Resultaatdeduplicatie
Deduplicatie, resultaatdeduplicatie, verwijderen van dubbele gegevens, verwijderen van herhalingen - dit alles houdt in dat we geen herhalende resultaten nodig hebben. In A-Parser zijn er 2 methoden voor deduplicatie, we zullen ze elk in detail bespreken.
Resultaatdeduplicatie per regel
Deze methode werkt na de resultaatvorming; direct voordat het resultaat naar het bestand wordt geschreven, wordt elke regel gecontroleerd op uniekheid en worden alleen nieuwe unieke regels in het bestand opgeslagen.
Zie ook: Volgorde van verwerking van query's
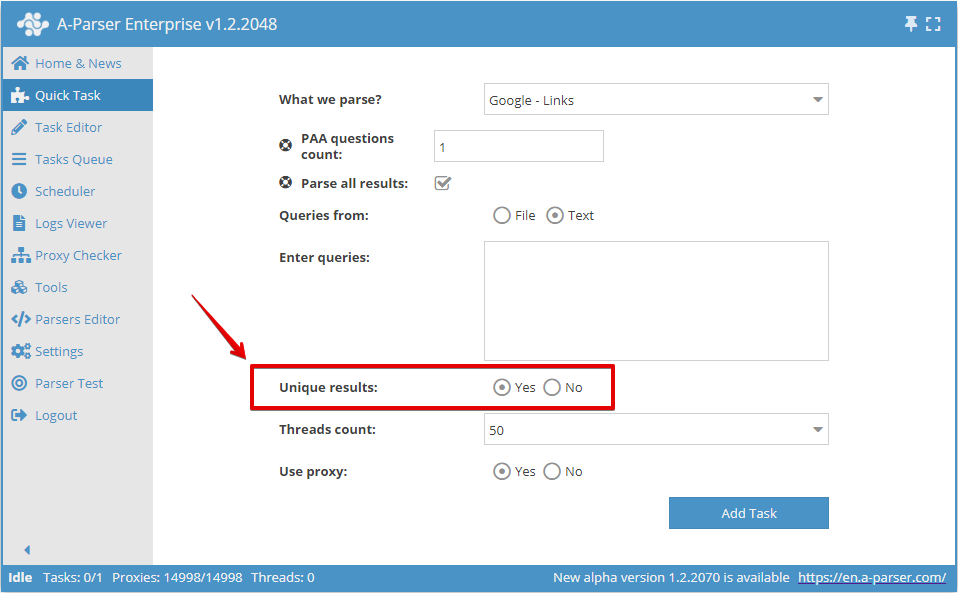
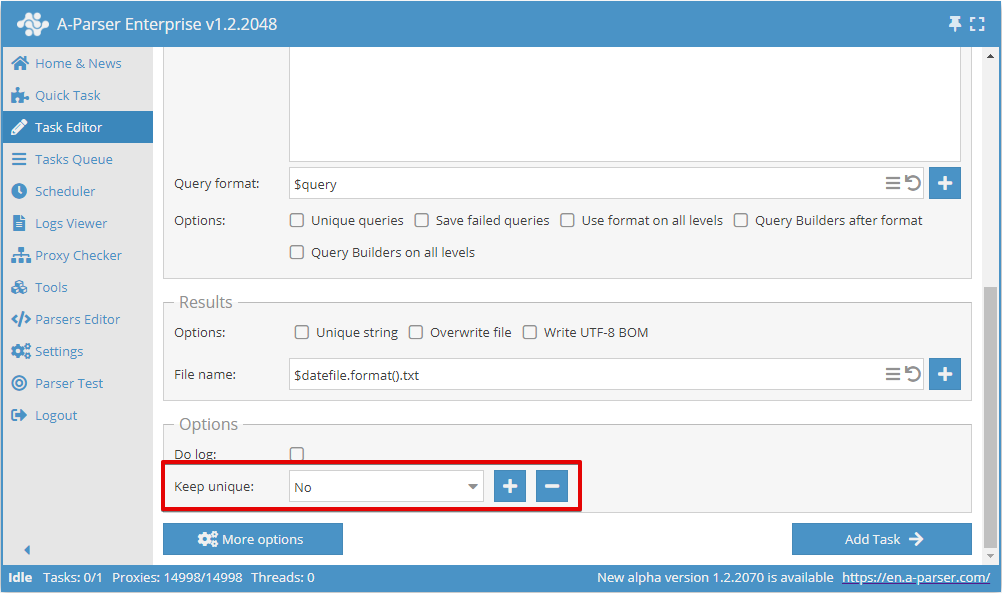
U kunt deduplicatie per regel inschakelen in de Snelle taak:
Of in de Taak-editor:
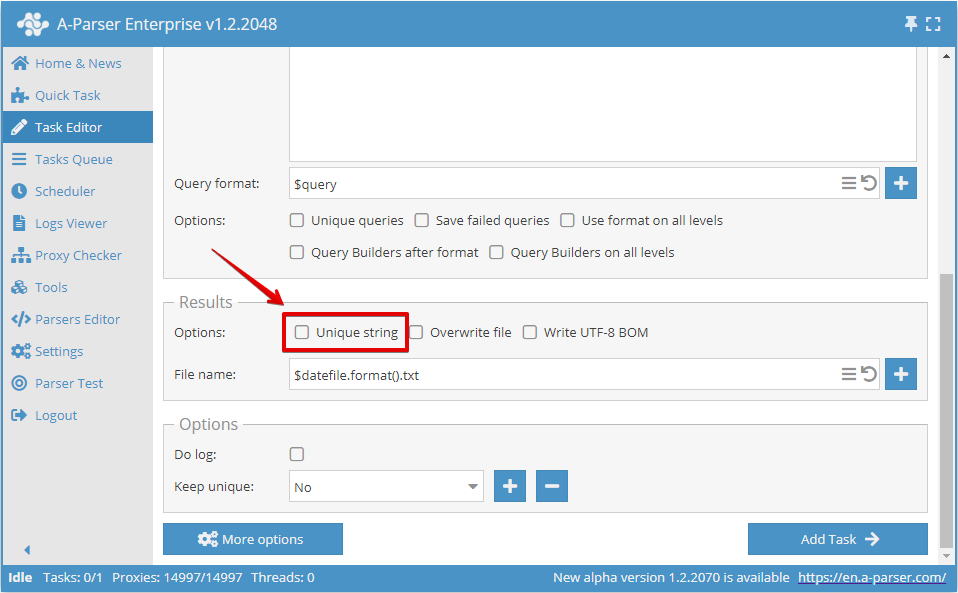
Deduplicatie op elk resultaat
Deduplicatie op elk resultaat maakt het mogelijk om deduplicatie direct toe te passen op een geselecteerd resultaat van een specifieke scraper. U kunt dit type deduplicatie toevoegen in de Taak-editor door op het gereedschapspictogram rechts van de scraper te klikken en op Add unique result (Deduplicatie toevoegen) te drukken:
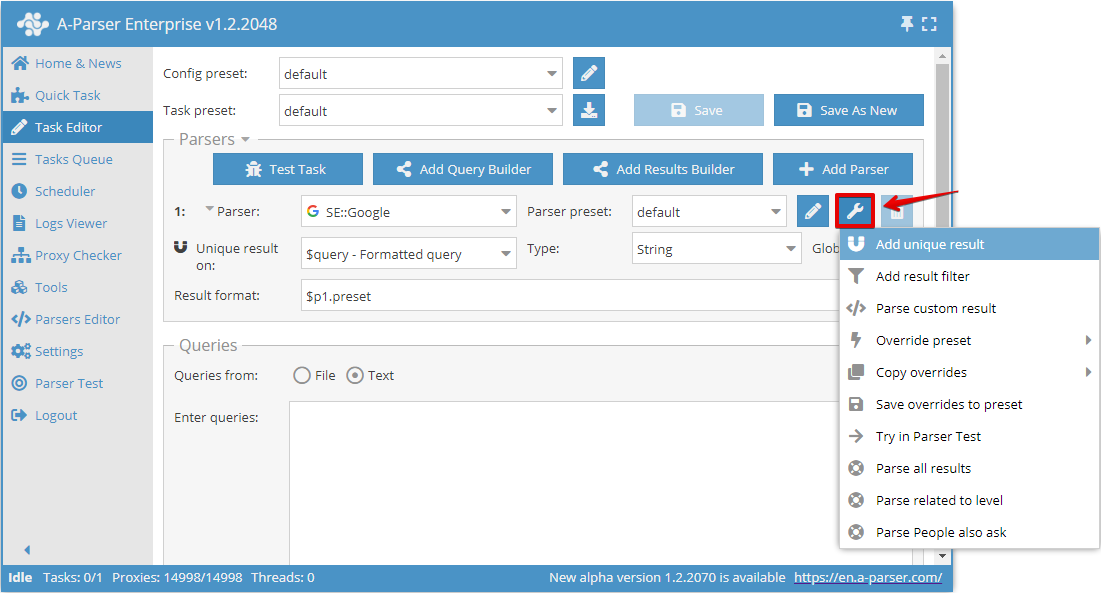
Nu kunt u kiezen op welk resultaat de deduplicatie moet worden uitgevoerd en het type deduplicatie selecteren:
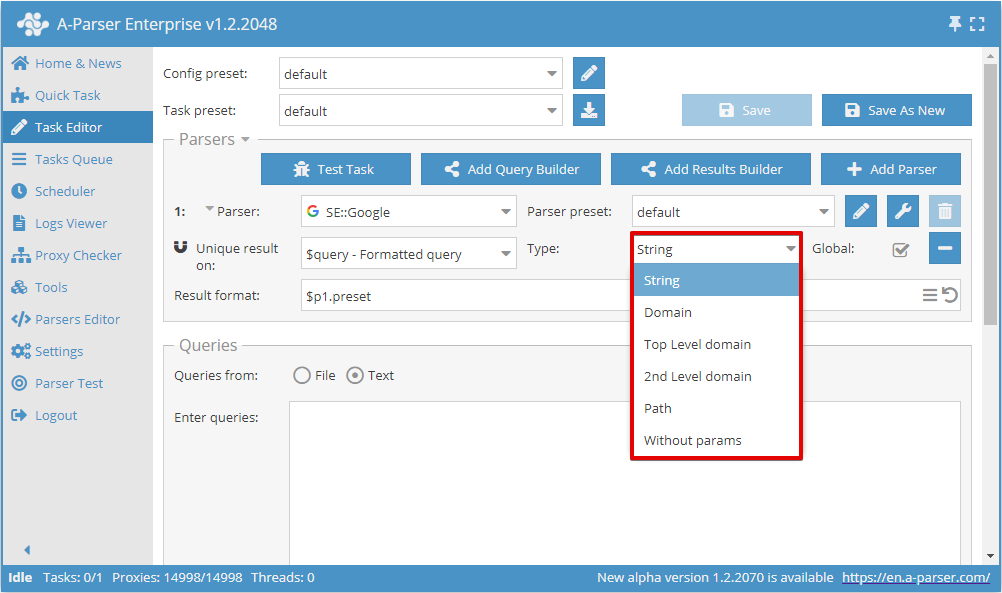
