Construtor de Resultados
Result Builders (Construtor de resultados) - permite transformar os resultados de cada scraper antes da sua formatação e salvamento no disco
Recursos
- Divisão do resultado em partes usando uma expressão regular ou um delimitador arbitrário
- Substituição de substring no resultado ou substituição por expressão regular
- Extração do domínio ou do domínio principal a partir de um link
- Conversão do resultado para maiúsculas/minúsculas
- Remoção de tags HTML (
<b>text</b>->text) - Conversão de entidades HTML em seus equivalentes Unicode (
©->©) - Obtenção de dados usando consultas XPath
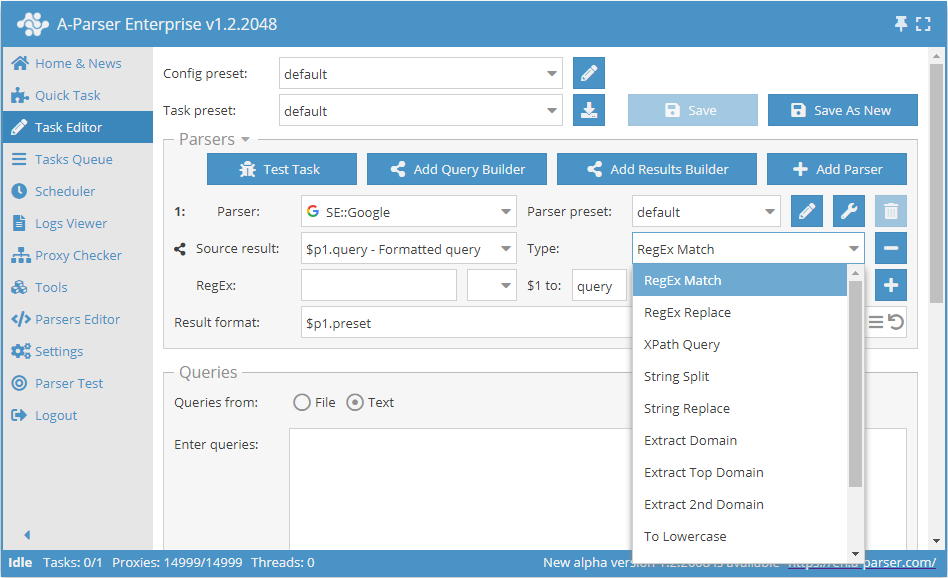
Exemplos
Extração de dados de domínios
Salvar apenas domínios ao extrair links de sistemas de busca:
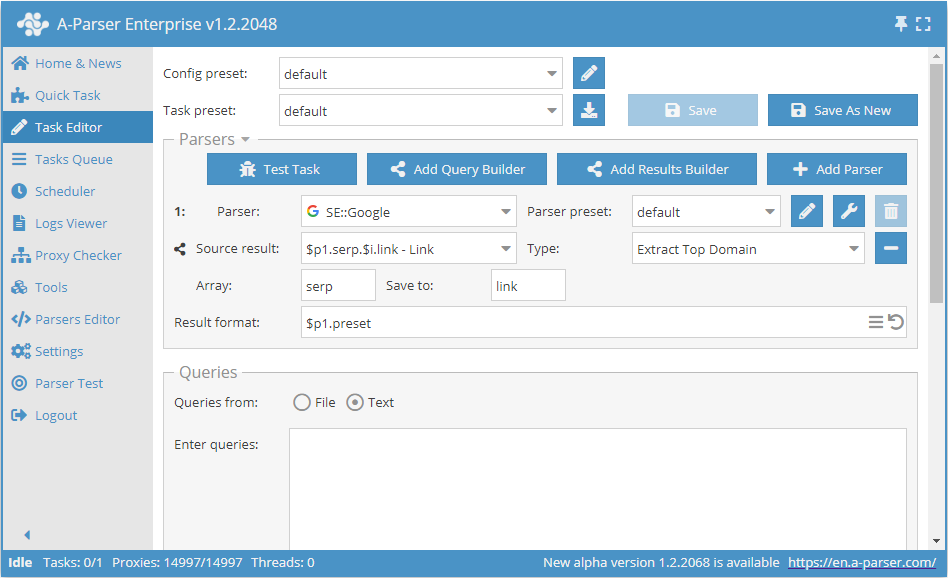
Como fonte, são utilizados os elementos link da array serp do primeiro scraper; a cada elemento será aplicada a função de extração do domínio principal do link, o novo resultado será salvo sob o mesmo nome (elemento link na array serp) - portanto, não é necessário alterar o formato do resultado
