Do czego służą aktualizacje i dlaczego są płatne?
A-Parser stale się rozwija. Wraz z wydaniem nowych wersji wprowadzane są ulepszenia i poprawki. W tym artykule przeanalizujemy, czym są aktualizacje, czym różnią się od licencji, jaką rolę odgrywają i dlaczego należy za nie płacić.
Licencja ≠ aktualizacje
Kupując A-Parser, otrzymujesz bezterminową licencję na jego użytkowanie oraz 3-6 miesięcy bezpłatnych aktualizacji w zależności od zakupionej licencji. Po zakończeniu okresu bezpłatnych aktualizacji możesz zaktualizować program do ostatniej dostępnej stabilnej wersji i nadal korzystać ze scrapera w pełnym zakresie — na tyle, na ile pozwala wersja dostępna w momencie wygaśnięcia subskrypcji.
Aby wznowić subskrypcję, możesz wykupić jeden z trzech pakietów aktualizacji: na 3 miesiące, jeden rok lub dożywotnio za odpowiednio $49, $149 i $399.
Nie musisz płacić za aktualizacje w sposób ciągły. Nie ma konieczności opłacania okresu, w którym subskrypcja na aktualizacje nie była aktywna.
Dlaczego aktualizacje są płatne?
🐞 Poprawki
Strony internetowe i różnego rodzaju zasoby rozwijają się dość szybko. Jakiekolwiek, nawet najmniejsze zmiany po stronie docelowej witryny mogą wpływać na scrapowanie. Dzieje się tak, ponieważ pierwotnie scrapery są dostosowane do określonej struktury, a zmiany w kodzie strony, zabezpieczeniach lub innych wewnętrznych mechanizmach skutkują nieprawidłowymi danymi w wynikach, ich całkowitym brakiem lub innymi błędami. Samo scrapowanie negatywnie wpływa na serwery dedykowane dla witryn: rośnie liczba zapytań, a co za tym idzie — obciążenie. Serwisy tracące zyski są zmuszone szukać wyjścia z tej sytuacji, w związku z czym pojawiają się nowe rodzaje zabezpieczeń, a stare są rozwijane.
Przy każdej takiej zmianie konieczne jest wprowadzenie poprawek. Za każdą z nich stoi analiza problemu, poszukiwanie rozwiązania i jego wdrożenie.
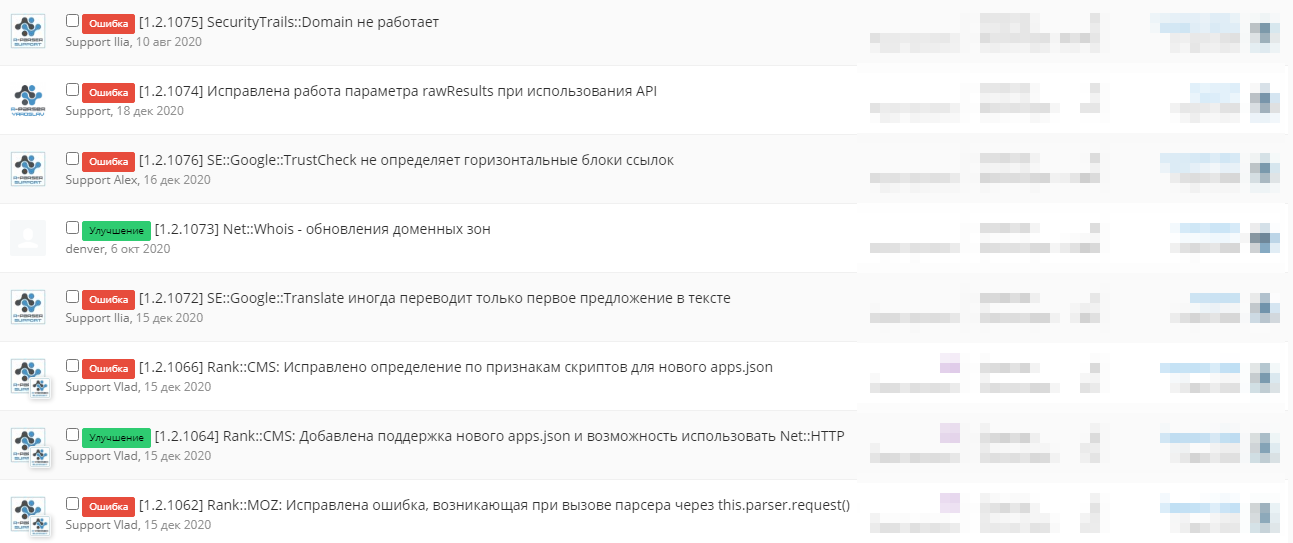
🧰 Każdego dnia każdy wbudowany scraper przechodzi system wewnętrznych testów. Jeśli zapytania testowe zakończą się sukcesem, sprawdzane są otrzymane wartości wynikowe. Nieudany test sygnalizuje błędy obecne w scraperze. Dzięki testom szybko reagujemy na awarie i natychmiast rozpoczynamy pracę nad ich naprawą.
Jednymi z najbardziej złożonych, pożądanych i dlatego priorytetowych dla nas są scrapery wyszukiwarek Yandex i Google. Każdy składa się z wielu części rozwiązujących określone zadanie. Wśród nich jest przygotowanie zapytania, formowanie nagłówków, pobieranie kodu źródłowego strony, różnego rodzaju formatowanie wyników, obsługa captcha itd. Wszystko to musi być utrzymywane w stanie sprawności. Scraper przewiduje obecność zmiennych zawierających wszystkie niezbędne dane ze strony: wyniki wyszukiwania, ogłoszenia reklamowe, powiązane słowa kluczowe i inne wartości. Są one wyciągane za pomocą wyrażeń regularnych, które zakładają obecność określonej struktury dokumentu na stronie (kolejność elementów, ich typy, klasy i inne cechy). Przy krytycznej zmianie tej struktury, wyrażenie regularne pasujące do poprzedniej wersji przestaje pobierać właściwy fragment, a scraper trafia do poprawki.