De schakelaar Global (Globaal) wordt gebruikt wanneer er 2 of meer scrapers zijn geselecteerd; deze bepaalt of er een gezamenlijke deduplicatie wordt uitgevoerd of per scraper afzonderlijk.
Type deduplicatie
| Parameter | Beschrijving |
|---|---|
| String | Deduplicatie per regel (de gehele resultaatregel wordt vergeleken) |
| Domain | Deduplicatie op domein (het volledige domein wordt vergeleken, bijvoorbeeld www.domain.com en domain.com zijn verschillende domeinen) |
| Top Level domain | Deduplicatie op hoofddomein rekening houdend met regionale, commerciële, educatieve en andere domeinen (bijvoorbeeld domain.co.uk en domain2.co.uk zijn verschillende domeinen, terwijl sub1.domain.com en sub2.domain.com hetzelfde zijn) |
| 2e niveau domein | Deduplicatie op domein van het tweede niveau (domeinen van het tweede niveau worden vergeleken, bijvoorbeeld www.domain.com, domain.com en user.subdomain.domain.com zijn allemaal hetzelfde domein) |
| Path | Deduplicatie op pad (delen van de link tot aan het bestand worden vergeleken, bijvoorbeeld http://domain.com/path1/file.php en http://domain.com/path1/file2.php zijn identieke delen van de link tot aan het bestand) |
| Without params | Deduplicatie op link zonder parameters (links zonder parameters worden vergeleken, bijvoorbeeld http://domain.com/file.php?page=1 en http://domain.com/file.php?page=2 zijn identieke links) |