Extração de dados de snippets com limpeza
Salvar snippets de sistemas de busca com limpeza de tags HTML e conversão de entidades HTML
Por padrão, âncoras e snippets são extraídos com todas as tags aninhadas, o que permite manter a mesma formatação de quando se visualiza os resultados nos sistemas de busca. Se for necessário apenas o texto limpo, pode-se utilizar os recursos do Construtor de resultados:
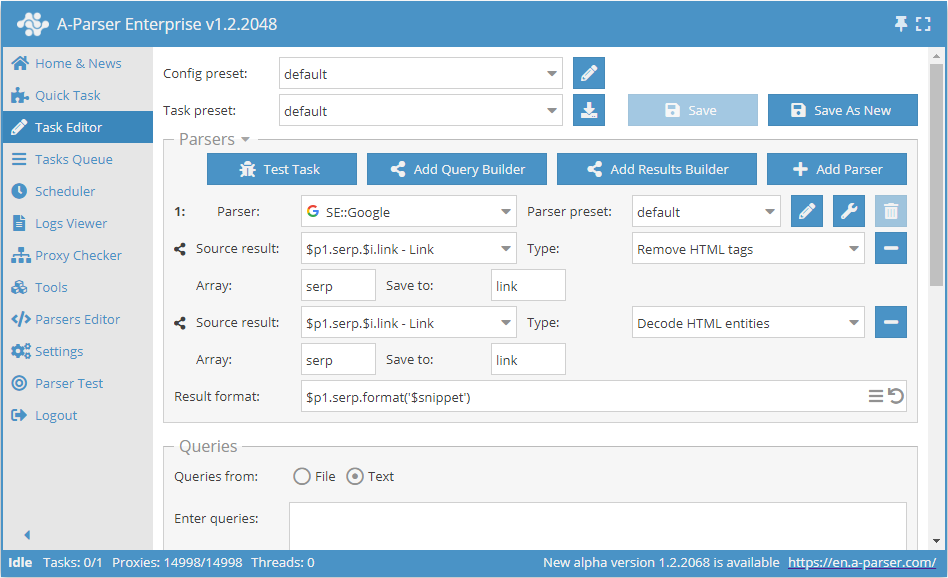
Neste exemplo, dois Construtores de resultados foram aplicados sequencialmente aos snippets - remoção de tags HTML e conversão de entidades HTML
Extração de dados com XPath
Extração de links dos resultados de busca usando XPath:
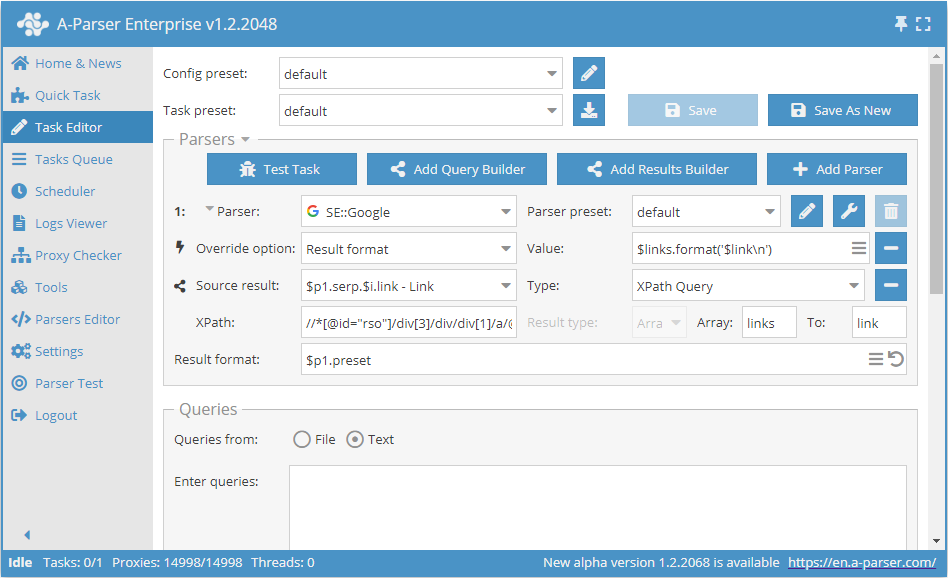
Neste exemplo, é mostrada a extração de links do buscador Google. É utilizada a consulta XPath:
//*[@id="rso"]/div[3]/div/div[1]/a/@href