Resultatbyggare
Result Builders (Resultatkonstruktör) - gör det möjligt att omvandla resultat från varje scraper innan de formateras och sparas till disk
Möjligheter
- Uppdelning av resultatet i delar med hjälp av reguljära uttryck eller med en valfri separator
- Ersättning av delsträng i resultatet eller ersättning med reguljära uttryck
- Extrahering av domän eller huvuddomän från en länk
- Omvandling av resultatet till versaler\gemener
- Borttagning av HTML-taggar (
<b>text</b>->text) - Konvertering av HTML-entiteter till deras Unicode-motsvarigheter (
©->©) - Hämtning av data med hjälp av XPath-frågor
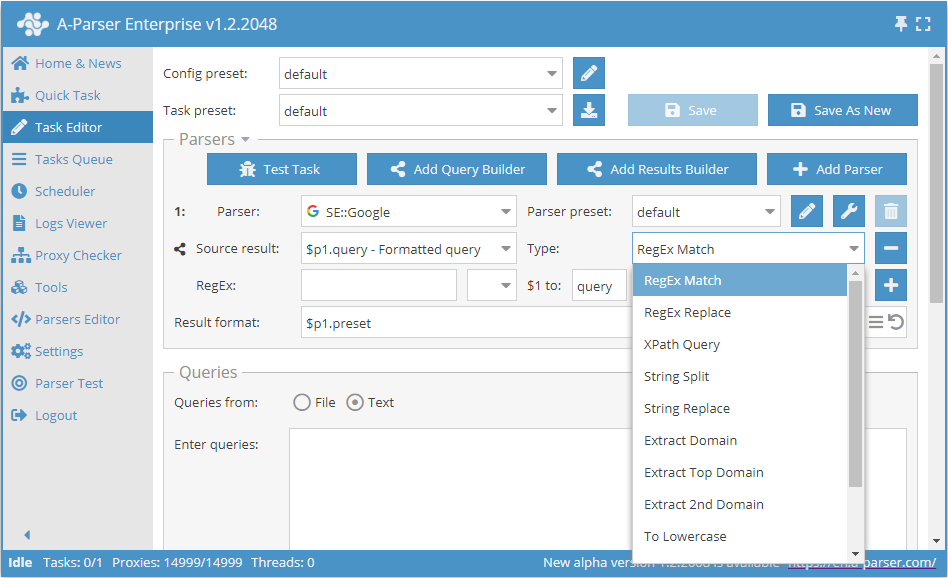
Exempel
Dataskrapning av domäner
Spara endast domäner vid dataskrapning av länkar från sökmotorer:
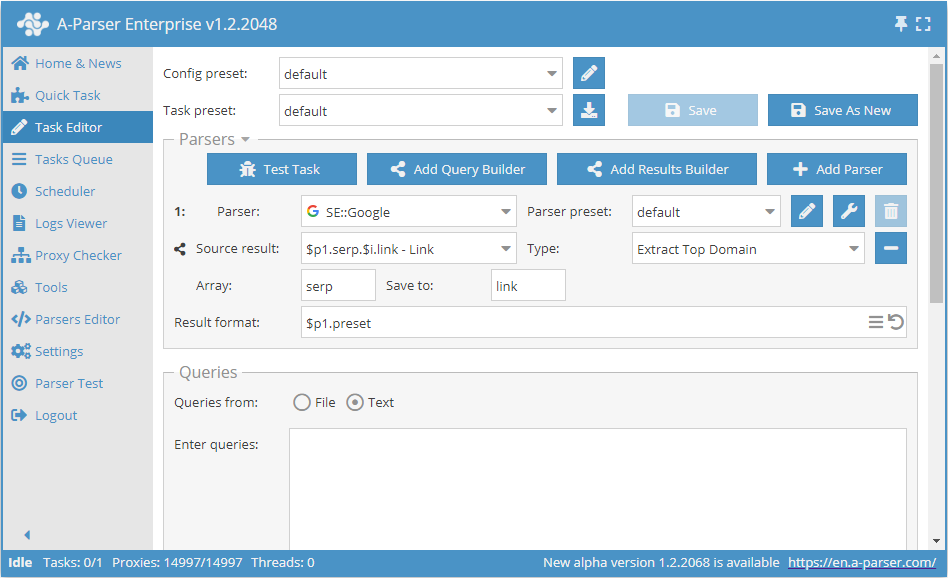
Som källa används elementen link från arrayen serp från den första scrapern, på varje element kommer funktionen för att extrahera huvuddomänen från länken att tillämpas, det nya resultatet kommer att sparas under samma namn (elementet link i arrayen serp) - därför behöver inte resultatformatet ändras
