結果コンストラクター
Result Builders (結果ビルダー) - 各スクレイパーからの結果をフォーマットしてディスクに保存する前に変換することができます
機能
- 正規表現または任意の区切り文字を使用した結果の分割
- 結果内の部分文字列の置換、または正規表現による置換
- リンクからのドメインまたはメインドメインの抽出
- 結果の大文字・小文字への変換
- HTMLタグの削除 (
<b>text</b>->text) - HTMLエンティティのUnicodeへの変換 (
©->©) - XPathクエリを使用したデータの取得
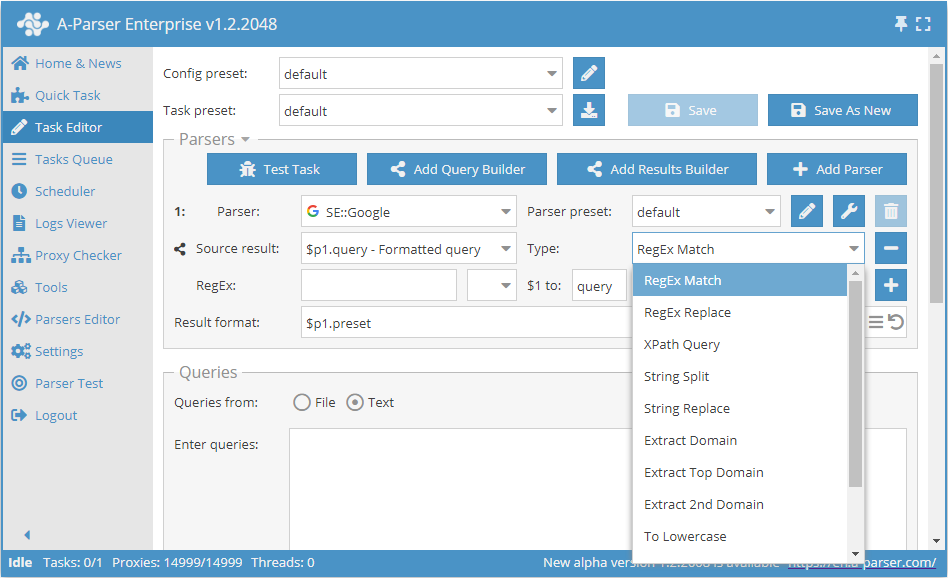
例
ドメインのスクレイピング
検索エンジンからリンクをスクレイピングする際に、ドメインのみを保存する:
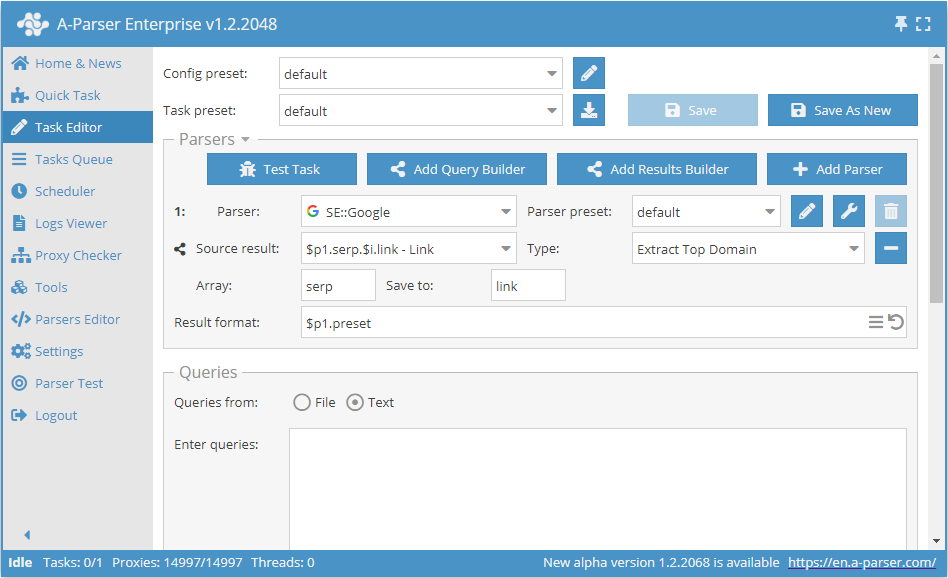
ソースとして、最初のスクレイパーのserp配列内のlink要素が使用されます。各要素にリンクからメインドメインを抽出する関数が適用され、新しい結果は同じ名前(serp配列内のlink要素)で保存されるため、結果フォーマットを変更する必要はありません。
