken te gebruiken, moet u bestanden als verzoeken gebruiken.
4.28. Wat betekent 'Wachtende threads - 3'?
Dit betekent dat er onvoldoende proxy's zijn. Verminder het aantal threads of verhoog het aantal proxy's.
4.29. In de test-scraping staat '596 SOCKS proxy error: Hello read error(Connection reset by peer) (0 KB)' en hij scrapet niet, waarom?
Dit duidt op niet-werkende proxy's.
4.30. Wat is het verschil tussen de taal van de resultaten en het zoekland in de Google scraper?
Het verschil is als volgt: het zoekland is de koppeling van de resultaten aan een specifiek land. Als je bijvoorbeeld zoekt op ramen kopen met koppeling aan een specifiek land, krijgen sites die in dat land ramen aanbieden voorrang. De taal van de resultaten geeft daarentegen aan in welke taal de resultaten moeten worden weergegeven.
4.31. Een bepaalde site wordt niet gescraped. Wat kan er aan de hand zijn?
Vaak is het probleem dat er een blokkade optreedt vanwege een oude user-agent aan de serverzijde. Dit wordt opgelost met een nieuwe user-agent of de volgende code in de parameter User agent:
[% tools.ua.random() %]
4.32. De scraper loopt vast of crasht. In het log staat de regel 'syswrite: No space left on device'.
A-Parser heeft onvoldoende ruimte op de harde schijf. Maak meer ruimte vrij.
4.33. Mijn scraper geeft 'none' in de resultaten (of een duidelijk onjuist resultaat).
4.34. Er verschijnt constant een venster met de tekst 'Failed fetch news'.
4.35. Hoe de eerste n resultaten van de zoekresultaten weergeven?
4.36. Hoe een keten van redirects volgen?
4.37. Hoe controleer ik of een link op een donor-site is geïndexeerd?
Voor dergelijke doeleinden bestaat er een aparte scraper:  Check::BackLink.
Details in de discussie.
Check::BackLink.
Details in de discussie.
4.38. De scraper crasht op Linux. In het log staat: 'EV: error in callback (ignoring): syswrite() on closed filehandle at AnyEvent/Handle.pm line...'.
Waarschijnlijk moet het aantal threads worden getuned, zoals beschreven in de Documentatie: Linux tuning voor meer threads.
4.39. Waar kan ik alle mogelijke parameters vinden voor gebruik via de API?
API-verzoek verkrijgen in de interface.
Ook kan een volledige taakconfiguratie in JSON worden gegenereerd. Hiervoor moet u de taakcode nemen en deze decoderen uit base64.
4.40. Ik download afbeeldingen met  Net::HTTP, maar ze zijn op de een of andere manier allemaal corrupt. Wat te doen?
Net::HTTP, maar ze zijn op de een of andere manier allemaal corrupt. Wat te doen?
1) Controleer de parameter Max body size - misschien moet deze worden verhoogd. 2) Controleer in de A-Parser instellingen het formaat van de regeleinde: Aanvullende instellingen - Regeleinde.
Om te voorkomen dat de afbeelding corrupt is, moet het UNIX-formaat worden gebruikt.
4.41. Hoe krijg ik het admin-contact uit WHOIS?
Een dergelijke taak is eenvoudig op te lossen met de functie Parse custom result en een reguliere expressie. Details in de discussie.
4.42. Reguliere expressie voor het scrapen van telefoonnummers
4.43. Identificatie van sites zonder mobiele versie
4.44. Hoe de naam van de ns-server achterhalen?
4.45. Hoe links naar de Yandex-cache scrapen?
4.46. Hoe links naar alle pagina's van een site scrapen?
4.47. Hoe de title van een pagina scrapen?
4.48. Hoe alle sites in een bepaalde domeinzone scrapen?
4.49. Hoe alle url's met parameters verzamelen?
4.50. Hoe resultaten filteren op meerdere kenmerken en deze verdelen in het rapport?
4.51. Hoe de filterconstructie vereenvoudigen?
4.52. Hoe sorteren naar bestanden afhankelijk van het resultaat?
4.53. Maak elke X aantal bestanden een nieuwe resultatenmap aan
4.54. Eerste stappen met WordStat
4.55. Verzamelen van tekstblokken >1000 tekens
4.56. Een bepaalde hoeveelheid tekst van een pagina weergeven
Dit kan ook worden opgelost met Template Toolkit. Details in de discussie.
