Volgorde van query-verwerking
In A-Parser bestaan er vele functies en mogelijkheden; dit diagram toont de volgorde van verwerking van een query, van het lezen uit een bestand (of tekst) tot het opslaan van het eindresultaat in een bestand.
Schematische volgorde van queryverwerking
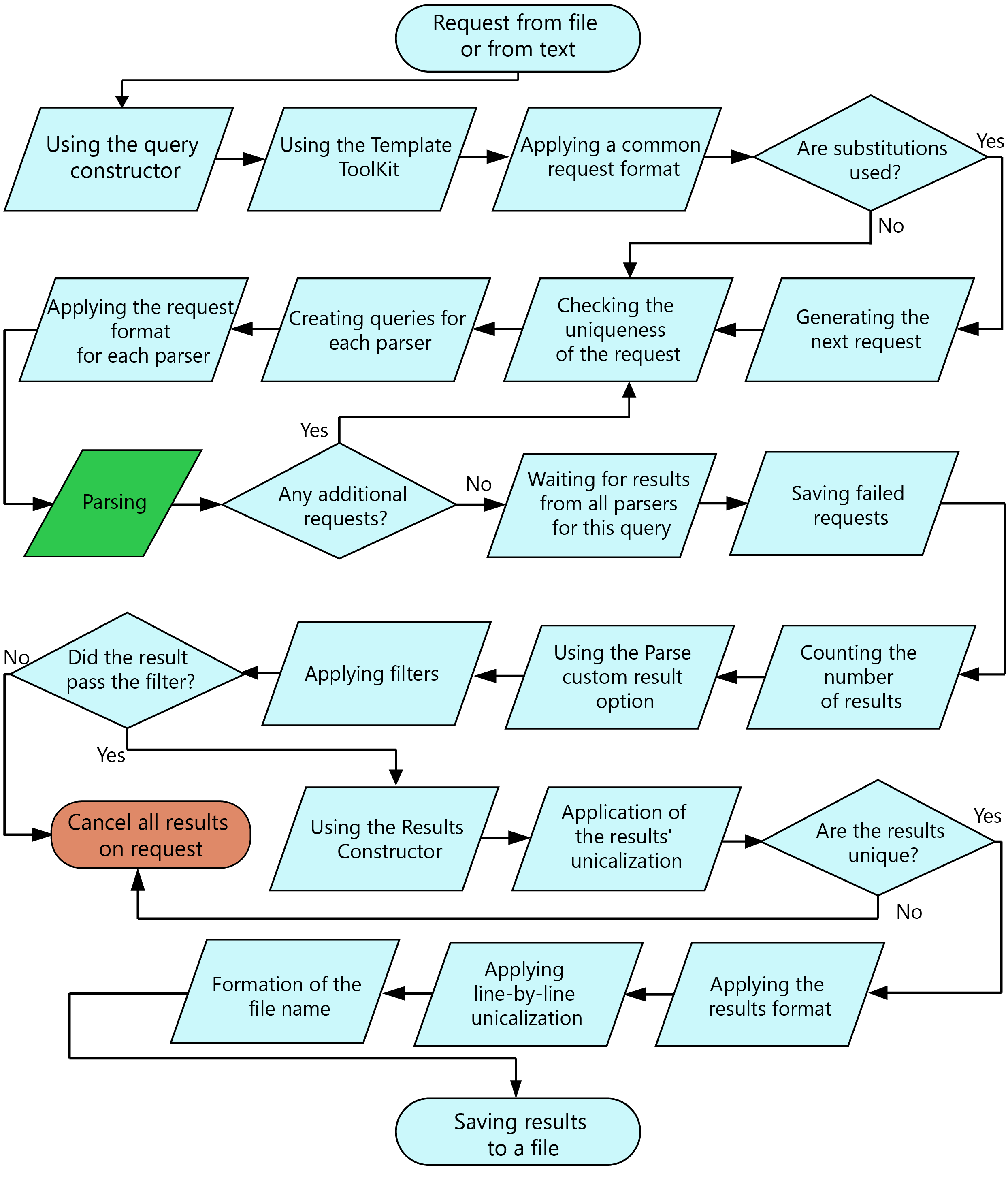
Opmerkingen
- Bij het filteren en de deduplicatie van resultaten worden de query en de resultaten ervan volledig geannuleerd als een eenvoudig resultaat wordt gebruikt voor vergelijking; als een array wordt gebruikt voor vergelijking, worden elementen uit die array verwijderd.
- Veel stappen in het diagram zijn optioneel en hangen af van de instellingen die zijn opgegeven in de Task Editor.
- Extra queries kunnen ontstaan bij het gebruik van de opties Parse all result en Parse to level. Alle extra queries hebben een volgend niveau ten opzichte van de query waaruit de extra queries zijn gemaakt; de niveau-telling begint bij nul, d.w.z. de oorspronkelijke queries uit een bestand of tekst hebben altijd niveau 0. Queries na het toepassen van query-substituties hebben ook niveau 0.
Mislukte queries
Een query wordt als mislukt beschouwd en overgeslagen als deze niet binnen het opgegeven aantal pogingen kon worden uitgevoerd.
Hoe bepaal je waarom een query is mislukt? Schakel logging in of start een Task Test. Alle fouten worden gelogd. Door het logboek te bestuderen, kun je begrijpen wat er mis is gegaan.
Voorbeeld van een mislukte query. De logs geven aan dat de query niet kon worden uitgevoerd vanwege een captcha en dat de pogingen zijn opgebruikt. In dit geval kan het helpen om een oplosservice aan te sluiten of het aantal pogingen te verhogen (alleen als je met proxy's scrapet, anders heeft het verhogen van het aantal pogingen geen zin).
Hoe verhoog je het aantal pogingen? Je moet de optie Request retries overschrijven en een hogere waarde instellen.