Dataskrapning av snippets med rensning
Spara snippets från sökmotorer med rensning av HTML-taggar och konvertering av HTML-entiteter
Som standard skrapas ankare och snippets med alla inbäddade taggar, vilket gör det möjligt att behålla samma formatering som när man tittar på sökresultaten från sökmotorer. Om endast ren text behövs kan man använda möjligheterna i Resultatkonstruktören:
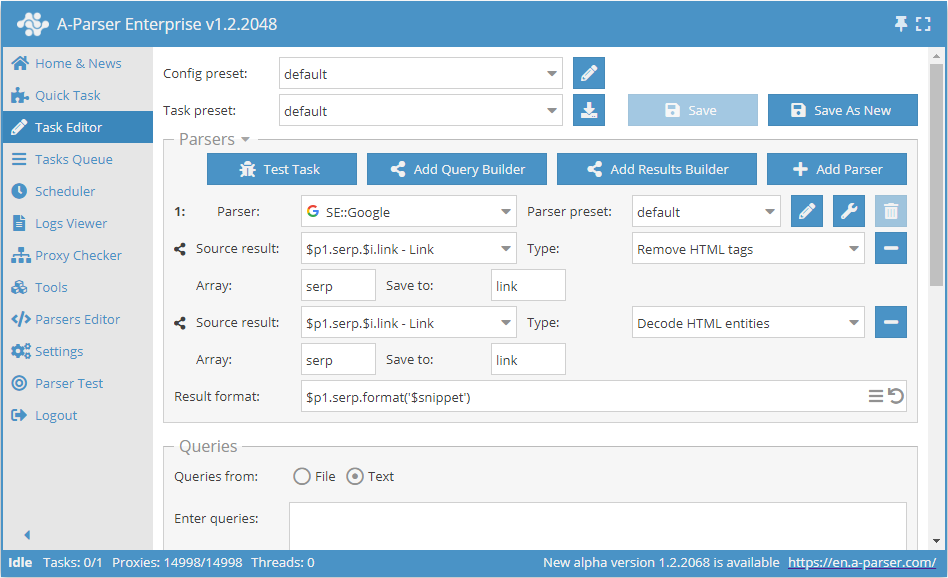
I detta exempel har två Resultatkonstruktörer tillämpats sekventiellt på snippets - borttagning av HTML-taggar och konvertering av HTML-entiteter
Dataskrapning med hjälp av XPath
Dataskrapning av länkar från sökresultat med hjälp av XPath:
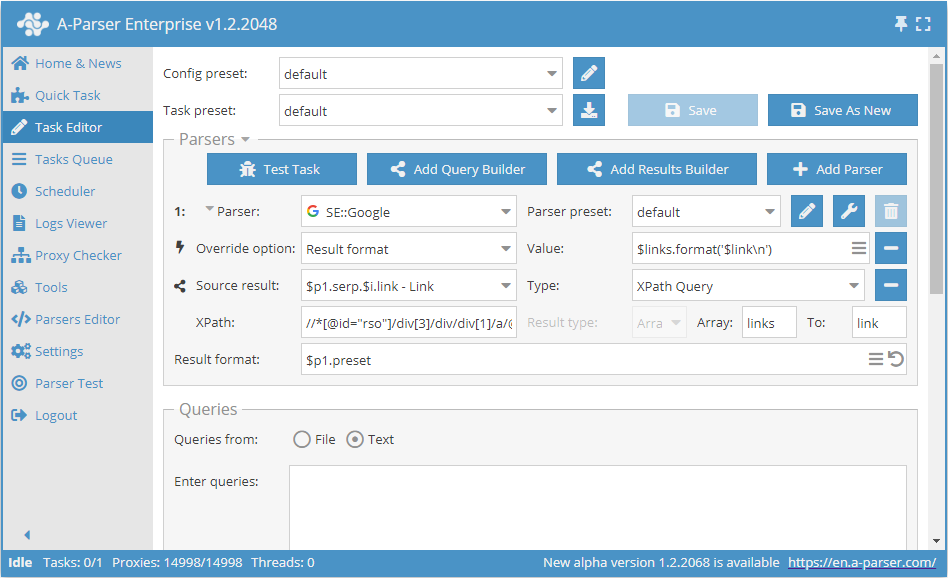
I detta exempel visas dataskrapning av länkar från sökmotorn Google. XPath-frågan som används är:
//*[@id="rso"]/div[3]/div/div[1]/a/@href