4.57. Controle van concurrentie en keyword-in-title in Google
4.58. Filteren op het aantal voorkomens van de zoekopdracht in anker en snippet
4.59. Hoe de inhoud van een artikel op één regel krijgen?
4.60. Hoe twee datums als strings vergelijken?
4.61. Hoe gemarkeerde woorden uit de snippet scrapen?
4.62. Voorbeeld van een taak met gebruik van meerdere scrapers
4.63. Hoe regels in het resultaat husselen en hoe een willekeurig aantal resultaten weergeven?
4.64. Hoe het resultaat ondertekenen met MD5?
4.65. Hoe een datum omzetten van Unix timestamp naar een string-weergave?
4.66. Parse to level, hoe te scrapen met beperking?
4.67. Scraper crasht op Linux bij het starten van een taak. In het log staan regels als: 'Can't call method "if_list" on an undefined value at IO/Interface/Simple.pm...'.
In de console moet het volgende commando worden uitgevoerd:
apt-get --reinstall --purge install netbase
4.68. Fout Cannot init Parser: Error: Failed to launch the browser process! [0429/082706.472999:ERROR:zygote_host_impl_linux.cc(90)] Running as root without --no-sandbox is not supported...
U moet A-Parser niet als root uitvoeren. Namelijk: vanaf de root-gebruiker moet u een nieuwe gebruiker aanmaken zonder root-rechten (als die er al is, gebruik die dan gewoon) en die gebruiker vervolgens toestemming geven om met de A-Parser map te werken, daarna inloggen als de nieuwe gebruiker en van daaruit opstarten.
Maak onder de gebruiker root een gebruiker aan, dit kan volgens deze gids.
Om de aangemaakte gebruiker toestemming te geven om met de A-Parser map te werken, moet u de gebruiker rechten geven. Ga hiervoor naar de root-gebruiker en geef rechten met het commando:
chown -R user:user aparser
4.69. Fout Cannot init Parser: Error: Failed to launch the browser process! [0429/102002.619437:FATAL:zygote_host_impl_linux.cc(117)] No usable sandbox! Update your kernel or see...
Voer onder de gebruiker root het commando uit:
sysctl -w kernel.unprivileged_userns_clone=1
Herstarten van A-Parser is niet vereist.
Voor CentOS 7 staat de oplossing in dit topic.
Voer onder de root gebruiker het commando uit:
echo "user.max_user_namespaces=15000" >> /etc/sysctl.conf
Herstart vervolgens sysctl met het commando:
sysctl -p
4.70. Fout JavaScript execution error(): Error: Failed to launch the browser process! /aparser/dist/nodejs/node_modules/puppeteer/.local-chromium/linux-884014/chrome-linux/chrome: error while loading shared libraries: libatk-1.0.so.0: cannot open shared object file: No such file or directory...
De fout treedt op door het ontbreken van bibliotheken in het besturingssysteem voor de werking van Chrome.
De lijst met benodigde bibliotheken voor de werking van Chrome is te vinden in Chrome headless doesn't launch on UNIX.