✨ Ulepszenia
Oprócz utrzymywania sprawności wbudowanych scraperów, z każdą wersją dodawane są nowe funkcje i wprowadzane różne ulepszenia, wpływające zarówno na wydajność, jak i ilość pozyskiwanych danych. Do wersji dołączane są nowe scrapery, wdrażane są nowe metody w JavaScript API.
Wszystkie zmiany można zobaczyć tutaj.
Problemy związane z brakiem aktualizacji
Brak terminowych aktualizacji powoduje nieprawidłowe działanie wbudowanych scraperów. Przyczyny mogą być różne. Na przykład mogła zmienić się struktura stron. Scraper, który nie otrzymał aktualizacji, próbuje zbierać dane za pomocą starych wyrażeń regularnych, nieprzystosowanych do nowego formatu. W rezultacie pojawiają się nieudane zapytania, wyskakują różnego rodzaju błędy i brak wyników.
Na przykładzie scrapera Google
Użytkownik zwrócił się do wsparcia z następującym problemem:
Zbieram wyniki Google przy użyciu waszych proxy. Ustawiono 300 prób dla zapytania. Wszystkie zapytania kończą się niepowodzeniem. Jeszcze wczoraj wszystko działało.
Na pierwszy rzut oka wydaje się, że problem leży w proxy, ale testy z identycznymi ustawieniami i zapytaniami na najnowszej wersji przebiegają pomyślnie. Oznacza to, że problem tkwi w czymś innym. W toku rozmowy okazuje się, że użytkownik posiada przestarzałą wersję A-Parser. To właśnie jest prawdziwą przyczyną nieprawidłowego działania scrapera Google.
Na przykładzie scrapera Yandex
W Yandex zmieniła się struktura stron z captcha, przez co przestała być ona rozwiązywana. Na forum w sekcji Zadania utworzono odpowiedni wątek.
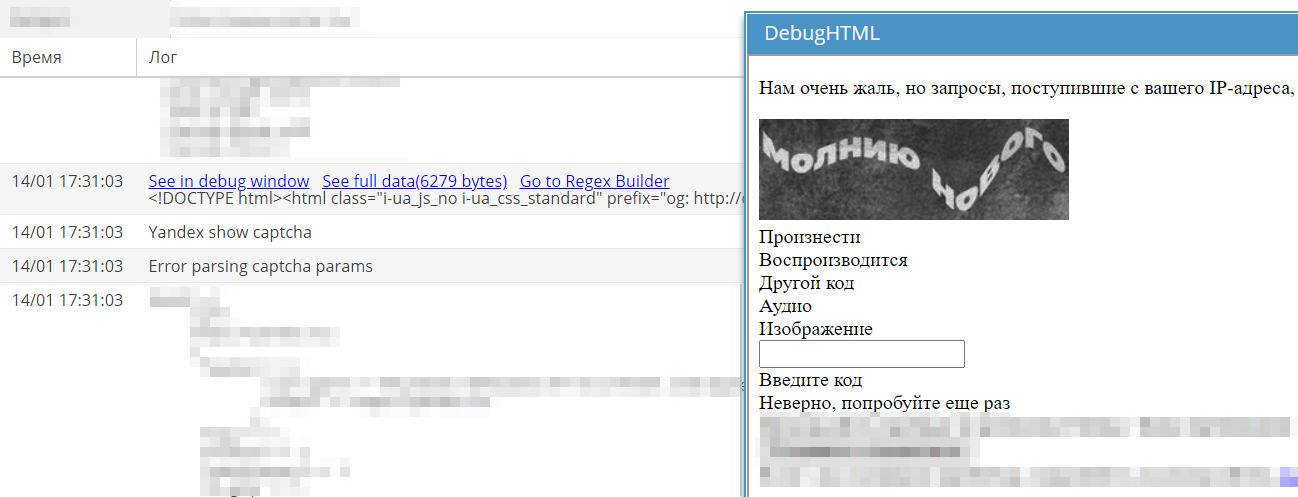
Następnego ranka wydano poprawkę. Zadanie zostało zamknięte i przeniesione do sekcji Next release. Znajdują się tam wątki dotyczące wszystkich poprawek i ulepszeń, które zostaną włączone do następnej stabilnej wersji.
W związku z tym w A-Parserze, który nie otrzymał świeżej aktualizacji, captcha w Yandex przestała być rozwiązywana.
Podsumowanie
Kupując A-Parser, otrzymujesz bezterminową licencję na użytkowanie programu oraz pakiet bezpłatnych aktualizacji na określony okres. W razie potrzeby, po upływie okresu subskrypcji, możesz ją wznowić, kupując jeden z oferowanych pakietów aktualizacji.
Strony internetowe są niestabilne – scrapery wymagają ciągłych korekt i ulepszeń. Utrzymywanie ich w stanie gotowości do pracy to nasze zadanie. Priorytetowy cel, w który wkładamy ogromny wysiłek, aby wydawać działające poprawki tak szybko, jak to możliwe. Koszt aktualizacji wynika z pracy, która za nimi stoi. Każda wersja to nie tylko lista poprawek i ulepszeń – to miesiące skoncentrowanej pracy zespołu A-Parser.