クリーニングを伴うスニペットのスクレイピング
HTMLタグを削除し、HTMLエンティティを変換して、検索エンジンからスニペットを保存する
デフォルトでは、アンカーとスニペットはすべてのネストされたタグを含めてスクレイピングされるため、検索エンジンの検索結果を表示する際と同じフォーマットを維持できます。プレーンテキストのみが必要な場合は、結果ビルダーの機能を利用できます:
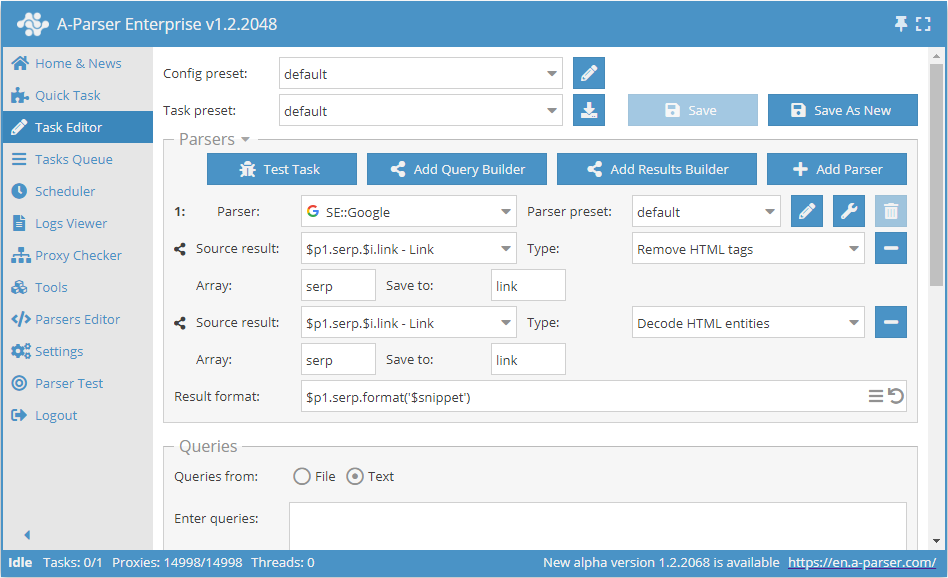
この例では、スニペットに対して「HTMLタグの削除」と「HTMLエンティティの変換」の2つの結果ビルダーが順次適用されています。
XPathを使用したスクレイピング
XPathを使用して検索結果からリンクをスクレイピングする:
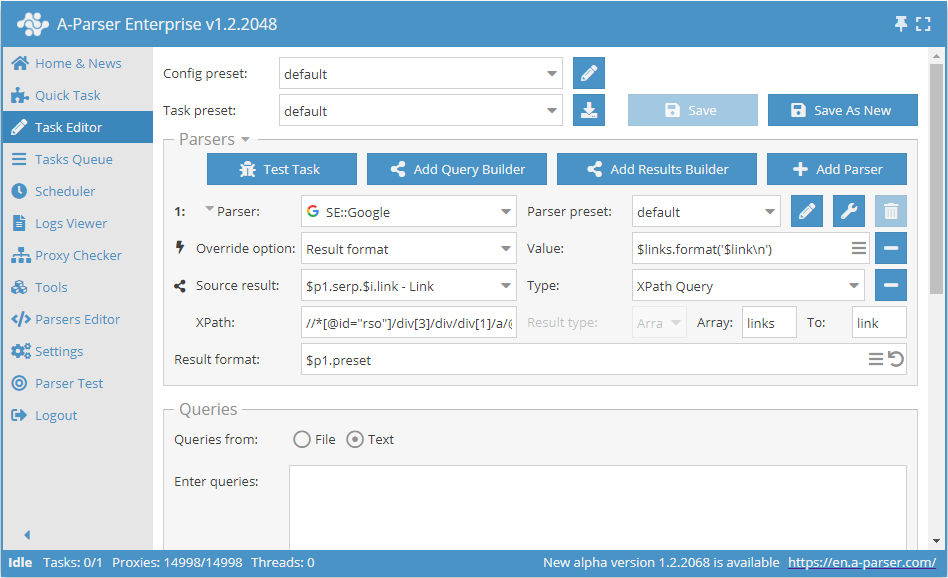
この例では、Google検索エンジンからのリンクのスクレイピングを示しています。以下のXPathクエリが使用されています:
//*[@id="rso"]/div[3]/div/div[1]/a/@href