4.71. Waarom wordt de captcha niet opgelost? In het log is te zien dat A-Parser vraagtekens van Xevil heeft ontvangen in plaats van het captcha-antwoord
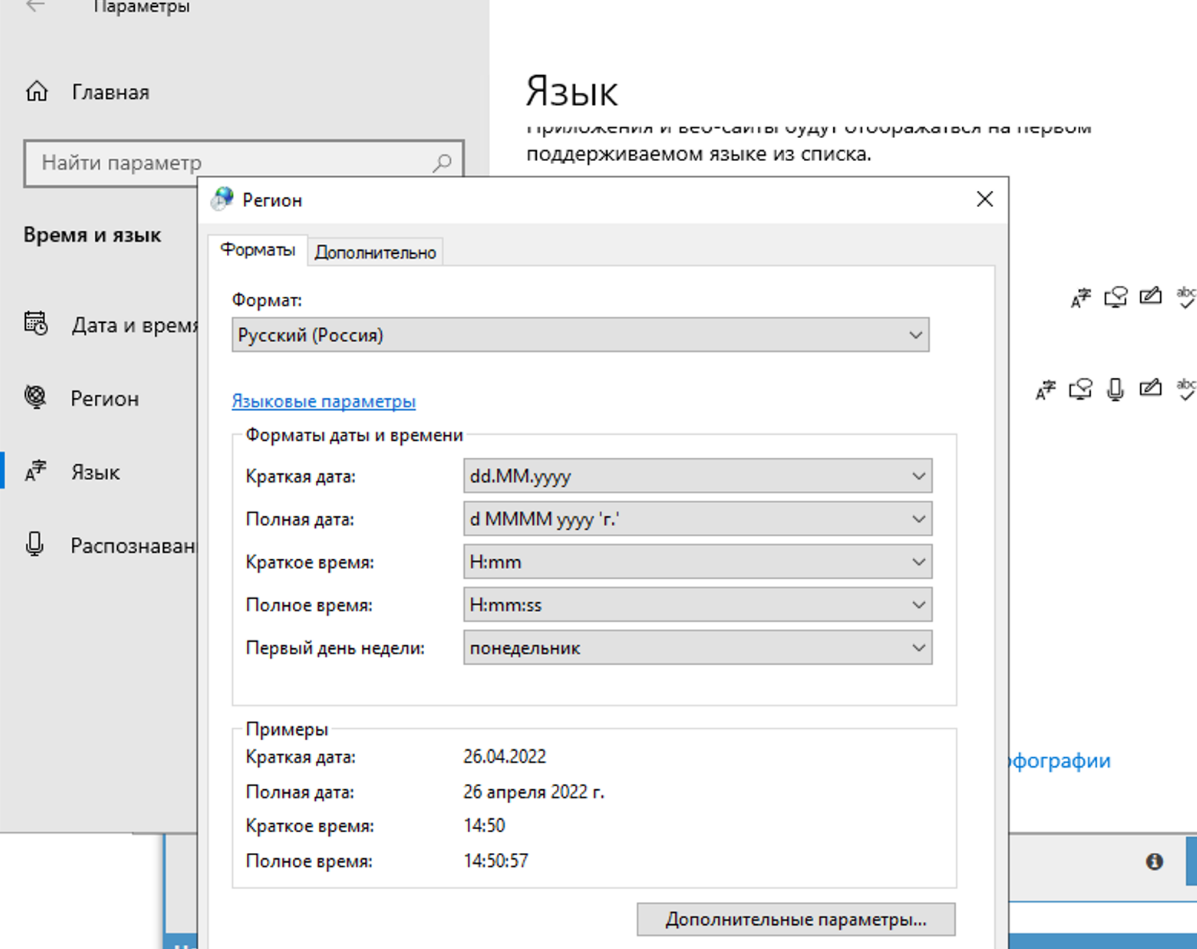
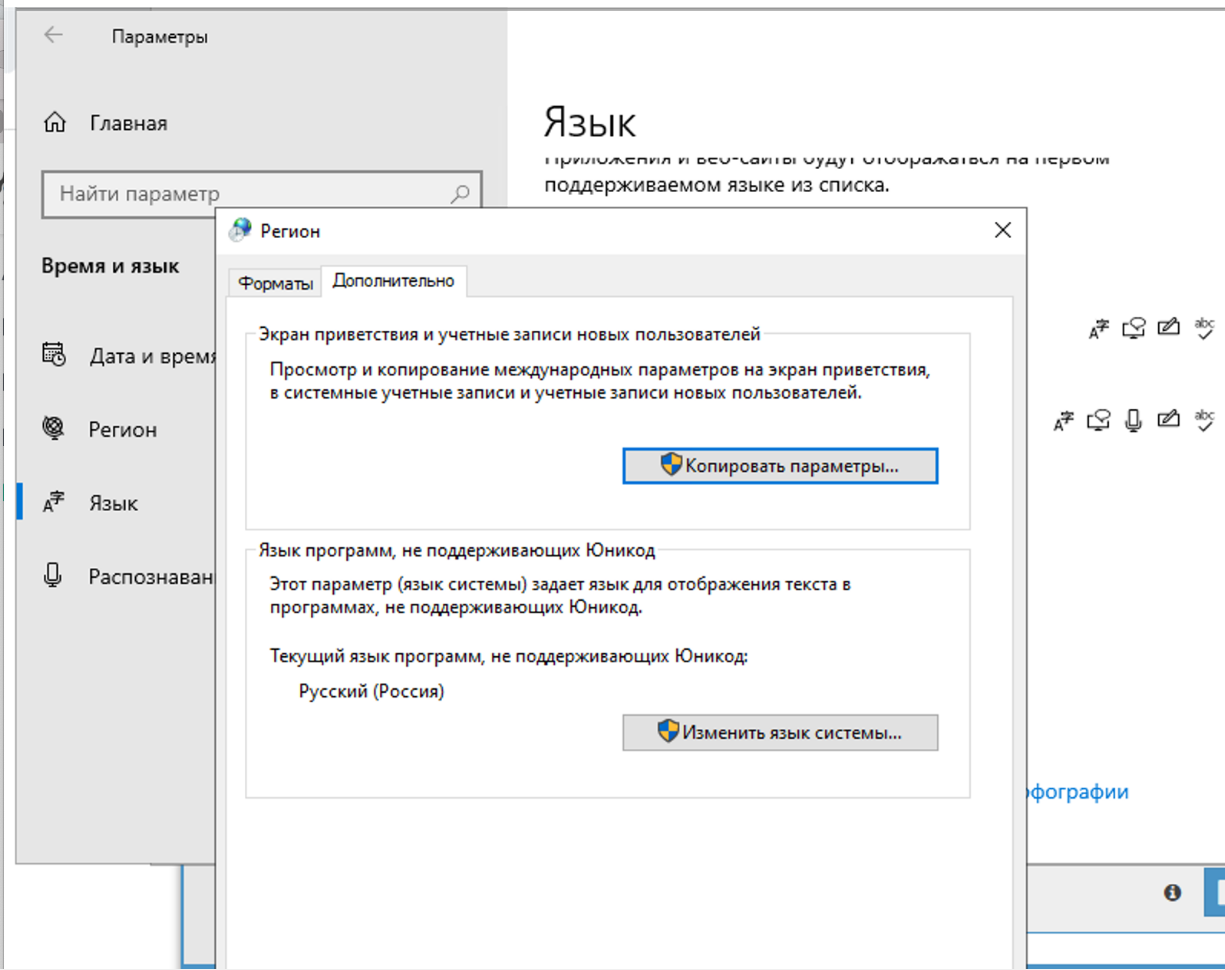
In de regio-instellingen moet dit worden gewijzigd naar Russisch.
Dit hoeft alleen op het tabblad geavanceerd te worden gewijzigd. Dit heeft geen invloed op het oplossen van captcha's, maar in Xumer zelf zal er een probleem zijn met de codering als het op beide plaatsen wordt gewijzigd.