Query-deduplicatie
Query-deduplicatie stuurt alleen unieke query's naar de gegevensextractie die nog niet eerder in de huidige taak zijn verwerkt. Belangrijkste use cases: In alle andere gevallen zal onnodig gebruik van query-deduplicatie de algehele snelheid van de scraper alleen maar vertragen
- Bij gebruik van de optie Parse to level (Scrapen tot niveau) is het gebruik van alleen unieke query's noodzakelijk om wildgroei en lussen in query's te voorkomen (bijvoorbeeld bij gebruik van de scraper
 HTML::LinkExtractor)
HTML::LinkExtractor)
Opslaan van deduplicatiestatus tussen taken
Opslaan van deduplicatiestatus tussen taken
Het is mogelijk om de deduplicatiedatabase op te slaan voor gebruik in toekomstige taken, waardoor in nieuwe taken alleen nieuwe unieke resultaten worden opgeslagen (bijvoorbeeld links bij de gegevensextractie van de SERP in  SE::Google)
SE::Google)
Om de deduplicatiedatabase op te slaan, moet u bij het toevoegen van de eerste taak een nieuwe databasenaam aanmaken:
Voor alle volgende taken moet de eerder aangemaakte databasenaam worden geselecteerd; hierdoor worden alleen nieuwe unieke resultaten opgeslagen, ongeacht of de resultaten in hetzelfde bestand als in de eerste taak of in een nieuw bestand worden weggeschreven.